本文转载自公众号:大数据创新学习中心。
3月10日下午,复旦大学知识工场联手北京理工大学大数据创新学习中心举办的“知识图谱前沿技术课程暨学术研讨会”上,OpenKG联合发起⼈、海知智能CTO丁力博士分享了以“cnSchema:中⽂知识图谱的普通话”为主题展开报告,主要介绍了面向中文信息处理的cnSchema.org,特别介绍了其核心本体设计以及其在知识图谱驱动的智能问答与智能分析中的应用案例。


首先,丁博士介绍了中文开放知识图谱(简称 OpenKG.CN)和cnSchema。
OpenKG.CN旨在促进中⽂知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和⼴泛应⽤。目前已与多个高校、机构、企业等联盟合作,开展活动和业务。
cnSchema.org,作为OpenKG社区的Schema规范,面向中文信息处理,支持快速领域知识建模,支持跨数据源、跨领域、跨语言的开放数据自动化处理,提供schema层面的支持与服务。



紧接着,丁博士简要介绍了知识图谱的基础与发展历程:
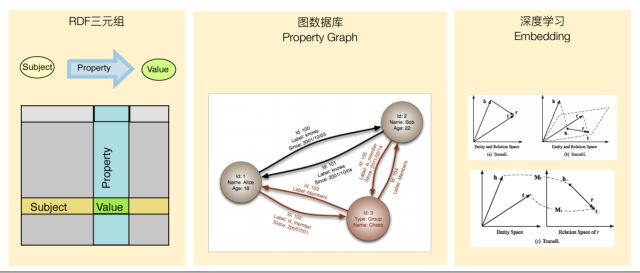
1. 知识图谱中常见的知识表示方法:RDF三元组、图数据库、深度学习
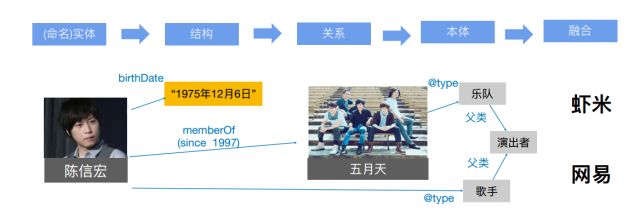
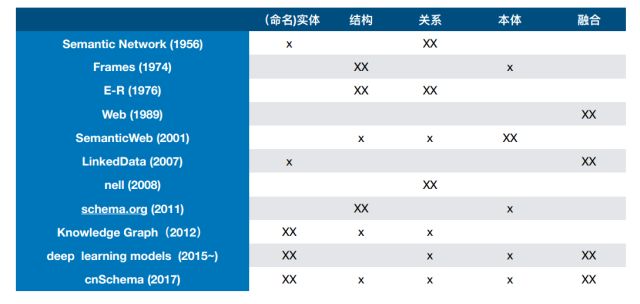
2. 知识图谱的五个层次:实体 -> 结构 -> 关系 -> 本体 -> 融合
3. 知识图谱大事记
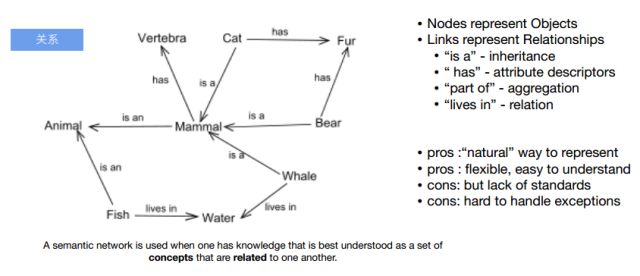
(1)Semantic Network (1956)
以节点表示实体,链表示关系。
优点:表示方式“自然”、灵活且易于理解。
缺点:缺乏标准,难以实现未知语言现象的处理。
(2)The Web (1989)
The Web作为一个信息空间,其目标不仅有助于人际沟通,还能使机器参与进来并提供帮助。

(3)The Semantic Web (2001)
提出三个设想:
①在网络上发布结构化数据;
②用本体实现共同理解;
③使用可用数据实现智能又酷炫的应用。

4、Linked Open Government Data (2010)
与政府的政治、经济、健康等多方面数据挂钩。
(5)Journey to Web Schema,Schema.org(2011)
网络Schema由标准第一(1996年起)过渡到数据第一(2004年起)再发展为用户第一(2008年起)。
2011年出现了schema.org。

知识图谱境界变迁的总结:
在简要介绍了知识图谱的一些基础知识和重要发展历程之后,丁博士为我们详细讲解了cnSchema。
1. cnSchema生态
2. cnSchema 核⼼本体设计

3. cnSchema实体定义更加明确

4. 基于cnSchema的KBQA
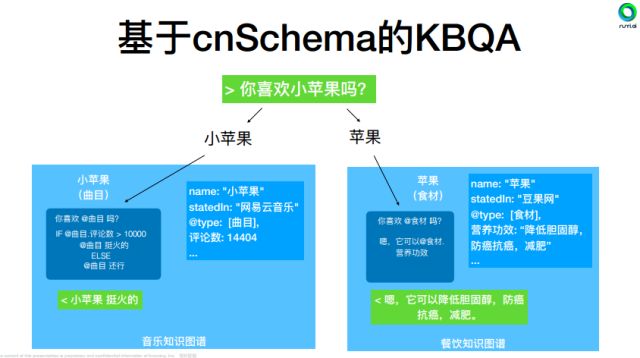
接下来,丁博士为我们详细分析了cnSchema在知识图谱驱动的智能问答与智能分析中的应用案例。目前cnSchema在智能家居、智能客服和企业内部的智能化等领域已形成了AI应用落地成果。
领域知识图谱构建的关键方法和技术包括:领域词汇抽取,实体识别,实体分类;领域知识抽取:抽取关系、抽取事件、抽取深层次结构;语义关联,搜索、匹配与排序;基于active learning技术,提升标注效率:基于领域语料的NLP技术。
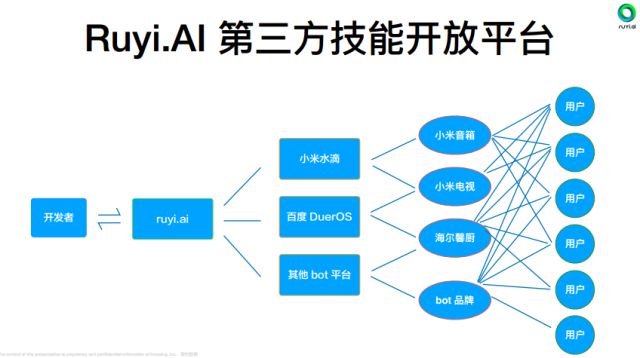
1. 智能机器人(Bots)
Bots是基于Ruyi.AI第三方技能开方平台的搜索引擎后新兴的人机接口,对话中的信息粒度缩小到短文本、实体和关系,而且多轮对话还要求更丰富的上下文知识。cnSchema是中文知识图谱接口的关键,schema自身对接中文自然语言处理以及针对中文信息中特有概念的处理都需要其支持。

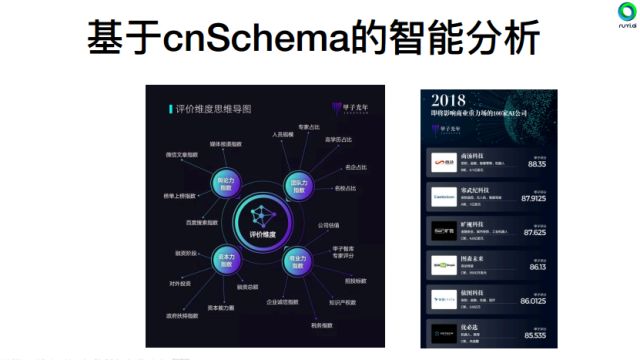
2. 基于cnSchema的智能分析
以甲子光年的AI公司评价体系为例,利用NLP分类器,对AI公司数据进行清洗与筛选;使用基于深度学习的神经网络算法构建learning to rank模型,在舆论力指数、团队力指数、商业力指数、资本力指数四个大的评价维度下,划分出众多具体细化的模型参评因素,高时效性地动态评估这些发展中的AI公司。
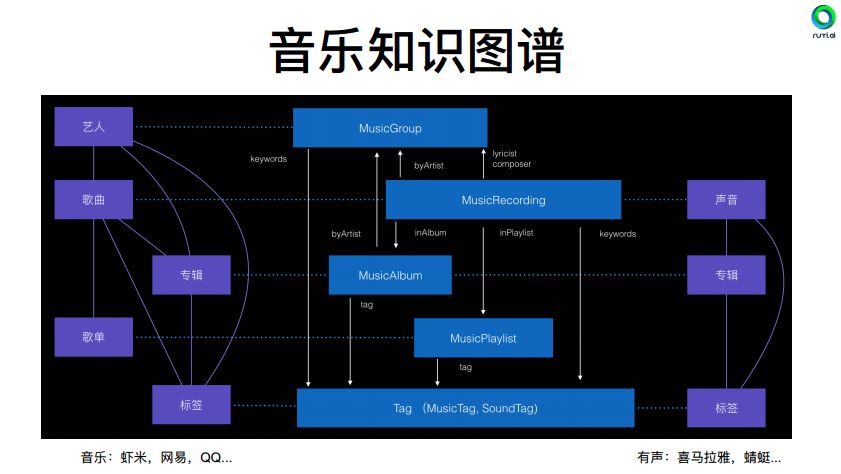
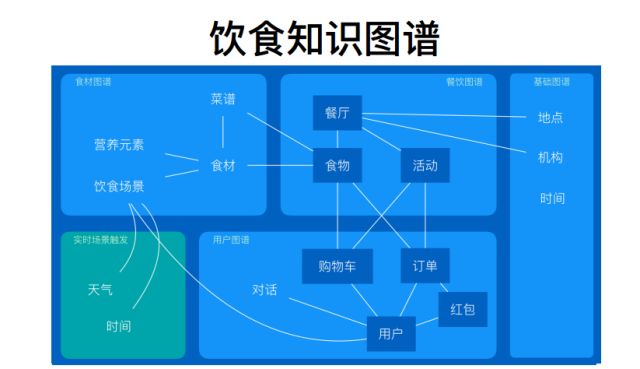
3. 基于cnSchema的领域知识图谱
目前,基于cnSchema的领域知识图谱涵盖了音乐、工商、医院、新闻、履历和饮食等多个领域。如音乐和饮食知识图谱,图中介绍了知识图谱的模块划分和关联。

最后,丁力博士表示cnschema是开放的中文知识图谱schema,致力通过最佳实践帮助垂直领域合作者扩展领域知识图谱,以支持数据发布和应用,支持大家快速实现应用落地。

大数据创新学习中心
让学习成为一种乐趣
长按扫码关注我们

OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。








)





、bag of word(词袋)、word-Embedding(词嵌入)浅析)




