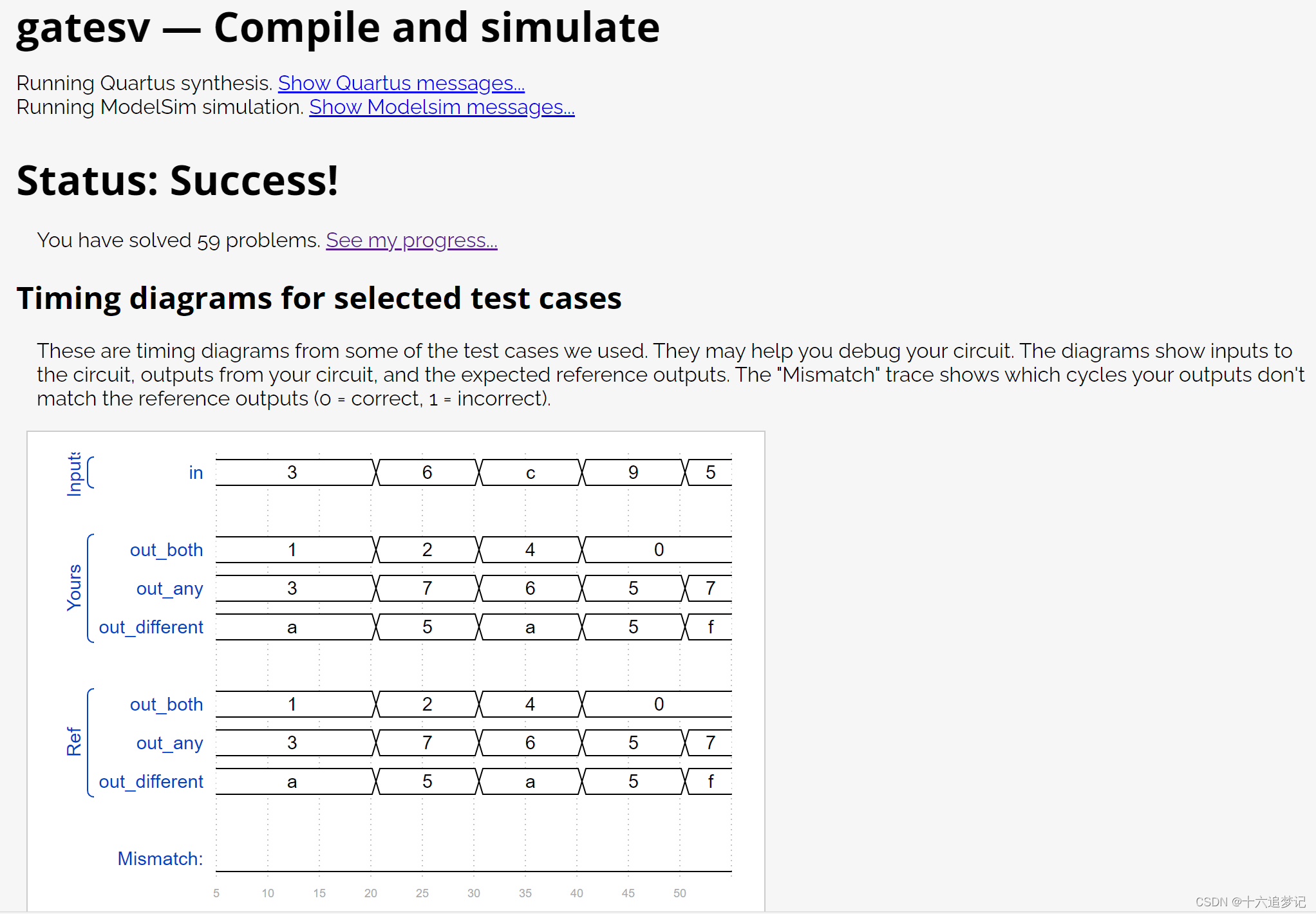
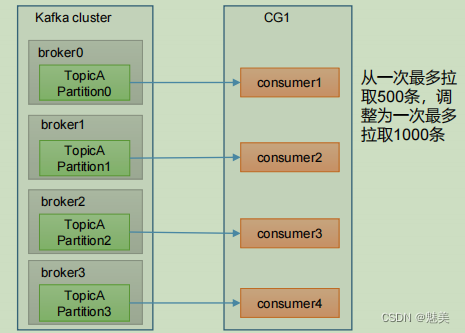
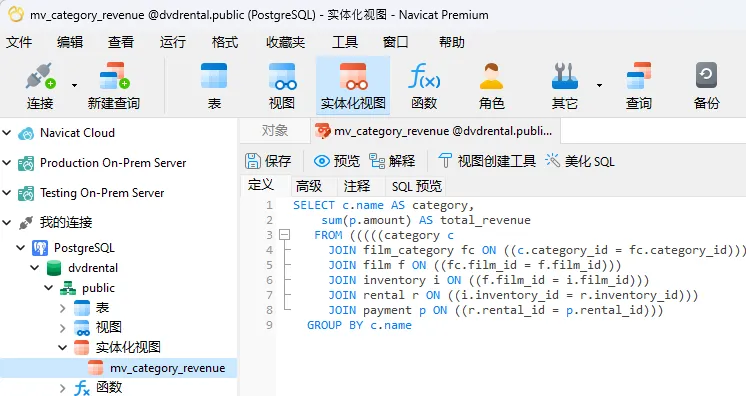
使用pdfplumber,不能提取扫描的pdf和插入的图片。
import pdfplumberfile_path = r'D:\UserData\admindesktop\官方文档\1903_Mesh-Models-Overview_FINAL.pdf'
with pdfplumber.open(file_path) as pdf:page = pdf.pages[0]print(page.extract_text()) # 所以文字print([word["text"] for word in page.extract_words()]) # 提取存在的文字