爬虫前景
在互联网的世界里,数据就是新时代的“黄金”。而爬虫,就是帮助我们淘金的“工具”。随着互联网的不断发展,数据量呈现指数级的增长,在数据为王的时代,有效的挖掘数据和利用,你会得到更多东西。
学完爬虫你可以从事爬虫开发的工作,一个3-5年的爬虫工程师可以拿20k以上。相比Java,爬虫竞争少,好就业。
同时你也可以做爬虫兼职,每月能挣个大几千。
什么是爬虫?
爬虫主要通过特定的算法,自动地从一个或多个网页开始,按照预设的规则下载并提取所需要的数据。简单来说,爬虫就是一个自动化的信息搜集工具。
用代码代替人去模拟浏览器或手机去执行执行某些操作。
例如:
-
自动登录钉钉,定时打卡
-
去91自动下载图片/视频
-
去京东抢茅台

分析&模拟
分析一个网址,用requests请求就可以实现。
分析:基于谷歌浏览器去分析。
模拟:基于requests模块发送请求。
安装 requests 库
pip3.11 install requests代码案例
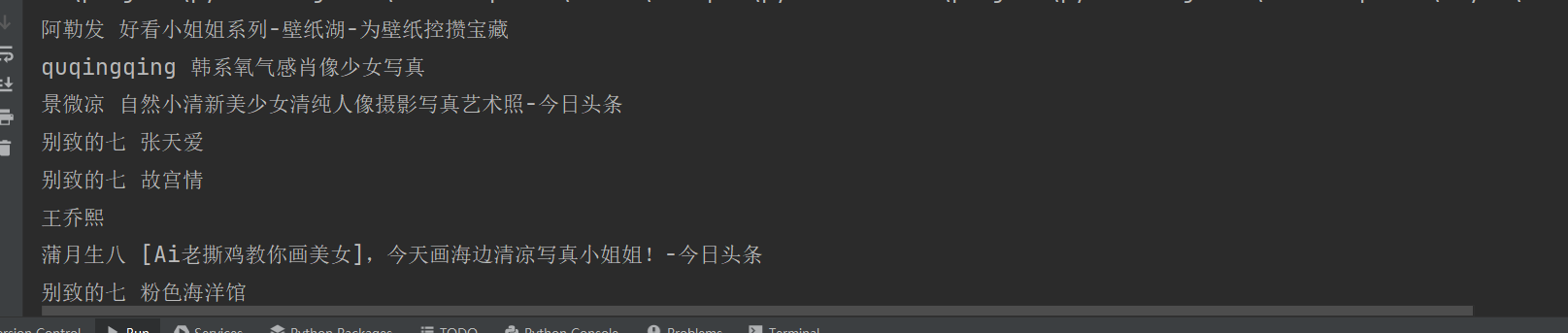
抓取花瓣网的 username 和 标题数据

import requests
import jsonres = requests.get(url='https://api.huaban.com/search/file?text=%E5%86%99%E7%9C%9F&sort=all&limit=40&page=1&position=search_pin&fields=pins:PIN,total,facets,split_words,relations,recommend_topics'
)#print(res.text)
data = json.loads(res.text)
pin_list = data['pins']
for item in pin_list:print(item['user']['username'], item['raw_text'])抓取结果:
如果本文对你有帮助,不要忘记一键三联,你的支持将鼓励我继续创作更多优质的内容!
 ORM API 编程入门)
)






,零基础入门到精通)

两个图像)

(2.1) Andruav Android Cellular(二))






