神经网络如何调参、超参数的最优化方法、python实现
- 一、what is 超参数
- 二、超参数优化实验
一、what is 超参数
超参数是什么,其实就是,各层神经元数量、batch大小、学习率等人为设定的一些数。
数据集分为训练数据、测试数据、验证数据。
用测试数据评估超参数值的好坏,就可能导致超参数的值被调整为只拟合测试数据,所以加了个验证数据。
训练数据用于参数的学习,验证数据用于超参数的性能评估。
进行超参数最优化,重要的是,逐渐缩小超参数好值存在范围。
一开始大致设定一个范围,从范围中随机采样出超参数,用这个采样值进行识别精度评估,根据这个结果缩小超参数好值范围,然后重复上述操作。研究发现,随机采样效果好点。
二、超参数优化实验
接下来用MNISIT数据集进行超参数最优化,参考斯坦福大学的实验。
实验:最优化学习率和控制权值衰减强度系数这两个参数。
实验中,权值衰减系数初始范围1e- 8到1e- 4,学习率初始范围1e- 6到1e- 2。
随机采样体现在下面代码:
weight_decay = 10 ** np.random.uniform(-8, -4)lr = 10 ** np.random.uniform(-6, -2)
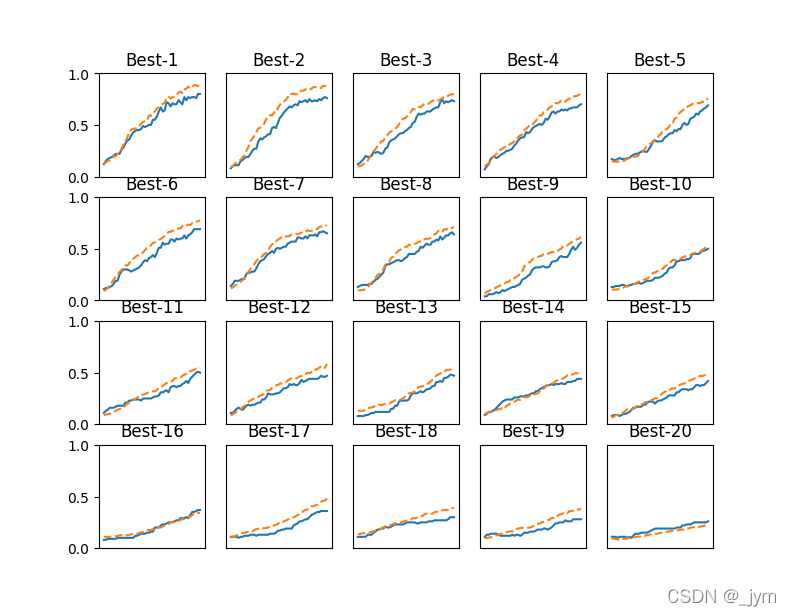
实验结果:
结果可以看出,学习率在0.001到0.01之间,权值衰减系数在1e-8到1e-6之间时,学习可以顺利进行。
观察可以使学习顺利进行的超参数范围,从而缩小值的范围。
然后可以从缩小的范围中继续缩小,然后选个最终值。
=========== Hyper-Parameter Optimization Result ===========
Best-1(val acc:0.8) | lr:0.008986830875594513, weight decay:3.716187805144909e-07
Best-2(val acc:0.76) | lr:0.007815234765792472, weight decay:8.723036800420108e-08
Best-3(val acc:0.73) | lr:0.004924088836198354, weight decay:5.044414627324654e-07
Best-4(val acc:0.7) | lr:0.006838530258012433, weight decay:7.678322790416307e-06
Best-5(val acc:0.69) | lr:0.0037618568422154793, weight decay:6.384663995933291e-08
Best-6(val acc:0.69) | lr:0.004818463383741305, weight decay:4.875486288914377e-08
Best-7(val acc:0.65) | lr:0.004659925318439445, weight decay:1.4968108648982665e-05
Best-8(val acc:0.64) | lr:0.005664124223619111, weight decay:6.070191899324037e-06
Best-9(val acc:0.56) | lr:0.003954240835144594, weight decay:1.5725686195018805e-06
Best-10(val acc:0.5) | lr:0.002554755378245952, weight decay:4.481334628759244e-08
Best-11(val acc:0.5) | lr:0.002855983685917335, weight decay:1.9598718051356917e-05
Best-12(val acc:0.47) | lr:0.004592998586693871, weight decay:4.888121831499798e-05
Best-13(val acc:0.47) | lr:0.0025326736070483947, weight decay:3.200796060402024e-05
Best-14(val acc:0.44) | lr:0.002645798359877985, weight decay:5.0830237860839325e-06
Best-15(val acc:0.42) | lr:0.001942571686958991, weight decay:3.0673143794194257e-06
Best-16(val acc:0.37) | lr:0.001289748323175032, weight decay:2.3690338828642213e-06
Best-17(val acc:0.36) | lr:0.0017017390582746337, weight decay:9.176068035802207e-05
Best-18(val acc:0.3) | lr:0.0015961247160317246, weight decay:1.3527453417413358e-08
Best-19(val acc:0.28) | lr:0.002261959202515378, weight decay:6.004620370338303e-05
Best-20(val acc:0.26) | lr:0.0008799239275589458, weight decay:4.600825912333848e-07
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net import MultiLayerNet
from common.util import shuffle_dataset
from common.trainer import Trainer(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)# 为了实现高速化,减少训练数据
x_train = x_train[:500]
t_train = t_train[:500]# 分割验证数据
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_train, t_train = shuffle_dataset(x_train, t_train)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]def __train(lr, weight_decay, epocs=50):network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],output_size=10, weight_decay_lambda=weight_decay)trainer = Trainer(network, x_train, t_train, x_val, t_val,epochs=epocs, mini_batch_size=100,optimizer='sgd', optimizer_param={'lr': lr}, verbose=False)trainer.train()return trainer.test_acc_list, trainer.train_acc_list# 超参数的随机搜索======================================
optimization_trial = 100
results_val = {}
results_train = {}
for _ in range(optimization_trial):# 指定搜索的超参数的范围===============weight_decay = 10 ** np.random.uniform(-8, -4)lr = 10 ** np.random.uniform(-6, -2)# ================================================val_acc_list, train_acc_list = __train(lr, weight_decay)print("val acc:" + str(val_acc_list[-1]) + " | lr:" + str(lr) + ", weight decay:" + str(weight_decay))key = "lr:" + str(lr) + ", weight decay:" + str(weight_decay)results_val[key] = val_acc_listresults_train[key] = train_acc_list# 绘制图形========================================================
print("=========== Hyper-Parameter Optimization Result ===========")
graph_draw_num = 20
col_num = 5
row_num = int(np.ceil(graph_draw_num / col_num))
i = 0for key, val_acc_list in sorted(results_val.items(), key=lambda x:x[1][-1], reverse=True):print("Best-" + str(i+1) + "(val acc:" + str(val_acc_list[-1]) + ") | " + key)plt.subplot(row_num, col_num, i+1)plt.title("Best-" + str(i+1))plt.ylim(0.0, 1.0)if i % 5: plt.yticks([])plt.xticks([])x = np.arange(len(val_acc_list))plt.plot(x, val_acc_list)plt.plot(x, results_train[key], "--")i += 1if i >= graph_draw_num:breakplt.show()


















