基于深度学习的手写数字识别、python实现
- 一、what is 深度学习
- 二、加深层可以减少网络的参数数量
- 三、深度学习的手写数字识别
一、what is 深度学习
深度学习是加深了层的深度神经网络。
二、加深层可以减少网络的参数数量
加深层的网络可以用更少参数获得与没有加深层同等水平的表现力。
一次5 * 5卷积运算,可以由两次3 * 3卷积运算抵充。
前者参数数量25,后者18 。
而且,参数数量差随着层加深,变大。
叠加小型滤波器来加深网络好处是减少参数的数量,扩大receptive filed(感受野),什么是感受野,就是让神经元变化的一个局部区域。
通过叠加层,将ReLU等激活函数夹在卷积层中间,有助于提高网络表现力,因为非线性函数的叠加,可以表达更复杂的东西。
加深层,可以分层次的分解需要学习的问题,也就是说,可以将各层要学习的问题分解成简单问题。
三、深度学习的手写数字识别
网络结构:
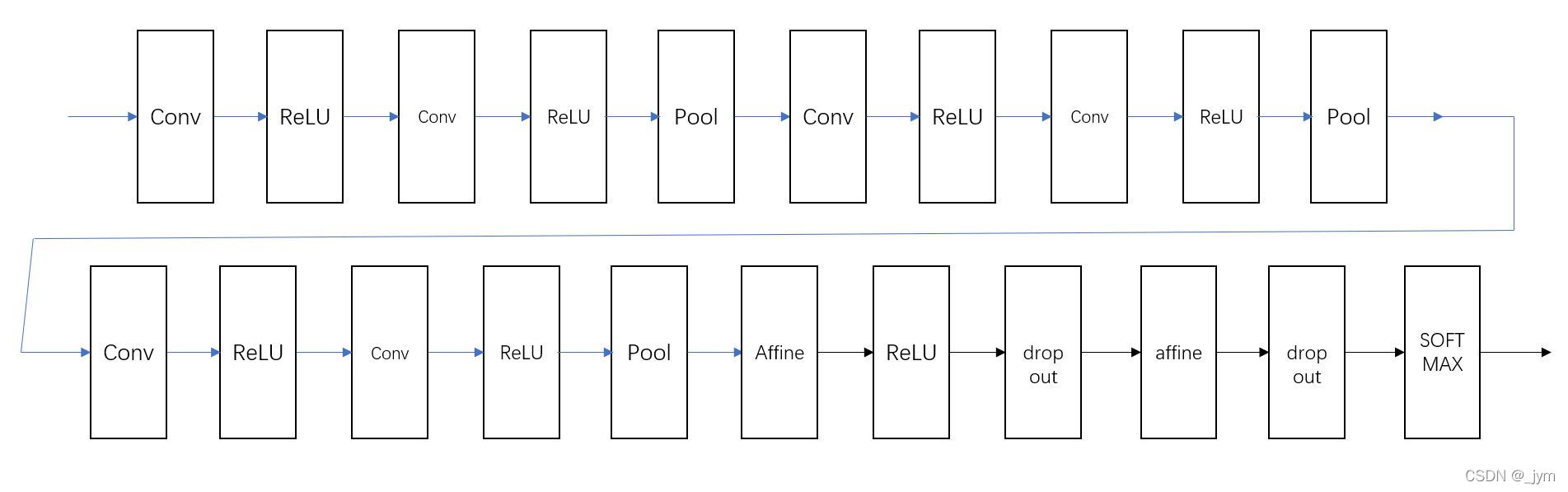
基于3*3的小型滤波器的卷积层(什么是卷积层,参考我之前写的,卷积神经网络的整体结构、卷积层、池化、python实现)
激活函数:RELU(什么是激活函数,参考我之前写的,神经网络的激活函数、并通过python实现激活函数;怎么实现激活函数层反向传播,参考我之前写的,结合反向传播算法使用python实现神经网络的ReLU、Sigmoid、Affine、Softmax-with-Loss层)
全连接层后面用Dropout层(什么是Dropout层,参考我之前写的,解决神经网络过拟合问题—Dropout方法、python实现)
基于Adam的最优化(对梯度下降的优化,参考我之前写的,神经网络的SGD、Momentum、AdaGrad、Adam最优化方法及其python实现)
使用He初始值作为权重初始值。(什么是He初始值:参考之前写的,关于神经网络权重初始值的设置的研究)
代码中gradient求梯度的,我之前都写了,(参考之前写的,梯度、梯度法、python实现神经网络的梯度计算)。
损失函数是什么,(参考之前写的,损失函数、python实现均方误差、交叉熵误差函数、mini-batch的损失函数)。
有了这个网络的代码,怎么用数据集测试,我之前都写了,(参考之前写的:基于卷积神经网络的手写数字识别、python实现;基于随机梯度下降法的手写数字识别、epoch是什么、python实现;下载MNIST数据集并使用python将数据转换成NumPy数组(源码解析);使用python对数据集进行批处理)
关于网络全过程传递表示,也就是predict函数,我之前都写了,(参考之前写的:使用python构建三层神经网络、softmax函数)
这个深度学习网络是对前面所有知识的整合。如果你从深度学习开始入门学习机器学习,那么将在一天内学成所有入门知识,我就是这么学的。
现在,才刚刚进了机器学习的大门,之前讲的所有东西,相当于幼儿园知识。
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *class DeepConvNet:"""识别率为99%以上的高精度的ConvNet网络结构如下所示conv - relu - conv- relu - pool -conv - relu - conv- relu - pool -conv - relu - conv- relu - pool -affine - relu - dropout - affine - dropout - softmax"""def __init__(self, input_dim=(1, 28, 28),conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1},conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1},conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},hidden_size=50, output_size=10):# 初始化权重===========# 各层的神经元平均与前一层的几个神经元有连接(TODO:自动计算)pre_node_nums = np.array([1*3*3, 16*3*3, 16*3*3, 32*3*3, 32*3*3, 64*3*3, 64*4*4, hidden_size])wight_init_scales = np.sqrt(2.0 / pre_node_nums) # 使用ReLU的情况下推荐的初始值self.params = {}pre_channel_num = input_dim[0]for idx, conv_param in enumerate([conv_param_1, conv_param_2, conv_param_3, conv_param_4, conv_param_5, conv_param_6]):self.params['W' + str(idx+1)] = wight_init_scales[idx] * np.random.randn(conv_param['filter_num'], pre_channel_num, conv_param['filter_size'], conv_param['filter_size'])self.params['b' + str(idx+1)] = np.zeros(conv_param['filter_num'])pre_channel_num = conv_param['filter_num']self.params['W7'] = wight_init_scales[6] * np.random.randn(64*4*4, hidden_size)self.params['b7'] = np.zeros(hidden_size)self.params['W8'] = wight_init_scales[7] * np.random.randn(hidden_size, output_size)self.params['b8'] = np.zeros(output_size)# 生成层===========self.layers = []self.layers.append(Convolution(self.params['W1'], self.params['b1'], conv_param_1['stride'], conv_param_1['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W2'], self.params['b2'], conv_param_2['stride'], conv_param_2['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Convolution(self.params['W3'], self.params['b3'], conv_param_3['stride'], conv_param_3['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W4'], self.params['b4'],conv_param_4['stride'], conv_param_4['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Convolution(self.params['W5'], self.params['b5'],conv_param_5['stride'], conv_param_5['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W6'], self.params['b6'],conv_param_6['stride'], conv_param_6['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Affine(self.params['W7'], self.params['b7']))self.layers.append(Relu())self.layers.append(Dropout(0.5))self.layers.append(Affine(self.params['W8'], self.params['b8']))self.layers.append(Dropout(0.5))self.last_layer = SoftmaxWithLoss()def predict(self, x, train_flg=False):for layer in self.layers:if isinstance(layer, Dropout):x = layer.forward(x, train_flg)else:x = layer.forward(x)return xdef loss(self, x, t):y = self.predict(x, train_flg=True)return self.last_layer.forward(y, t)def accuracy(self, x, t, batch_size=100):if t.ndim != 1 : t = np.argmax(t, axis=1)acc = 0.0for i in range(int(x.shape[0] / batch_size)):tx = x[i*batch_size:(i+1)*batch_size]tt = t[i*batch_size:(i+1)*batch_size]y = self.predict(tx, train_flg=False)y = np.argmax(y, axis=1)acc += np.sum(y == tt)return acc / x.shape[0]def gradient(self, x, t):# forwardself.loss(x, t)# backwarddout = 1dout = self.last_layer.backward(dout)tmp_layers = self.layers.copy()tmp_layers.reverse()for layer in tmp_layers:dout = layer.backward(dout)# 设定grads = {}for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):grads['W' + str(i+1)] = self.layers[layer_idx].dWgrads['b' + str(i+1)] = self.layers[layer_idx].dbreturn gradsdef save_params(self, file_name="params.pkl"):params = {}for key, val in self.params.items():params[key] = valwith open(file_name, 'wb') as f:pickle.dump(params, f)def load_params(self, file_name="params.pkl"):with open(file_name, 'rb') as f:params = pickle.load(f)for key, val in params.items():self.params[key] = valfor i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):self.layers[layer_idx].W = self.params['W' + str(i+1)]self.layers[layer_idx].b = self.params['b' + str(i+1)]


















