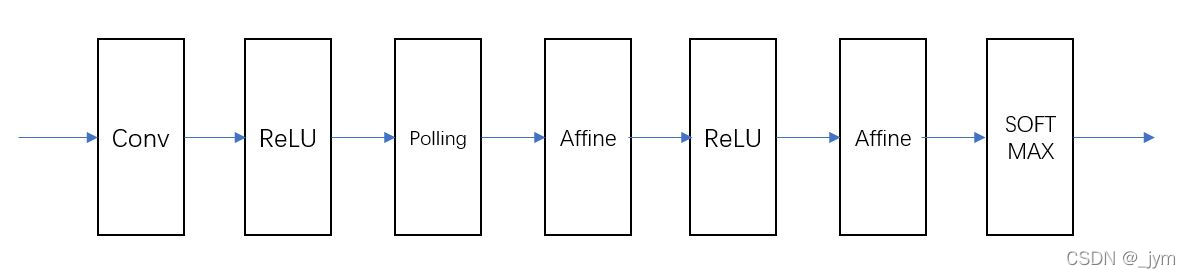
一、CNN网络结构与构建
参数:
输入数据的维数,通道,高,长
input_dim=(1, 28, 28)
卷积层的超参数,filter_num:滤波器数量,filter_size:滤波器大小,stride:步幅,pad,填充。
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1}
hidden_size,隐藏层全连接神经元数量;
output_size,输出层全连接神经元数量;
weight_init_std,初始化时,权重的标准差;
hidden_size=100, output_size=10, weight_init_std=0.01
学习所需参数是第一层的卷积层和剩余两个全连接层的权重和偏置。权重、偏置,分别用W、b保存。
self.params = {}self.params['W1'] = weight_init_std * \np.random.randn(filter_num, input_dim[0], filter_size, filter_size)self.params['b1'] = np.zeros(filter_num)self.params['W2'] = weight_init_std * \np.random.randn(pool_output_size, hidden_size)self.params['b2'] = np.zeros(hidden_size)self.params['W3'] = weight_init_std * \np.random.randn(hidden_size, output_size)self.params['b3'] = np.zeros(output_size)
代码:
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradientclass SimpleConvNet:"""简单的ConvNetconv - relu - pool - affine - relu - affine - softmaxParameters----------input_size : 输入大小(MNIST的情况下为784)hidden_size_list : 隐藏层的神经元数量的列表(e.g. [100, 100, 100])output_size : 输出大小(MNIST的情况下为10)activation : 'relu' or 'sigmoid'weight_init_std : 指定权重的标准差(e.g. 0.01)指定'relu'或'he'的情况下设定“He的初始值”指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”"""def __init__(self, input_dim=(1, 28, 28), conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},hidden_size=100, output_size=10, weight_init_std=0.01):filter_num = conv_param['filter_num']filter_size = conv_param['filter_size']filter_pad = conv_param['pad']filter_stride = conv_param['stride']input_size = input_dim[1]conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))# 初始化权重self.params = {}self.params['W1'] = weight_init_std * \np.random.randn(filter_num, input_dim[0], filter_size, filter_size)self.params['b1'] = np.zeros(filter_num)self.params['W2'] = weight_init_std * \np.random.randn(pool_output_size, hidden_size)self.params['b2'] = np.zeros(hidden_size)self.params['W3'] = weight_init_std * \np.random.randn(hidden_size, output_size)self.params['b3'] = np.zeros(output_size)# 生成层self.layers = OrderedDict()self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],conv_param['stride'], conv_param['pad'])self.layers['Relu1'] = Relu()self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])self.layers['Relu2'] = Relu()self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])self.last_layer = SoftmaxWithLoss()def predict(self, x):for layer in self.layers.values():x = layer.forward(x)return xdef loss(self, x, t):"""求损失函数参数x是输入数据、t是教师标签"""y = self.predict(x)return self.last_layer.forward(y, t)def accuracy(self, x, t, batch_size=100):if t.ndim != 1 : t = np.argmax(t, axis=1)acc = 0.0for i in range(int(x.shape[0] / batch_size)):tx = x[i*batch_size:(i+1)*batch_size]tt = t[i*batch_size:(i+1)*batch_size]y = self.predict(tx)y = np.argmax(y, axis=1)acc += np.sum(y == tt) return acc / x.shape[0]def numerical_gradient(self, x, t):"""求梯度(数值微分)Parameters----------x : 输入数据t : 教师标签Returns-------具有各层的梯度的字典变量grads['W1']、grads['W2']、...是各层的权重grads['b1']、grads['b2']、...是各层的偏置"""loss_w = lambda w: self.loss(x, t)grads = {}for idx in (1, 2, 3):grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)])grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)])return gradsdef gradient(self, x, t):"""求梯度(误差反向传播法)Parameters----------x : 输入数据t : 教师标签Returns-------具有各层的梯度的字典变量grads['W1']、grads['W2']、...是各层的权重grads['b1']、grads['b2']、...是各层的偏置"""# forwardself.loss(x, t)# backwarddout = 1dout = self.last_layer.backward(dout)layers = list(self.layers.values())layers.reverse()for layer in layers:dout = layer.backward(dout)# 设定grads = {}grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].dbgrads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].dbgrads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].dbreturn gradsdef save_params(self, file_name="params.pkl"):params = {}for key, val in self.params.items():params[key] = valwith open(file_name, 'wb') as f:pickle.dump(params, f)def load_params(self, file_name="params.pkl"):with open(file_name, 'rb') as f:params = pickle.load(f)for key, val in params.items():self.params[key] = valfor i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):self.layers[key].W = self.params['W' + str(i+1)]self.layers[key].b = self.params['b' + str(i+1)]
二、使用CNN网络学习MNIST数据集并观察效果
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from simple_convnet import SimpleConvNet
from common.trainer import Trainer# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)# 处理花费时间较长的情况下减少数据
x_train, t_train = x_train[:5000], t_train[:5000]
x_test, t_test = x_test[:1000], t_test[:1000]max_epochs = 20network = SimpleConvNet(input_dim=(1,28,28), conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},hidden_size=100, output_size=10, weight_init_std=0.01)trainer = Trainer(network, x_train, t_train, x_test, t_test,epochs=max_epochs, mini_batch_size=100,optimizer='Adam', optimizer_param={'lr': 0.001},evaluate_sample_num_per_epoch=1000)
trainer.train()# 保存参数
network.save_params("params.pkl")
print("Saved Network Parameters!")# 绘制图形
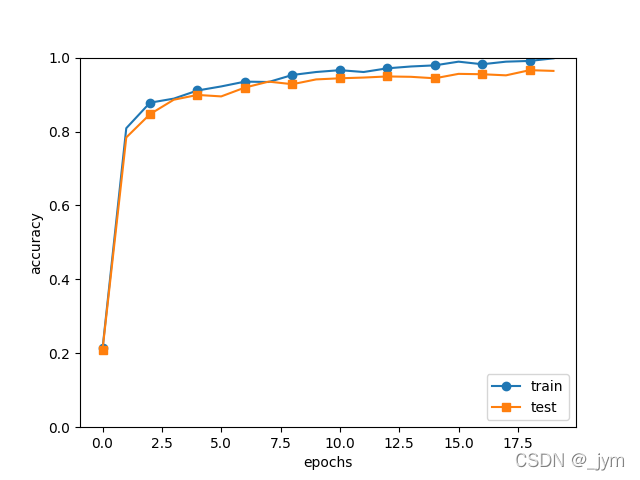
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs)
plt.plot(x, trainer.train_acc_list, marker='o', label='train', markevery=2)
plt.plot(x, trainer.test_acc_list, marker='s', label='test', markevery=2)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()效果:
=== epoch:20, train acc:0.998, test acc:0.964 ===
train loss:0.007401310521311435
train loss:0.027614604405772653
train loss:0.010395290280106407
train loss:0.009055562731122933
train loss:0.010614723913692073
train loss:0.012437935682767121
train loss:0.026701506796337437
train loss:0.006204184557258094
train loss:0.010404145189650856
train loss:0.010929826675443866
train loss:0.0043394220957300835
train loss:0.016781798147762927
train loss:0.008747950916926508
train loss:0.022275261048058662
train loss:0.004475751241820642
train loss:0.018634365845167887
train loss:0.010216296159200803
train loss:0.05663255540517016
train loss:0.007190307798334322
train loss:0.05278721478973261
train loss:0.01059534308178735
train loss:0.005966098495078249
train loss:0.010178506340940181
train loss:0.03654597399370525
train loss:0.019495820002866274
train loss:0.01572182958630932
train loss:0.00465907402610126
train loss:0.024876708101982406
train loss:0.005049280179694557
train loss:0.014516301412561905
train loss:0.007808137131314081
train loss:0.0400124952112783
train loss:0.014341889140004867
train loss:0.007797598015128371
train loss:0.02575987545665843
train loss:0.08519312577327812
train loss:0.021226771077661372
train loss:0.004566285129776959
train loss:0.014989958271037414
train loss:0.015107332850379906
train loss:0.017502483559764623
train loss:0.008879393649119861
train loss:0.013326281023352782
train loss:0.021570154414811325
train loss:0.010967106033868279
train loss:0.039365545329473575
train loss:0.03687669299007644
train loss:0.005511731850415302
train loss:0.005646337734962965
=============== Final Test Accuracy ===============
test acc:0.963
测试数据识别率百分之九十多,可见识别率还是挺不错的。