文 | 子龙
编 | 小轶
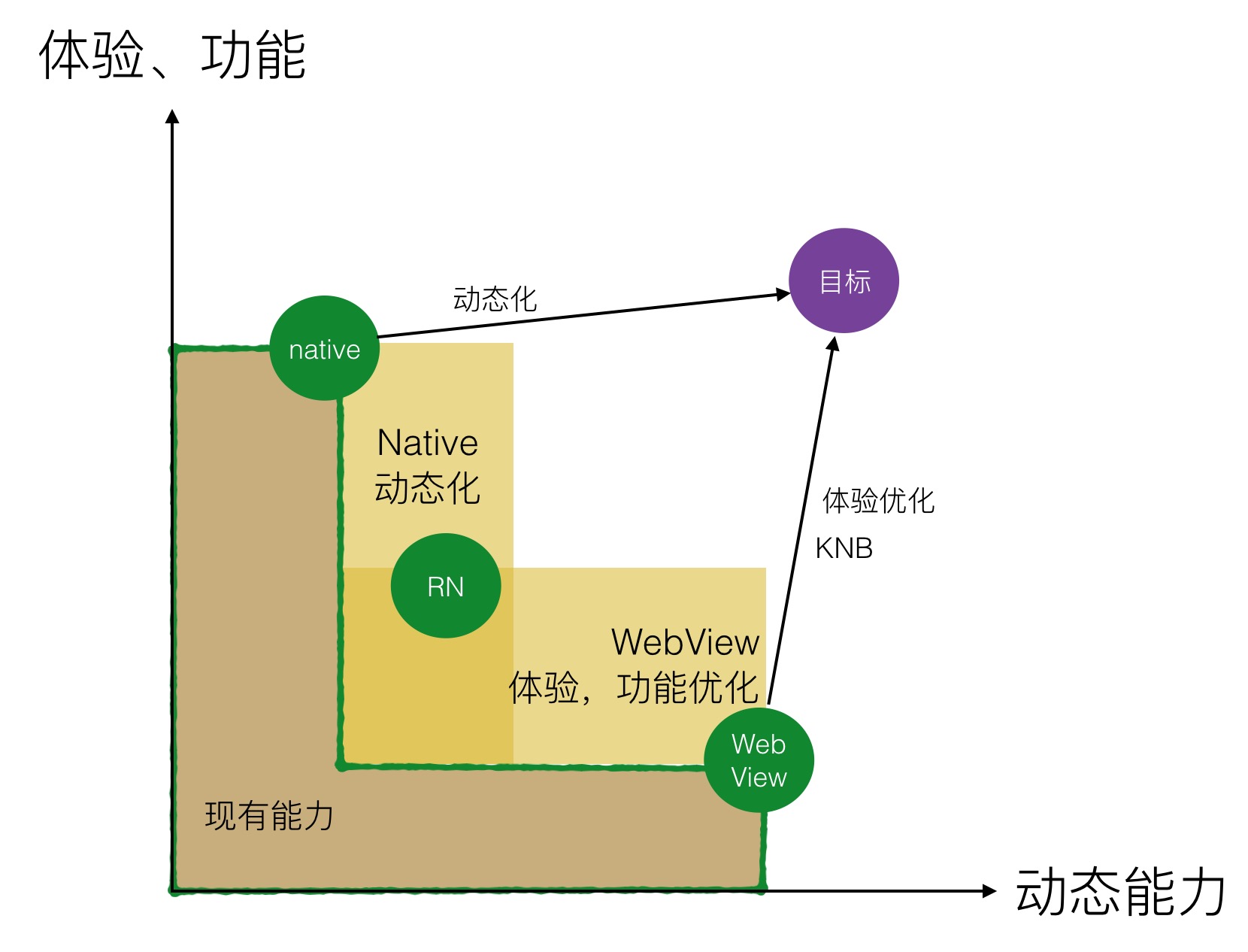
俗话说:“行百步者半九十”,论文接受固然可喜可贺,然而这只是万里长征第一步。一份具有影响力的工作少不了一个后期的宣传,做好一个PPT绝对是一个技术活。不知道小伙伴们平时怎么做PPT,是复制粘贴长篇大论抑或提纲挈领图文并茂。直接拷贝论文固然简单,但是动辄大半页的文字实在很难让人提起兴趣,大家都明白应该抓住要点,并辅以图片,但是怎么总结文章各个板块并且合理排布呢,这又是个难题。
虽然论文千变万化,但是计算机论文的PPT往往还是比较朴实无华的,往往遵循一定的格式,从介绍到模型,再从实验到结论,基本上和行文对应,那么对每个板块抽取核心信息,那么就能生成一份满意的PPT。
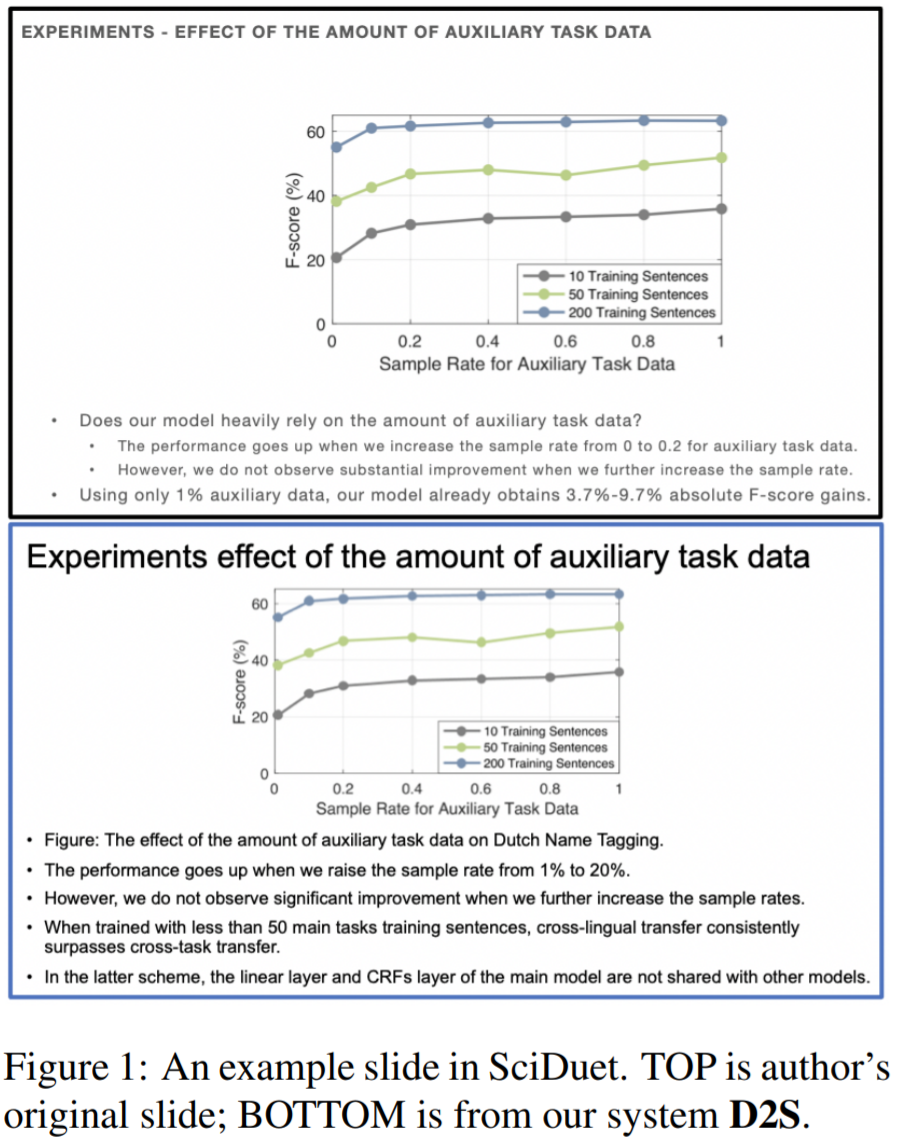
今天介绍一篇NAACL'21的文章 D2S: Document-to-Slide Generation Via Query-Based Text Summarization 直接省去了苦思PPT细节的麻烦,提出一个基于问答抽取的方法,通过论文内容和给定标题直接生成对应的PPT。下图就展示了一个用D2S自动生成的论文介绍PPT样例。上方黑框中的是论文作者自己做的PPT,下面蓝框里的是D2S自动生成的。可以看到,文字介绍部分还是十分合理的,与配图对应,整体排版上还要优于人工制作的PPT。
论文题目:
D2S: Document-to-Slide Generation Via Query-Based Text Summarization
论文链接:
https://arxiv.org/abs/2105.03664
 方法
方法
本文将D2S(文档生成PPT)视为一个封闭领域长文本问答,即限定在计算机论文的领域中,给定论文和每页PPT的标题,从论文中抽取对应内容并加以总结,作为标题的“答案”。整个模型分为三个模块,分别是:
关键词模块: PPT的排布与论文本身的各个子标题有着很大的关联,于是D2S抽取论文子标题的层次结构作为生成PPT的辅助。
信息抽取模块: 这部分获得文档标题和论文片段以及关键词模块中的关键词的向量表示,并作相关度排序。
问答模块: 整合以上两个模块得到的关键词和信息,通过问答模型生成PPT内容。
图表抽取模块: 通过论文中插图的图表介绍与每页PPT的标题计算相似度,将图表插入到对应页面。
关键词模块
论文的PPT肯定要参考原本论文,从一篇论文的各个版块的标题那里,可以大致看出一篇文章所关注的要点和行文思路,这些标题可能是最基本的“介绍”、“相关文献”、“实验”,也可能是论文所设计的模块的名称,比如Attention is all you need论文中,就有专门介绍Attention的一个部分。这些标题和子标题很自然的就形成了一个树状结构(模型图左下角),这些树状结构中的节点被提取出来,作为关键词,辅助后续的内容生成。
信息抽取模块
关键词模块只是为了后续工作提供了一定的帮助,而信息抽取模块才真正开始处理论文和PPT标题。本文采用了基于distilled BERT[1]的信息抽取模型。信息抽取模型可以根据相关程度在若干候选中给出一个排序,这个模块就是为了从论文中找到和对应PPT标题相关的片段。
训练模型
既然需要模型学习相关性,最容易想到的方法就是通过人工标注进行有监督学习,然而很难从最终完成的PPT中看出当前页面与论文中哪些地方相关,于是本文选择了一个折中的方法来训练信息抽取模型,它将当前PPT页面中的内容作为正例,将其他PPT页面中的内容作为反例,训练模型辨别这两者的区别,进而学习PPT标题和内容的相关性,所学习得到的相关性可以后续用于评估PPT标题和论文片段的相关性。
抽取片段
因为PPT页面中的内容和论文片段十分相似,于是通过上述方法训练的模型可以很好的运用于评估PPT标题和论文片段的相关性。同时,每个论文片段同时又拥有对应的标题或者子标题,即关键词模块提取到的关键词,最终每个论文片段与当前PPT标题的相关性取决于两方面:
其中、、分别为PPT标题、论文片段、片段对应关键词的文本特征。
问答模块
最终每页PPT中的内容由问答模块来生成,这里采用的是预训练的BART模型[2]。我们需要将“问题”和“上下文信息”提供给问答模型,这里的“问题”即每页PPT的标题,上下文信息分为两方面:
关键词:将PPT标题与论文每个标题进行对应,计算两者的编辑距离(“莱文斯坦距离”[3]),若“编辑距离比值”大于0.9,则将对应标题以及其子标题纳入到上下文信息中。
其中a,b为两个字符串,d为两者的编辑距离。
论文片段:即上文信息抽取模块所提供的相关论文片段。
将整合好的“问题”和“上下文”以如下格式输入到预训练的BART,得到对应PPT的内容:
图表抽取模块
没有插图的PPT是不完整的,D2S对图片的处理非常简单,直接利用信息抽取模块中训练得到的模型评估PPT标题和图片或者表格的描述文字计算相关性,进而插入到对应PPT页面内。
 模型表现
模型表现
本文主要评估生成PPT的两个方面:
图表位置:由于是信息抽取模型,图表位置得到的是一个从最相关到最不相关的排序,论文报告了top 1,3,5的精确值,分别为:p@1=0.38, p@3=0.60, p@5=0.77。
PPT内容生成效果:分别通过ROUGE进行评价。
PPT内容生成效果
因为这个任务的本质是信息抽取与总结,本文对比了D2S的问答模块(记为BARTKeyword)与如下baseline:BertSummExt4、BARTSumm(本文模型去除Keyword部分)。
同时,本文还将信息抽取模块中的混合keyword的方法(Dense-Mix IR)和传统的基于离散单词对应的BM25(Classical IR)做对比。结果如下:
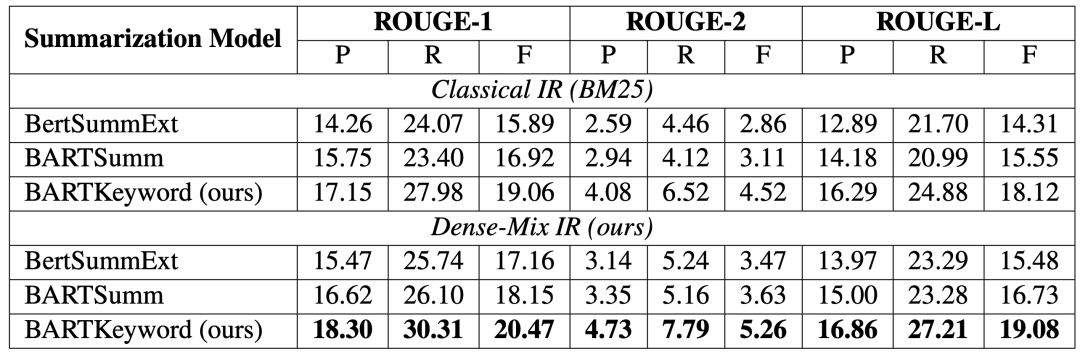
从结果中可以看到结合关键词的方法往往能够得到更好的效果。在信息抽取阶段引入关键词,可以更好地评估PPT标题和论文片段的相关性,进而得到更加准确的上下文,这一点从各个baseline的结果中都可以看出。在问答模块阶段,与以往单纯将论文片段作为上下文,D2S中的BARTKeyword将关键词同样输入到上下文部分,也大大地提高了Rough值。
可见,论文中的标题和子标题是一篇文章的骨架,很大程度上可以帮助针对论文内容的总结归纳工作,进而在生成PPT的任务中大有作为。
 总结
总结
本文由诸多模块组成,利用了信息抽取和问答模型对计算机领域的论文进行总结,并创造性的提出了生成PPT这样的任务,同时利用了论文各个版块的标题和子标题提供更多的信息。
萌屋作者:子龙(Ryan)
本科毕业于北大计算机系,曾混迹于商汤和MSRA,现在是宅在UCSD(Social Dead)的在读PhD,主要关注多模态中的NLP和data mining,也在探索更多有意思的Topic,原本只是贵公众号的吃瓜群众,被各种有意思的推送吸引就上了贼船,希望借此沾沾小屋的灵气,paper++,早日成为有猫的程序员!
作品推荐:
1.别再搞纯文本了!多模文档理解更被时代需要!
2.Transformer哪家强?Google爸爸辨优良!
3.预训练语言真的是世界模型?
寻求报道、约稿、文案投放:
添加微信xixiaoyao-1,备注“商务合作”
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!

[1] Distilled BERT: https://arxiv.org/pdf/1908.08962.pdf
[2] BART模型: https://arxiv.org/abs/1910.13461
[3] 莱文斯坦距离:https://en.wikipedia.org/wiki/Levenshtein_distance
[4] BertSummExt: https://arxiv.org/abs/1908.08345