三、Hierarchical Softmax模型
3.1 词向量
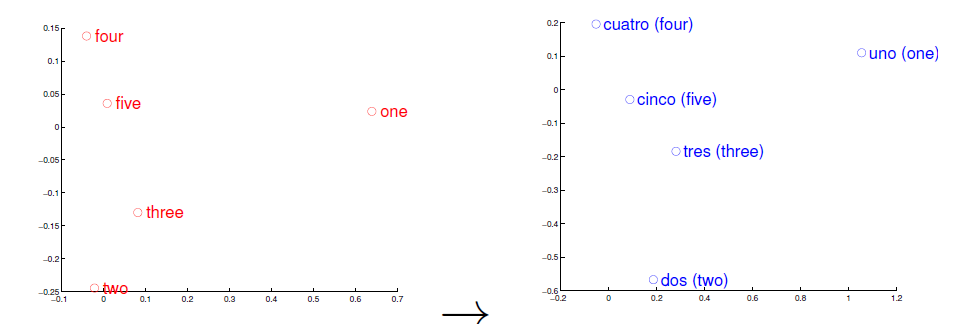
词向量目前常用的有2种表示方法,One-hot representation 和 distributed representation. 词向量,顾名思义就是将一个词表示为向量的形式,一个词,怎么可以将其表现为向量呢?最简单的就是One-hot representation,它是以词典V中的词的个数作为向量的维度,按照字典序或某种特定的顺序将V排序后,词w的向量可以表示为: [0,0,1,0,0,…,0],即词w出现的位置为1,其余均为0. 可以看到,这种方法表示的词向量太过于稀疏,维度太高,会引起维度灾难,而且非常不利于计算词之间的相似度。另一种distributed representation可以解决上述问题,它通过训练将一个词映射为相对于One-hot representation来说一个比较短的向量,它的表示形式类似于:[0.1,0.34,0.673,0.983]。词向量就是将词映射到词典空间中,如下图所示的词向量是两种不同的语言映射。
3.2 CBOW模型和Skip-Gram模型
CBOW模型很像 feedforward NNLM(A Neural Probabilistic Language Model),feedforward NNLM模型如下所示:
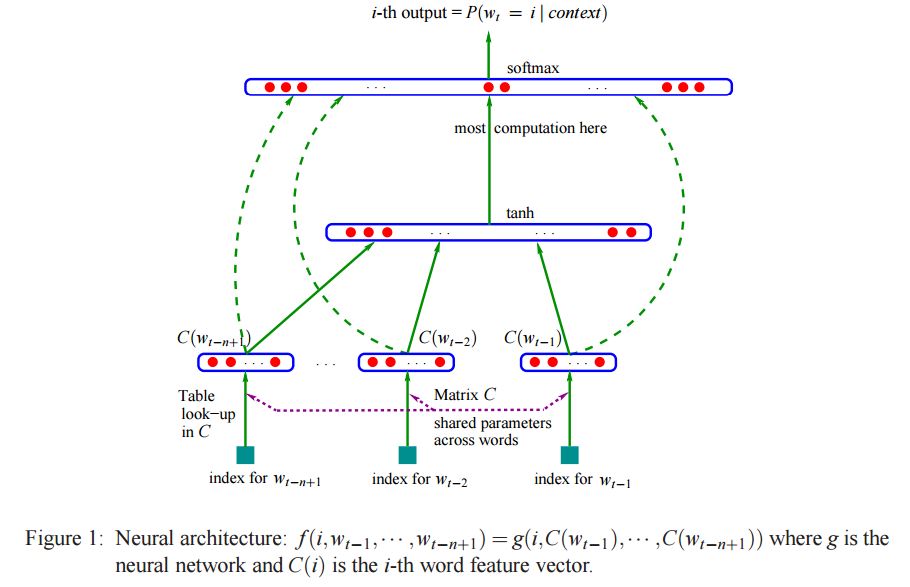
其中C是一个词向量矩阵,首先,将词wi的词向量从C中取出,并且首尾相接组成x作为神经网络的第一层输入层,第二层为隐藏层,通过 d+Hx 计算得到。d 是一个偏置项。在此之后,使用
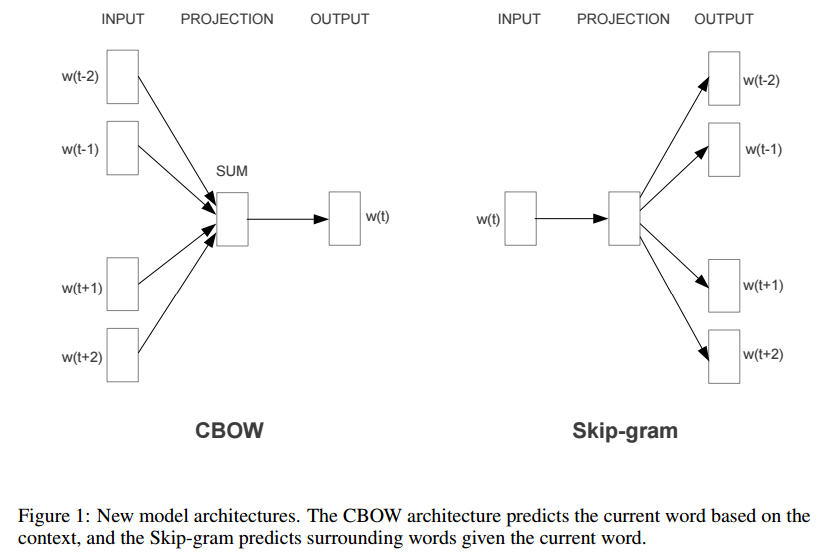
CBOW将隐藏层移除,投影层不再是词向量的拼接,而是各个词向量相加后取平均作为输入,由上图可以看到,NNLM模型大部分的计算量在输出层上的softmax归一化运算,因此,CBOW为了简化模型,在输出层输出huffman树。CBOW模型根据上下文预测当前词。Skip-gram模型是用每个当前词去预测一定范围内除当前词之外前后的词。并不是有些人说的CBOW的相反版本。论文关于这一点的原文是:we use each current word as an input to a log-linear classifier with continuous projection layer, and predict words within a certain range before and after the current word. 参考 http://arxiv.org/pdf/1301.3781v3.pdf
3.3 CBOW模型的推导
由于模型的输出是一颗huffman树,其中树的叶子节点表示词,根节点表示权值。CBOW的核心内容是推导出p(w|context(w)),其中,context(w)由w前后各c个词组成。如下图所示:下图借用
http://blog.csdn.net/itplus/article/details/37969979
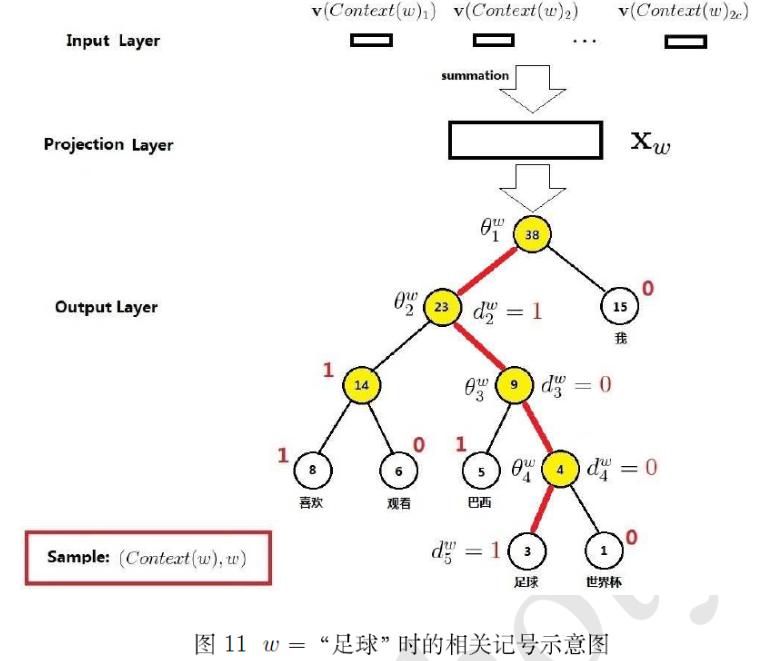
- 由输入层context(w)得到投影层向量Xw:
Xw=∑i=12cV(context(w)i)
以上V(context(w)i)初始化为[−0.5M,0.5M],M为向量的维数。 - 由huffman树的根节点到叶节点,是多个二分类问题。二分类问题一般用logistic回归解决,给出回归函数:
σ(zi)=11+e−zi,其中,z=XTwθ,则p(dwi|XTw;θi−1)=1−σ(z),d=1p(dwi|XTw;θi−1)=σ(z),d=0 - 由以上huffman树的图可知:
p(w|context(w))=∏i=2lwp(dwi|Xw;θi−1)=∏i=2lw[σ(zi−1)1−dwi(1−σ(zi−1))dwi] - 语言模型的目标函数是取如下最大似然函数
L=∑w∈Clogp(w|context(w))=∑w∈Clog∏i=2lw[σ(zi−1)1−dwi(1−σ(zi−1))di]=∑w∈C∑i=2lw[(1−dwi)logσ(zi−1)+dwilog(1−σ(zi−1))]
记以下函数为:
L(w,i)=(1−dwi)logσ(zi−1)+dwilog(1−σ(zi−1))
将z_i代入得:
L(w,i)=(1−dwi)logσ(XTwθi−1)+dwilog(1−σ(XTwθi−1) - 求函数L(w,i)对w和
θi−1 求偏导数:
∂L(w,i)∂Xw=(1−dwi−11+e−XTwθi−1)θi−1∂L(w,i)∂θi−1=(1−dwi−11+e−XTwθi−1)XTw - 那么,参数θi−1的更新公式如下所示:
θi−1:=θi−1+η(1−dwi−11+e−XTwθi−1)XTw
我们的目的是求每个词的词向量,那么,给出词向量的更新公式:对于每个w∈context(w),都有:
v(w):=v(w)+η∑i=2lw(1−dwi−11+e−XTwθi−1)θi−1


续)



——牛顿法(多维数据))

——Negative Sampling 模型)


——Negative Sampling 模型(续))
)

——逻辑回归)




——牛顿法性质分析)