
Citation: Bamler R, Mandt S. Dynamic word embeddings.InInternational Conference on Machine Learning 2017 Jul 17 (pp. 380-389).
URL:http://proceedings.mlr.press/v70/bamler17a/bamler17a.pdf
动机
语言随着时间在不断演化,词语的意思也由于文化的转变而变化。本文欲在一个时间跨度上的文本数据中,发现词语的意思和用法的变化。词嵌入模型,通过发掘词的上下文信息,将词的意思编码到向量中,本文把词嵌入模型进行推广到序列数据中(即历史文本和社交媒体上的流文本),提出了动态词嵌入模型,来挖掘单个词随着时间变化时的语义变化。
贡献
本文得出一种概率状态空间模型,使得词和其上下文词的嵌入向量都能够根据传播过程及时的发展。其泛化了skip-gram模型;动态的组织方式,使得能够进行端到端的训练,这样就可以得到连续的嵌入轨迹,而且将噪音从word-context的统计中,平滑出去,使得我们能够共享各个时间的信息。
本文还提出了两个用来过滤和平滑的黑箱可扩展推理算法。
本文还分析三个时间跨度很长的大规模文本语料,本文的方法能够自动的寻找意义变化最大的词,而且平滑的词嵌入轨迹使得我们能够评估和可视化这些动态变化,并证明本文的方法比静态的模型效果好。
模型
本文提出的 dynamic skip-gram 模型是一种结合了潜在时间序列的贝叶斯版本的 skip-gram 模型,用来发掘词嵌入向量随时间发生的改变。其中 bayesian skip-gram 模型是 dynamic skip-gram 的基础,bayesian 模型把所有的序列(句子)都认为和时间不相关,而在 dynamic 模型中,会将这些序列(句子)关联起相应的时间戳信息。最终都是计算出每个词在上下文中能够概率最大化的向量表示。
算法
本文讨论了两个可扩展的近似推理算法,Filtering:只使用过去的信息,在数据流形式的应用中,只能以这种方式进行。Smoothing:具有所有时间的文档序列,可以学习到更好的嵌入向量。
Skip-Gram Filtering:在很多应用中,数据都是流形数据,这些数据以序列的方式到达,因此,只能通过已经观测的数据序列进行建模。
Skip-Gram Smoothing:和 Filtering 的情况不同,这里的推断会基于所有时间的观测序列,而不只是对过去的观测,所以该方法拥有更平滑的轨迹和更高的概率。 由于有了所有时间的数值,变分分布就可以不在受限于时刻。通过在所有时间步上训练模型,使用黑盒变分推断和再参数化技巧,来得到所有的变分参数。
实验
本文使用了无贝叶斯估计的 skip-gram 模型(SGI),预处理初始化的 skip-gram(SGP)和 skip-gram filtering(DSG-F), skip-gram smoothing(DSG-S) 模型,进行了比对实验。以三个具有时间线的语料作为实验数据:
分别是 Google Books 语料,“State of theUnion”语料,以及 Twitter 短文。
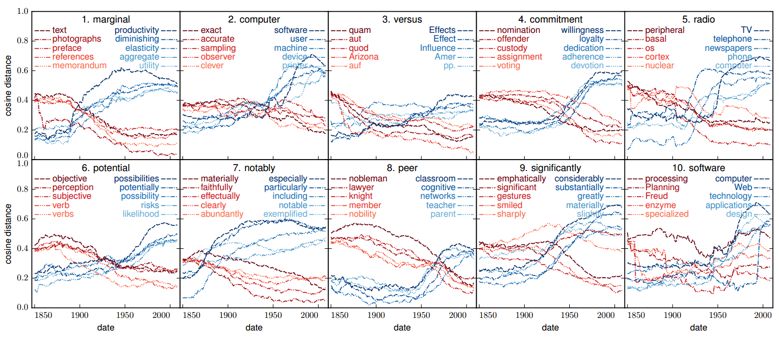
下图展示了 Google books 中,从1850到2008年中,余弦距离变化最大的10个词的演化过程。
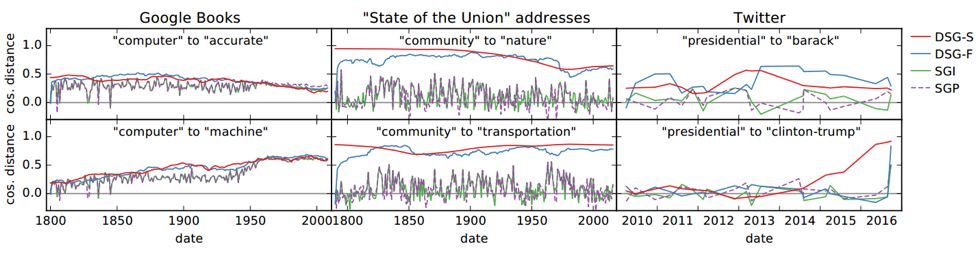
不同方法的词向量轨迹的平滑性,图中所示的是两个词的余弦距离和时间的关系图,函数值越大说明词越相似,能够直观的看出词义的演化:
本文也对模型的泛化效果进行了评估测试,证明其在未看到的数据上表现的更好,通过分析给定时刻的(中心词,上下文词)二元组的预测概率来评估:
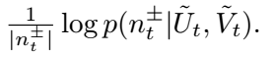
结果如下,(值越高表示效果越好):
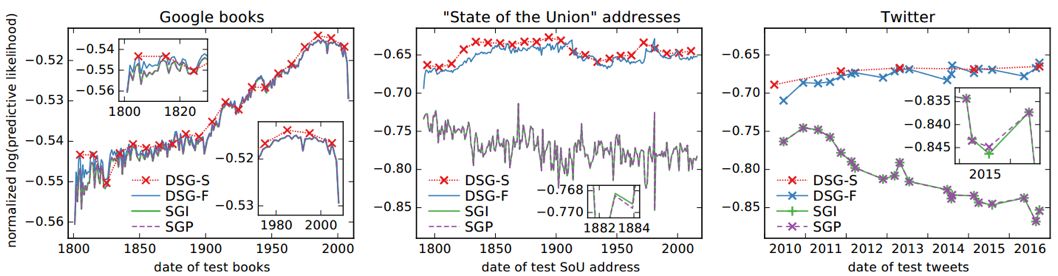
实验表明,本文的模型(dynamic skip-gram filter,dynamicskip-gram smoothing)都能够随着时间,平滑的改变嵌入向量,并且能够更好对(词,上下文)二元组有一个较好的预测效果。本文提出的方法可以对社交媒体上数据流形式的数据进行数据挖掘,异常检测,也可以供对语言演化感兴趣的历史和社会学家使用。
论文笔记整理:李林,东南大学硕士,研究方向为知识图谱构建及更新。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。




)



:Kafka的原理、基础架构、以及使用场景)









)
