
Yuyu Zhang, Hanjun Dai, Zornitsa Kozareva, Alexander J.Smola, and Le Song: Variational Reasoning for Question Answering with KnowledgeGraph. AAAI 2018
链接:https://arxiv.org/abs/1709.04071
本文提出了一个可端到端训练的 KBQA 框架,可以在模型内部完成实体链接,并且在找到用户 query 的 topic entity 后,可以通过变分推断完成多跳推理,找到答案。本文的框架将实体链接得到的实体 y 看做是隐变量,通过求解包含隐变量的极大似然函数得到模型参数。

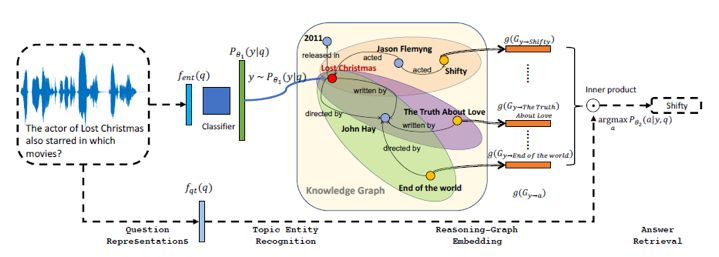
具体而言,第一步,给定用户 query,计算出知识库中每个实体可能是 topic entity 的概率。 做法是用一个神经网络得到 query 的向量表示,然后做 softmax 多分类即可。由于这里并没有使用传统的类似于字符串匹配的方式做实体链接,因此用户 query 的形式比较自由,可以使文本的,也可以是语音的。

第二步,给定了问题和一个链接到的实体 y,要找到在 y 的邻域 (T 跳之内,T 是一个超参数,文中为3)内每个实体可能是 query 答案的概率。文中的做法是给从y到a的所有路径构成的子图 G_(y→a) 训练一个向量表示 g(G_(y→a)),那么如果给从y到其邻域内的每个实体的路径都训练了一个向量表示,就可以用如下方式计算出所有实体可能是答案的概率。
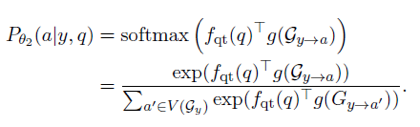
如何计算 g(G_(y→a)) 是本文中体现出推理的地方。本文计算路径的向量表示采用了传播式的方法,即假设 b 是从 y 到 a 的路径上 a 的所有父节点的集合,那么计算 g(G_(y→a)),只需要利用到所有的 g(G_(y→b) ) 即可。
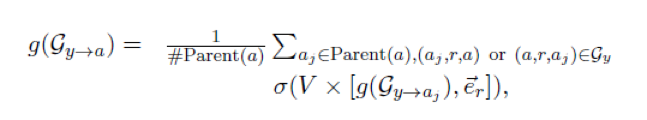
以上虽然解决了极大似然函数 p_θ1(y|q_i) 中和 p_θ2(a_i |y,q_i) 的求解问题,但是如果要优化这个包含隐变量的极大似然函数,由于后验概率 p(y|q_i,a_i) 无法求解,因此无法直接使用EM算法。故本文采用变分推断的方法,由神经网络训练出另一个分布 Q_φ(y│q_i,a_i) 来近似代替。由于计算 Q_φ(y│q_i,a_i) 和计算p_θ2 (a_i |y,q_i) 的过程刚好相反,因此可以同样使用前面传播式的方法计算 g(G_(a→y)),只是方向相反。
本文框架的总体结构为:
最后,本文采用了 REINFORCE 算法来求解参数,具体而言,是用变分推断近似替代后的新的损失函数为
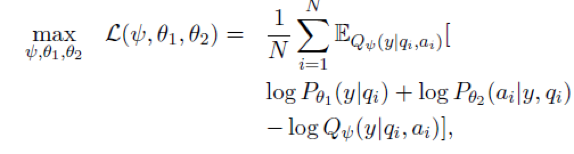
求梯度得到
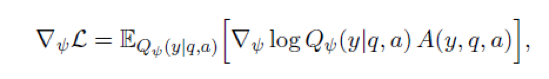
然后迭代至收敛即可。
实验结果:在本文新发布的 KBQA 数据集 Meta QA 上相比对照模型提升较为明显,尤其是要求多跳推理的问题。另外,在问题的形式是语音,机器翻译后的结果,以及训练时不给定标注好的 topic entity 的情况下, 都有较大的提升。
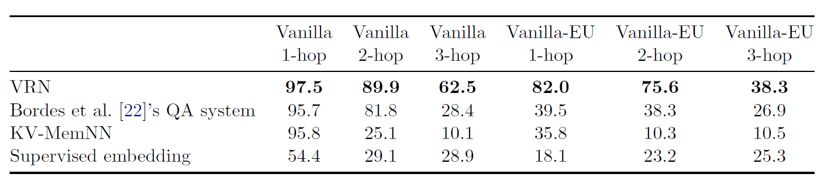
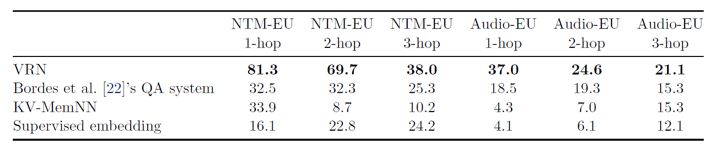
笔记整理:王梁,浙江大学硕士,研究方向为自然语言处理,知识图谱。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。



)





)



:Kafka的原理、基础架构、以及使用场景)





