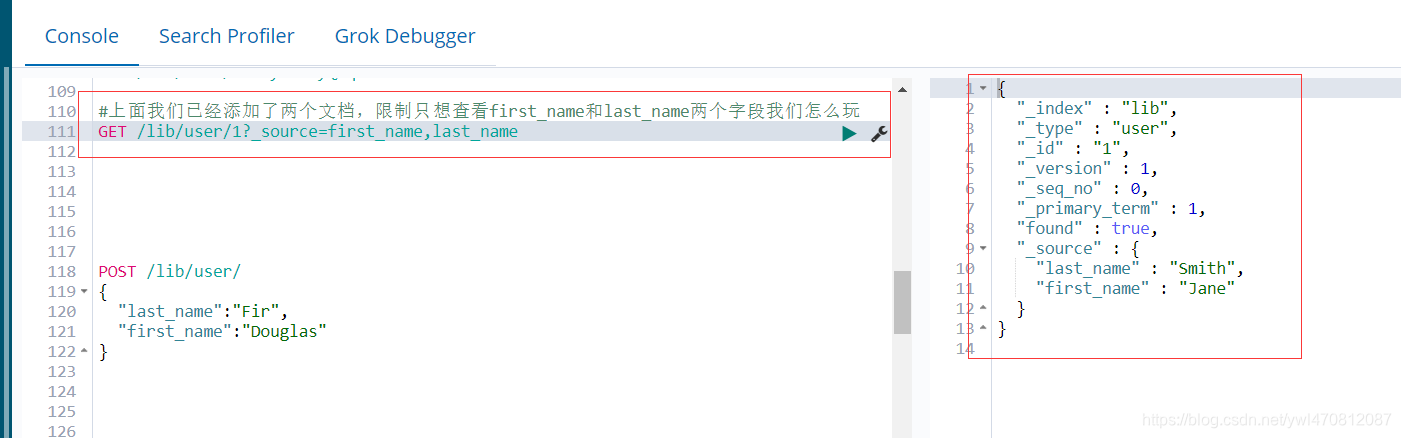
之前一直我们讲的是添加文档和查看文档,下面我们看下怎么修改文档,
第一种方式PUT 覆盖原来的文档

修改文档(覆盖原来的):
PUT /lib/user/1
{"first_name":"Jane","last_name":"Smith","age":32,"about":"I like to collect rock albums","interests":["music"]
}
返回结果
{"_index" : "lib","_type" : "user","_id" : "1","_version" : 2,"result" : "updated","_shards" : {"total" : 1,"successful" : 1,"failed" : 0},"_seq_no" : 3,"_primary_term" : 1
}
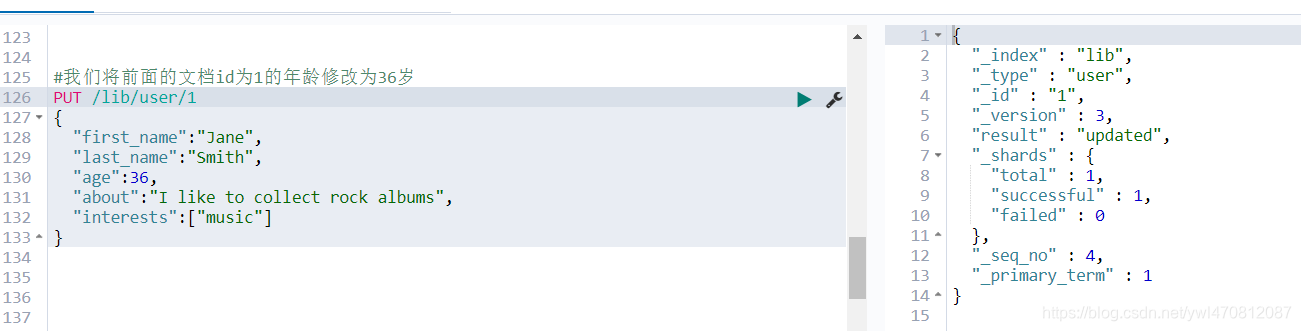
将年龄修改为36
第二种方式:POST
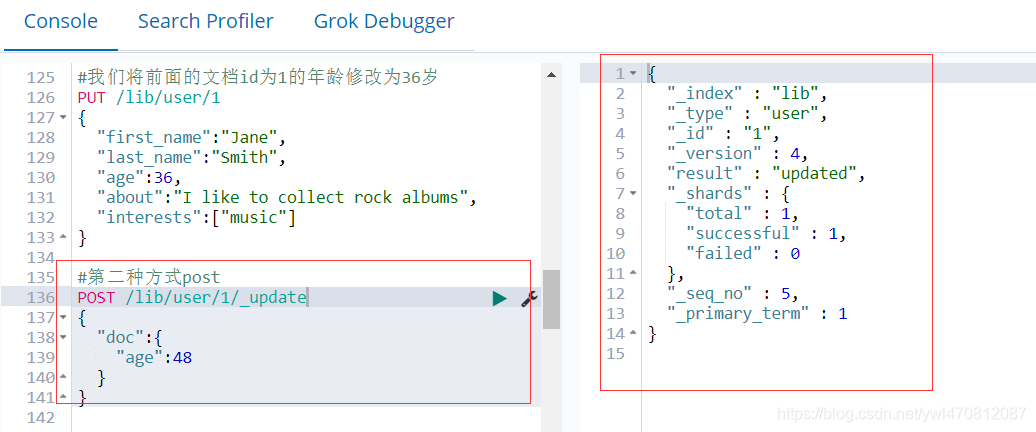
获取一下GET 年龄变成了48 版本号也增到了4
GET /lib/user/1{"_index" : "lib","_type" : "user","_id" : "1","_version" : 4,"_seq_no" : 5,"_primary_term" : 1,"found" : true,"_source" : {"first_name" : "Jane","last_name" : "Smith","age" : 48,"about" : "I like to collect rock albums","interests" : ["music"]}
}
删除文档:
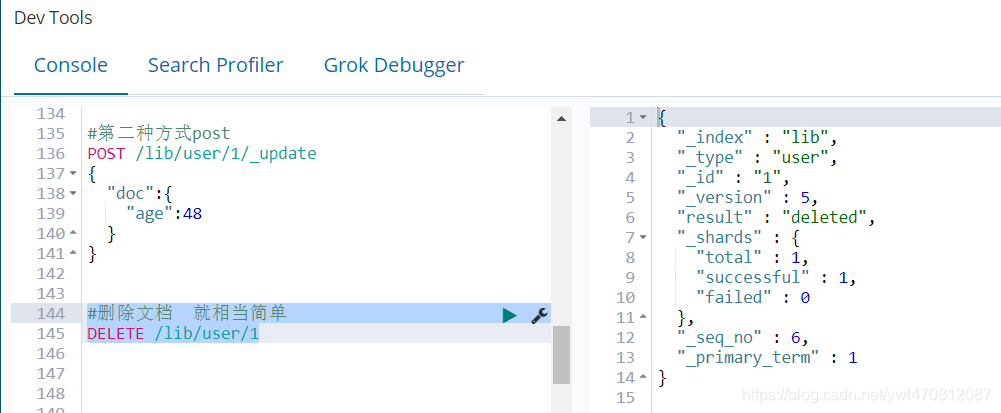
#删除文档 就相当简单
DELETE /lib/user/1
删除成功返回的信息
{"_index" : "lib","_type" : "user","_id" : "1","_version" : 5,"result" : "deleted","_shards" : {"total" : 1,"successful" : 1,"failed" : 0},"_seq_no" : 6,"_primary_term" : 1
}
我们在查看下是不是还有没有这个文档
GET /lib/user/1found为false,没有找到说明我们已经删除成功
{"_index" : "lib","_type" : "user","_id" : "1","found" : false
}
上面是删除文档删除索引呢?
PUT lib2
GET /lib2/_settings#返回索引信息
{"lib2" : {"settings" : {"index" : {"creation_date" : "1583416309156","number_of_shards" : "5","number_of_replicas" : "1","uuid" : "9Ta0EnpkQwya8BVgnzLxCQ","version" : {"created" : "6080699"},"provided_name" : "lib2"}}}
}删除索引就更简单了

GET /lib2/_settings返回信息 index没有找到,说明已经删除了
{"error" : {"root_cause" : [{"type" : "index_not_found_exception","reason" : "no such index","resource.type" : "index_or_alias","resource.id" : "lib2","index_uuid" : "_na_","index" : "lib2"}],"type" : "index_not_found_exception","reason" : "no such index","resource.type" : "index_or_alias","resource.id" : "lib2","index_uuid" : "_na_","index" : "lib2"},"status" : 404
}
)


)


)


续)



——牛顿法(多维数据))

——Negative Sampling 模型)


——Negative Sampling 模型(续))
)