🍅 写在前面
👨🎓 博主介绍:大家好,这里是hyk写算法了吗,一枚致力于学习算法和人工智能领域的小菜鸟。
🔎个人主页:主页链接(欢迎各位大佬光临指导)
⭐️近期专栏:机器学习与深度学习
LeetCode算法实例
Pytorch实战
目录
- 总览
- 一、定制 Requests Headers
- 二、降低IP访问频率
总览
网络爬虫无非就是利用计算机来模拟人打开网站,进而获取网站中自己所需要的各种数据信息,然后进行存储、处理、清洗后获得有效数据。这是我们常用的爬虫思路,但是目前很多网站都具有各种各样的反爬虫机制,我们又该如何应对呢?这里提供两种解决思路。
一、定制 Requests Headers
针对该思路主要有三种实现方法:
-
修改user-agent:储存的是系统和浏览器的型号版本,可以尝试不同的浏览器,通过修改它来假装自己是人。使用浏览器打开任意网页,点击f12,找到网络,再点击请求地址,往下滑就会看到该浏览器的user-agent,如下图。
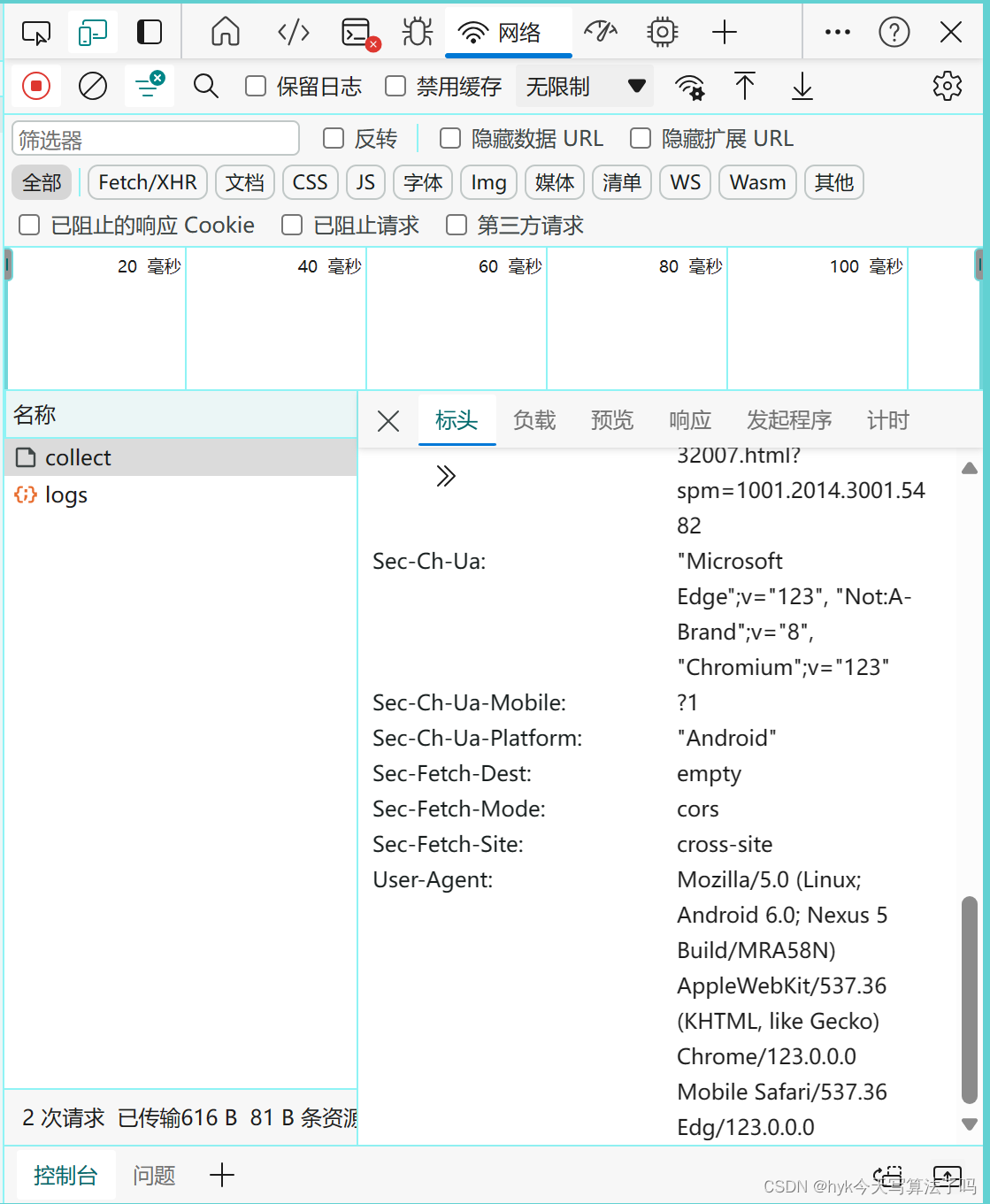
-
修改referer:告诉服务器你是通过哪个网址点进来的而不是凭空出现的,有些网站会检查。
-
带上cookie,有时带不带cookie得到的结果是不同的,尝试带cookie去“贿赂”服务器让它给你完整的信息。
二、降低IP访问频率
很多网站喜欢监视某个ip的访问频率和次数,一但超过阈值,就会禁止你这个ip继续访问,这时候我们就得想办法降低自己ip的访问频率了。针对该思路主要提供一下解决方法:
- 主动休眠,可以在爬虫中设置一个sleep时间,以便在各个爬虫穿插休息时间,防止访问网站过于频繁,被发现。
- IP代理,题海战术,不仅仅只用我自己的IP去访问网站,使用大量可用的、不同IP去访问统一的网站,它总不会拒绝网站流量增长吧。但是,这种方法的前提是你得有足够多可用的IP地址供你使用,而这种ip代理池一般是需要花钱的。这里给大家提供一个前段时间做爬虫项目发现的免费IP代理池,有以上烦恼的小伙伴们都可以去试试,详细见下图。

最后,如果上述方法都无效的话,那我推荐可以考虑考虑Selenium技术,它是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome、Firefox、Safari等主流界面浏览器,同时也支持phantomJS无界面浏览器。详细教程再我另一篇文章当中提及,大家有需要的可以阅览:Python爬虫——Selenium