
链接:https://arxiv.org/pdf/1707.01476.pdf
本文主要关注 KG Link prediction 问题,提出了一种多层卷积神经网络模型 ConvE,主要优点就是参数利用率高(相同表现下参数是 DistMult 的8分之一,R-GCN 的 17 分之一),擅长学习有复杂结构的 KG,并利用 1-N scoring 来加速训练和极大加速测试过程。
Background
一个 KG 可以用一个集合的三元组表示 G={(s,r,o)},而 link prediction 的任务是学习一个scoring function \psi(x),即给定一个三元组 x=(s,r,o) ,它的 score \psi(x) 正于与x是真的的可能性。
Model ConvE

这是 ConvE 的整体结构,把输入的实体关系二元组的 embedding reshape 成一个矩阵,并将其看成是一个 image 用卷积核提取特征,这个模型最耗时的部分就是卷积计算部分,为了加快 feed-forward 速度,作者在最后把二元组的特征与 KG 中所有实体的 embedding 进行点积,同时计算 N 个三元组的 score(即1-N scoring),这样可以极大地减少计算时间,实验结果显示,KG 中的实体个数从 100k 增加到 1000k,计算时间也只是增加了 25%。
ConvE 的 scoring function
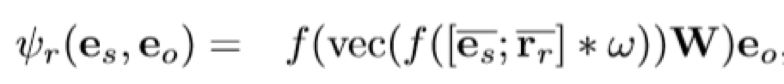
Loss function 就是一个经典的cross entropy loss
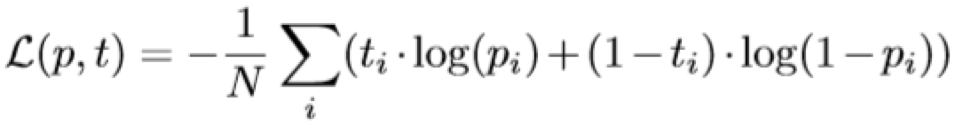
Test Set Leakage Problem
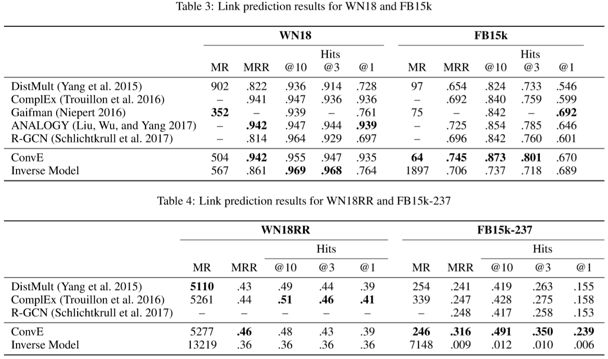
WN18 和 FB15k 都有严重的 test set leakage problem,即测试集中的三元组可以通过翻转训练集中的三元组得到,举个例子,测试集中有(feline,hyponym, cat)而训练集中有 (cat,hypernym, feline),这个问题的存在导致用一个很简单的 rule-based 模型就可以在某些数据集上实现 state-of-the-art 性能。作者构造了一个简单的 rule-based inverse model 来衡量这个问题的严重性,并利用消去了 inverse relation 的数据集 WN18RR 和 FB15k-237 来进行实验,实验结果如下
论文笔记整理:汪寒,浙江大学硕士,研究方向为知识图谱,自然语言处理。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。







)





)



:Kafka的原理、基础架构、以及使用场景)

