
Citation: Ji,G., Liu, K., He, S., & Zhao, J. (2017). Distant Supervision for RelationExtraction with Sentence-Level Attention and Entity Descriptions. Ai,3060–3066.
动机
关系抽取的远程监督方法通过知识库与非结构化文本对其的方式,自动标注数据,解决人工标注的问题。但是,现有方法存在无法选择有效的句子、缺少实体知识的缺陷。无法选择有效的句子是指模型无法判断关系实例对应的句子集(bag)中哪个句子是与关系相关的,在建模时能会将不是表达某种关系的句子当做表达这种关系的句子,或者将表达某种关系的句子当做不表达这种关系的句子,从而引入噪声数据;缺少实体知识是指,例如下面的例句种,如果不知道 Nevada 和 Las Vegas 是两座城市,则很难判断他们知识是地理位置上的包含关系。

本文为了引入更丰富的信息,从 Freebase 和 Wikipedia 页面中抽取实体描述,借鉴表示学习的思想学习得到更好的实体表示,并提出一种句子级别的注意力模型。本文提出的模型更好地实现注意力机制,有效降低噪声句子的影响,性能上达到当前最优。
贡献
文章的贡献有:
(1)引入句子级别的注意力模型来选择一个 bag 中的多个有用的句子,从而充分利用 bag 种的有用信息;
(2)使用实体描述来为关系预测和实体表达提供背景信息;
(3)实验效果表面,本文提出的方法是 state-of-the-art 的。
方法
本文的方法包括三个部分:(1)句子特征提取;(2)实体表示;(3)bag特征提取;
句子特征提取
模型结构如下图(a)所示,模型流程是:
(1)使用词向量和位置向量相连接作为单词表示,句子的词表示序列作为模型的输入;
(2)使用卷积神经网络对输入层提取特征,然后做piecewise最大池化,形成句子的特征表示;

实体表示
实体表示在词向量的基础上,使用实体描述信息对向量表示进行调整,形成最终的实体向量表示。
模型主要思想是,使用CNN对实体的描述信息进行特征提取,得到的特征向量作为实体的特征表示,模型的训练目标是使得实体的词向量表示和从描述信息得到的实体特征表示尽可能接近。
Bag 特征提取
Bag 特征提取模型的关键在句子权重学习,在得到 bag 中每个句子的权重后,对 bag 中所有句子的特征向量进行加权求和,得到bag的特征向量表示。模型中用到了类似TransE的实体关系表示的思想:e1+r=e2。使用(e2-e1)作为实体间关系信息的表达,与句子特征向量相拼接,进行后续的权重学习。
Bag 特征提取模型如上图(b)所示:
(1)使用bag中的所有句子的特征向量表示,结合e2-e1方式得到的关系表示,作为模型的输入;
(2)利用权重学习矩阵,得到每个句子的权重;
(3) 对句子进行加权求和,得到 bag 的最终表示;
实验
文章在远程监督常用的数据集(Rediel 2010)上,按照常规的远程监督的实验思路,分别进行了 heldout 和 manual 实验。Heldout 实验即使用知识库中已有的关系实例标注测试集,验证模型的性能,结果如下面的 Precision-Recall 图所示,超过其他最好的方法。
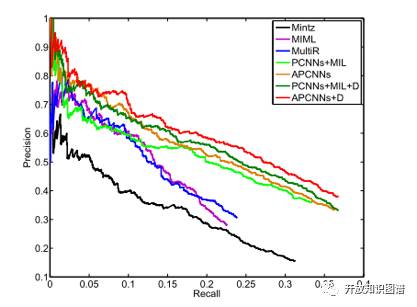
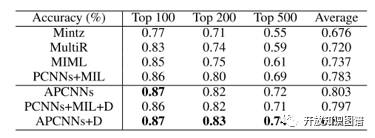
Manual 实验对知识库中不存在的关系实例进行预测,然后使用人工标注预测结果的正确性,使用 top-K 作为评测指标,结果如下表所示,本文提出的方法也达到了当前最好的效果。
此外,实验还通过 case study,研究了模型对于 bag 中每个句子的注意力分配效果,表明本模型可以有效地区分有用的句子和噪声句子,且本文的引入实体描述可以使得模型得到更好的注意力分配。
论文笔记整理:刘兵,东南大学博士,研究方向为自然语言处理、机器学习。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。



















