使用权值衰减算法解决神经网络过拟合问题、python实现
- 一、what is 过拟合
- 二、过拟合原因
- 三、权值衰减
- 四、实验验证
- 4.1制造过拟合现象
- 4.2使用权值衰减抑制过拟合
一、what is 过拟合
过拟合指只能拟合训练数据,但不能很好拟合不包含在训练数据中的其他数据的状态。
二、过拟合原因
模型参数过多、表现力强
训练数据少
三、权值衰减
这玩意在之前提到过,就是减小权值,通过在学习过程中对大的权重进行惩罚,来抑制过拟合。
深度学习目的是减小损失函数的值,那么为损失函数加上权重平方范数,就可以抑制权重变大。
L2范数是什么,就是相当于各个元素的平方和。如下面数学式子表示。
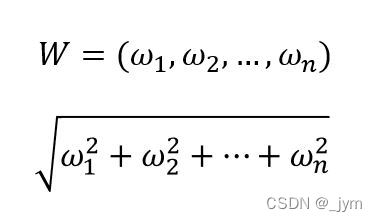
正则化是什么,regularizer,也就是规则化,也就是,向你的模型加入某些规则。为损失函数加上权重平方范数其实就是加上了正则化项,这个正则化项就是L2范数的权值衰减。
L2范数的权值衰减数学表达:

W是权重。λ是控制正则化强度的超参数,它越大,对权重施加的惩罚越多。二分之一是调整常量,这样的话,求导后是λW。
求权重的梯度的计算中,要为之前的误差反向传播法的结果加上正则化项的导数λW。
四、实验验证
4.1制造过拟合现象
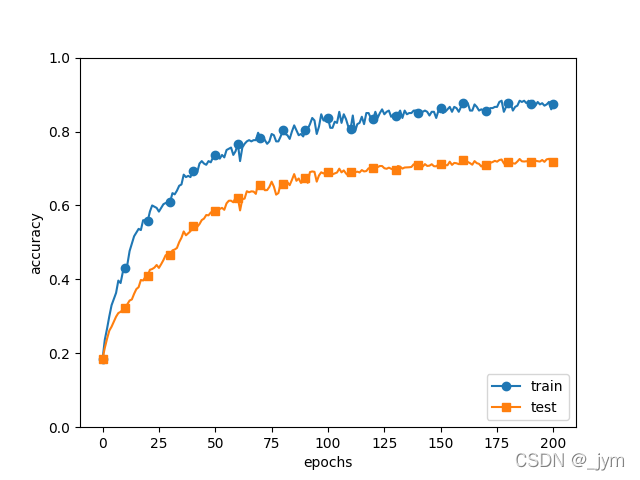
我们制造过拟合,就需要增加网络参数,减少训练数据,那么就从MNIST数据集里只选出来300个数据,然后增加网络复杂幅度用7层网络,每层100个神经元,激活函数ReLU。
代码:
import os
import syssys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net import MultiLayerNet
from common.optimizer import SGD(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)# 为了再现过拟合,减少学习数据
x_train = x_train[:300]
t_train = t_train[:300]# weight decay(权值衰减)的设定 =======================
weight_decay_lambda = 0 # 不使用权值衰减的情况
#weight_decay_lambda = 0.1
# ====================================================network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10,weight_decay_lambda=weight_decay_lambda)
optimizer = SGD(lr=0.01)max_epochs = 201
train_size = x_train.shape[0]
batch_size = 100train_loss_list = []
train_acc_list = []
test_acc_list = []iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0for i in range(1000000000):batch_mask = np.random.choice(train_size, batch_size)x_batch = x_train[batch_mask]t_batch = t_train[batch_mask]grads = network.gradient(x_batch, t_batch)optimizer.update(network.params, grads)if i % iter_per_epoch == 0:train_acc = network.accuracy(x_train, t_train)test_acc = network.accuracy(x_test, t_test)train_acc_list.append(train_acc)test_acc_list.append(test_acc)print("epoch:" + str(epoch_cnt) + ", train acc:" + str(train_acc) + ", test acc:" + str(test_acc))epoch_cnt += 1if epoch_cnt >= max_epochs:break# 3.绘制图形==========
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs)
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
由图可看出,过了100个epoch,用训练数据测得识别精度几乎为100%,但是测试数据与100%有较大差距,说明,模型对训练时没有使用的测试数据拟合的不好。
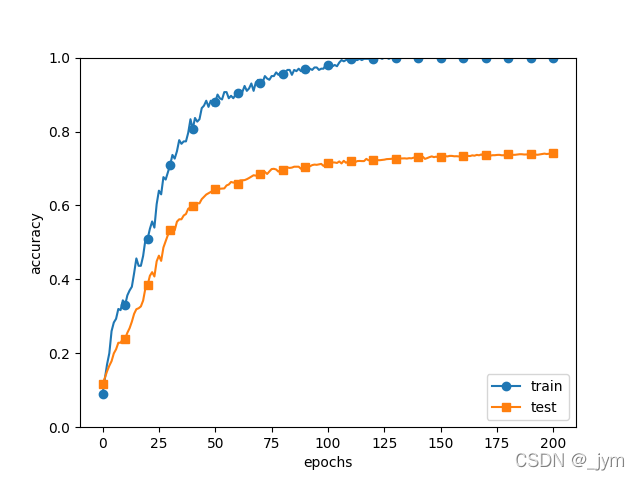
4.2使用权值衰减抑制过拟合
在上面代码中修改weight_decay_lambda = 0.1,可以看到如下结果。
测试数据和训练数据识别精度有差距,但是差距比之前的减小了。
有人说,那他的测试数据识别精度也没提升啊。
其实这是因为训练数据的精度也没到100%哦,如果再有多个训练数据进入网络训练,它精度到100%的时候,测试数据精度就会比之前过拟合时候要高。