笔记整理 | 谭亦鸣,东南大学博士生

来源:EMNLP 2020
链接:https://www.aclweb.org/anthology/2020.emnlp-main.469.pdf
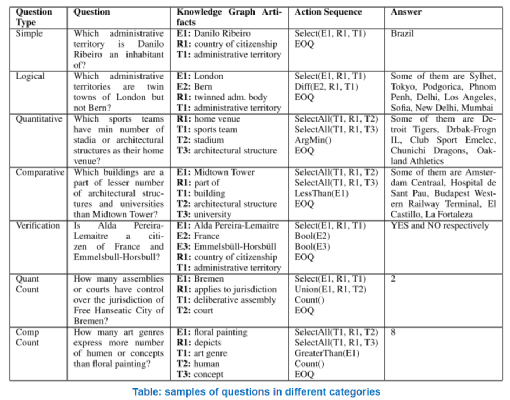
本文关注聚合型复杂知识图谱问答任务,这类复杂问题的答案通常需要经过一些集合操作得到,例如:选择Selecting,计数Counting,比较Comparing,交并集Interp&Union,Boolean等,一个比较经典的问题就是 “有多少条河流同时经过中国和印度?”(下表描述了其他一些类型的复杂问题),该问题答案可以通过”Select(China, flow, river), Interp(India, flow, river), Count”得到。
在当前的研究中,复杂知识图谱问答任务存在两个主要挑战:
1.不平衡的数据分布以及不稳定的模型性能:基于现有的CQA数据集,作者发现,不同类别的问题在训练数据中的占比极不平衡(例如简单问题占比约48.9%,而其他类型,诸如比较仅占比4.3%,其他类型的占比论文中也已给出,这里不再赘述。);另一方面,不同类型的问题难度差异明显。
2.面向全类别问答的单一模型性能不够:现有的问答模型难以适用于这类包含固有类型差异的问题。
因此这篇论文的主要贡献是:
1.作者提出了一个Meta Reinforcement Learning方法,可以自适应的对于新问题生成新参数;
2.建立了一个非监督检索器,用于找到适用的支撑集;
3.在仅使用1%训练样本的情况下使模型达到了具有竞争力的结果
4.在CQA任务上达到了当前性能最佳(state-of-the-art)
方法
目标是构建一个端到端模型,将复杂的自然语言问题转换为一系列的动作。通过执行这些动作,知识库中相关的三元组被取出并用于获取问题的答案。为了解决上述挑战,作者采用了few-shot mate reinforcement learning方法用于减少模型对于数据集标注的依赖,并提升不同类型问题上的问答准确性。
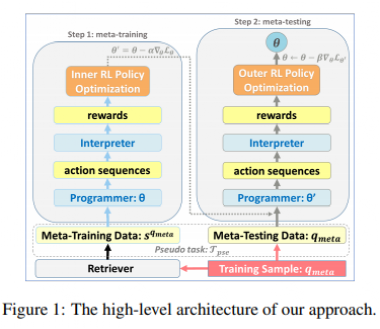
图1是论文方法的主要框架,作者将每个新的训练问题视作伪任务上的测试样本,目标是学习到一个专门处理这个任务的模型。当模型遇到一个问题qmate,首先使用检索器从训练集中找到与之最为相似的N个样本sqmate,并将该问题视作元学习测试数据,用于评估模型。因此,mate样本与问题构成了上述伪任务。
在mate-learning阶段,主要包含三个目标:
1.找到优化初始参数
2.使初始参数足够敏感
3.对每个任务生成合适的参数集
作者通过以下方式完成上述目标:
1.找到支撑集
2.使用支撑集调整programmer
3.使用微调后的programmer作用于测试样本
4.使用测试样本的损失更新初始参数
对应的算法如下所示:

训练过程在强化学习的设定下完成,以batch=1为例,每个时间阶段t,agent根据前置的action(t时刻之前),输入序列,从策略π产生一个action at(这里指词,或者字符),θ则表示模型的参数(例如带有注意力机制的LSTM模型的参数)。关联到知识库上的自然语言问题将会作为LSTM模型编码器的输入,一系列action则由解码器输出。
每组生成的action序列被作者视为一个轨迹(trajectory),借由它可以执行答案的生成,之后即可得到生成答案与事实答案的相似性(similarity),该相似性被作为强化学习框架中的对应轨迹的reward R,并反馈给agent。
问题检索器Retriever
为了从在训练和测试阶段从训练数据中找到支撑样本,作者提出了一个非监督的相关性函数,考虑了以下两个方面:其一是知识库相关元素的数量(包括实体,关系和类型);其二则是问题的语义相似度
前者的计算方式为:
1.问题结构相似计算公式:
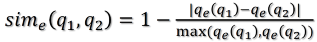 ,其中qe代表实体的数量
,其中qe代表实体的数量
2.类型相似
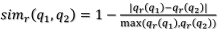
3.以及关系型数据相似性计算
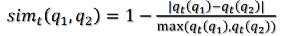
语义相似度上,作者基于Jaccard相似性建立了一个非监督的语义相似性公式。
假设问题q1,q2各包含一个词集合,对于q1中的每个词,基于一个给定的余弦相似性阈值,从q2中找到相似性最高的对应词,两者构成词对集合:
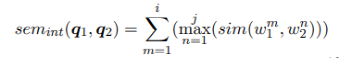
接着从两个句子中移除具有高相似关联的词汇,余下部分被称为remain,代表着两个问题之间的差异,基于这些remain,可以计算出两个问题之间差异性:
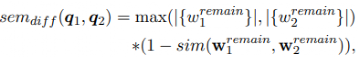
由此可以给出两个问题语义相似计算公式为:
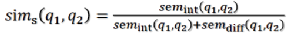
通过融合上述两者,最终得到相似计算公式为:
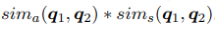
实验
本文实验所使用的数据为CQA数据集,包含944K/100K/154K的训练集/验证集/测试集,每个QA对包含一个复杂自然语言问题以及它的正确答案,但是并没有给出问题对应的标准action序列。考虑到这一点,作者随机的筛选了1%的训练集数据,使用BFS算法构建为其标准了伪标准action序列。在问题的表示学习方面,作者使用了带有注意力机制的LSTM。
CQA任务的评价指标为F1-值
对比的baseline包括:
1.HRED+Kvmem记忆网络
2.NSM
3.CIPITR-All
4.CIPITR-Sep
实验结果如下表所示,纵向为各种问题类型,横向对比了不同模型的性能水平。

OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。