本文整理自白硕老师在 YOCSEF 武汉专题论坛:“人工智能遇到区块链,是惊鸿一瞥还是天长地久?”的报告。

很高兴有这个机会跟大家交流。我先讲几个案例作为引子。第一个案例与知识图谱有关。这个公司做的是非常垂直的一个领域,安全教育。比如驾驶员安全教育,危险品操作,危险品运输,危险品储藏等等。因为国家有规定,有大纲,有考题,有指标来规范从业者,但是很多人只能用碎片化的时间去学习来准备考试。在这种情况下,如果考试不合格的还要回炉,考试成绩还要归档等等。于是,这个公司很聪明,他们做了一个系统,就是把考题的知识点,以及各种关联都呈现给学员,然后还可以打分,不光是打分还能画像。然后这个公司就跟我说他做了这样一个东西,我说你这不就是知识图谱吗?他说对。这东西他做了两年了,到跟我见面前一个月他才知道这叫知识图谱。这说明什么?虽然大家不一定知道识图谱,但是从不同的角度都在往这儿汇聚。
第二个例子,是众包。大家可能有来自大专院校,有来自科研院所,爬盟这个词应该不陌生。爬盟是怎么回事?那就是像新浪微博这样的社交平台,想要获取他的数据用于科研是有难度。以一家之力是获取不全的,大家谁都没有独自爬取的实力。于是清华大学的梁斌博士,他的导师马少平,我们几个人就商量怎么办。那么最后就组织了一个爬盟,这就是一种爬取能力的众包。它是集中化的调度分配任务,然后大家分头的去爬,爬完了之后,再来共享,还要根据贡献度设计了一个机制,使得大家有不同的共享权利。
第三个例子是刚发生的,就是比特币社区分裂了。那么在去年,以太坊分裂的时候,比特币圈子里面还有人好像觉得不会出现类似的整个社区分裂的问题。这个问题说明什么呢?就是说,他们初衷都是好的,包括中本聪,他一开始设计这个机制的这个初衷都是好的。都是想做一个去中心化的东西,但是这个东西走着走着就中心化了。一些这个矿池随着慢慢发展就具有了举足轻重的这样一个地位。回过头来,考虑面向知识图谱的一个众包的社区,初衷如果是去中心化的,但是我们会不会走着走着又走到中心化那个地方去了呢?会不会走着走着又形成了一些数据寡头?那么形成数据寡头的以后,就会很难受。那么如何防止数据寡头的出现?而且,如果我们都是散兵来做众包和有一些正规军各拿一块去做这个众包,这是不一样的。如果有一些正规军的话,他们的领地意识非常强。那这样的领域意识非常强的一些机构在一起做这个联盟,去分享这些数据的时候,那么就会发生碰撞。这个时候又要共享,又要发生碰撞,那怎么去解决?所以我这个今天的前半部分会讲区块链领域的一些最新动向,包括如何来解决领地的问题或者叫数据主权边界的问题,那么后面一部分讲激励问题,就是说我们如果建立这样一个社区,那怎么样利用区块链来形成一个激励机制,然后再把我们这个社区能够健康地做起来。
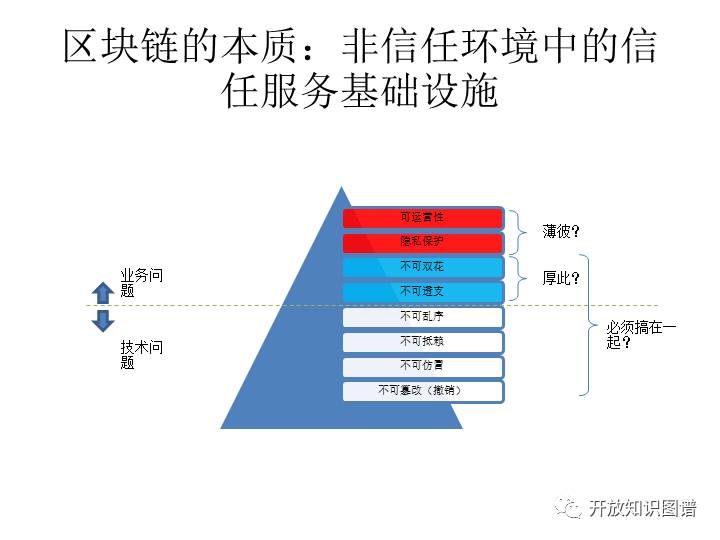
第一部分里面,首先要介绍这样一个图。这底下六块都是传统区块链的内容,就是从比特币出来就这一块,而上边两块是没有的。我们刚才提到的领地问题那关注就涉及到了第七块,所谓的隐私保护。隐私保护不是说大家不共享,是又能共享又要保护,是这样一个双重目标。
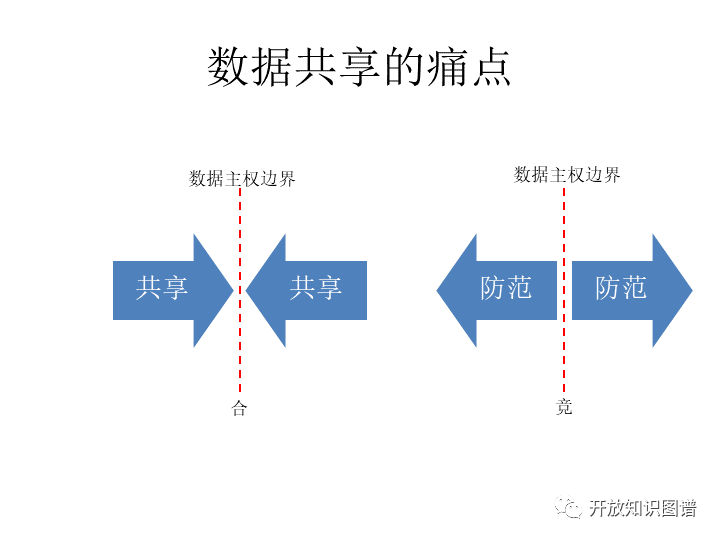
也就是说我们承认不同的数据的 owner,数据之间是有主权边界的,但是他们也有共享的需要。同时他们又是互相防范的,也就是说这里面有竞有合,是一个竞合同时存在的博弈。
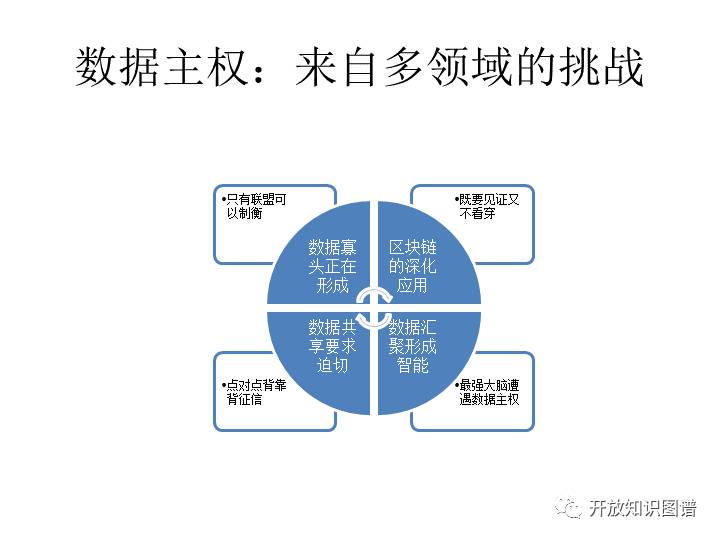
数据主权体现在方方面面。区块链的这个深化应用,包括我们央行推出这样一个加密数字货币,这里边肯定是不希望老百姓的各种花费让别人都能看见,它是要保护隐私的。这个跟比特币目前的做法是肯定不一样。那么从防止数据寡头的角度看,一定要有一个联盟机制,使得大家互相承认边界互相共享。这个边界是一个能够通过一种信任关系给你保证,不会让你眼看着这个数据寡头长起来我们却没办法,比如区块链基础上加上一定的密码学的机制,可以形成一个信任关系。征信,这个就是我的数据别的地方你看不到,但是在你想要的那一点上,我们可以有一种方法去对缝,就是一个比特一个比特的泄露。然后最后一点,讲人工智能。人工智能就是形成所谓的超级大脑,但前提都是说我要拿大规模的数据去喂它。那大规模数据较集中,一集中,我的数据你的数据都集中到了一起。这时,你把我的数据拿走,我再把你的数据拿走,发生这种情况怎么办?这个是在技术上还是挑战蛮大的。如果说我们给一个程序,我们把我们各自的数据给一个程序,这都是没关系的,让这个程序有超级的能力,这个关系并不大。但是如果因此我的数据你就能得到,你的数据我就能得到,那么这个事就严重了。所以说又要汇聚让它,形成一个集中的智能,同时又不让这个汇聚的副作用变成一种各自的隐私或者各自的一些核心数据的泄露。
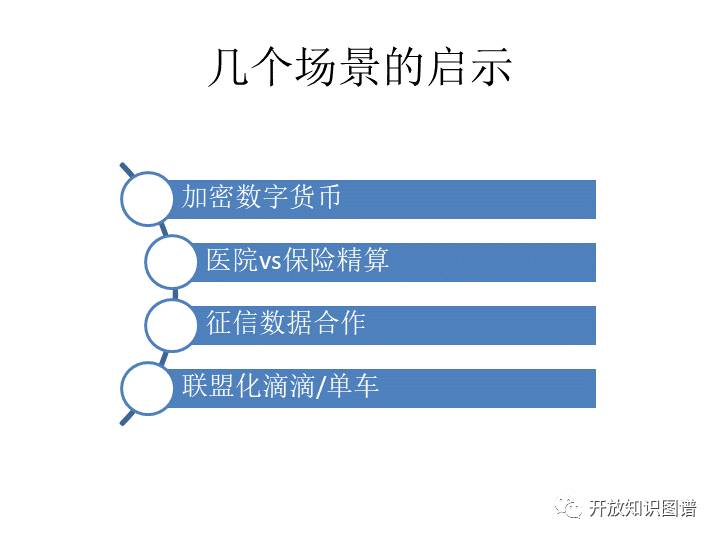
这里面有几个例子,第一个,加密数字货币。第二个例子是医院和保险公司。保险公司要做精算,比如就算某一个病的死亡率,然后他没有数据,那么他去找医院。医院说冠冕堂皇,认为这个数据是患者的,我只是替患者保管,但实际上他是有操控这个数据的全部能力的,但是他说不给。这就比较麻烦。那么保险公司怎么样能够在承认医院边界的情况下把像死亡率这样的一些数据拿到手?第三个例子,征信,我们已经说了。第四个例子也是我们有些很大胆的朋友提出来的,能不能做这个去中心化的滴滴或者共享单车。意思就是说不需要滴滴这样一个公司。乘客的位置信息和司机的位置信息是统一的,然后就直接拿这个东西去撮合。也就是不经过滴滴这样的一个平台公司,但是又有这样一个平台去做这样的事情。能不能做成我不知道,但是其中可能还有一些法律障碍。但是如果不是说个人,而是有一些中小规模的约车公司以联盟的方式形成一个虚拟的滴滴,然后各自的用户、各自的司机互相不透露,同时又给一个平台来做信息调度,需要的信息给足这个平台,这事能不能做到,也是一个值得探讨的问题。当然这个问题在这个学术界叫做这个多方安全计算,它涉及到几种不同的场景,安全的汇聚,安全的关联,安全的映射等等。
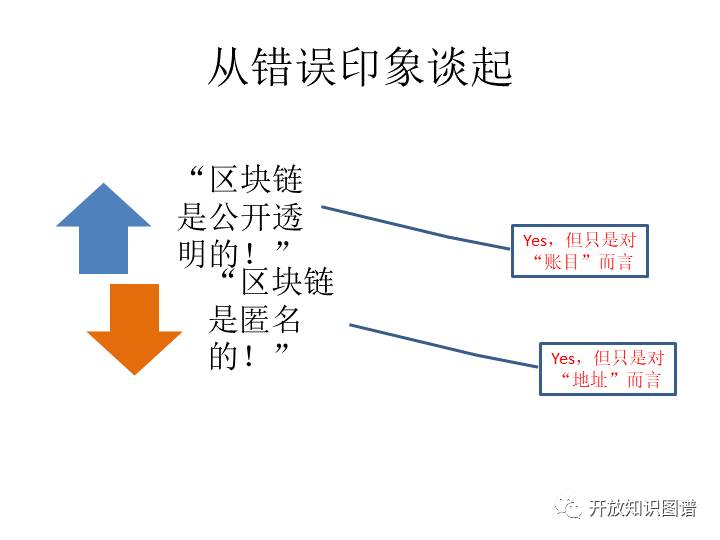
有人说区块链是公开透明的,也有人说他是秘密。这都只说对了一半,这账目是透明的,这个账户或者地址是匿名的。那光看那个账户,如果账目是透明的,操作手法也是透明的,其实有很多的这种线索你是没有办法回避的,那么用的那个身份就暴露出来的。同一个地址,是同一身份,然后你用不同地址,如果关联交易是你发起的,也能发现。还有趋同交易,你的手法是一样的,这就是趋同交易。这也是能发现的。这个我之前在交易所做这个抓坏人的工作,所以这个我们都知道。账目其实也面对着两个方向,从法律法规,从个人权利,从这个无关人回避等等希望这个数据背靠背的,但是去中心化和集体见证又都希望这个是面对面的。如果需要同时满足这两个怎么办?就是我又要集体见证去中心化,同时又要保护个人隐私。那么就有一些办法,实际上可以把这个事件时序的见证和有效支付的见证区分开。然后就有一些保护隐私的各种各样的办法。所以保护隐私其实就是想同时满足了这样的情况,一个是尊重你的边界,那个同时呢要实现必要的共享。
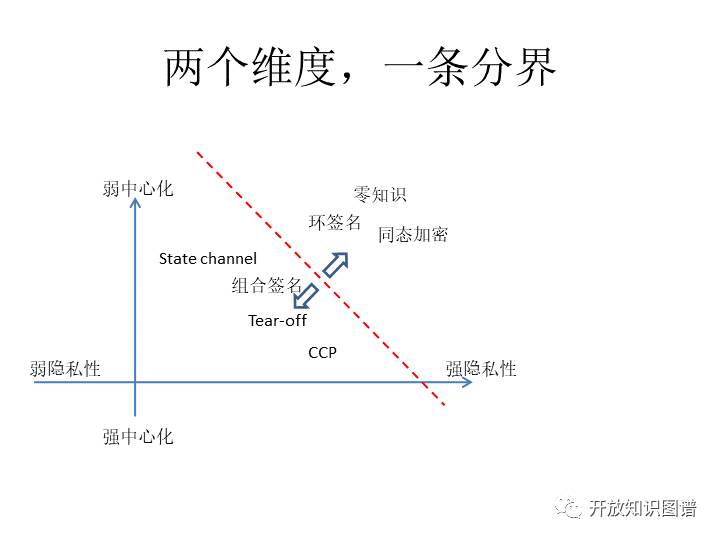
在这幅图中,虚线的上方是比较理想化的,但是目前还没有很好的效率。虚线下方是有所提升的方面,比如去中心化方面有所提升的,或者是隐私性方面有所提升的。经过一些妥协后,这就是很优雅的,也很完美的,但是可能实现效率稍微差一点的方案。这里边有零知识,零知识交互,零知识证明这个我们不详细讲了。Zcash开始就是他的一个实现,用零知识方式的一个实现。那么Zcash这样一个币里边交易多少钱你是看不到,但是大家又能放心的给他们的交易去见证,去给他们背书。这是一种方式,那么还有一种叫同态加密。同态加密也是通过一种保运算的加密映射来做的,这个很优美,但是实现效率可能还是达不到生产要求。
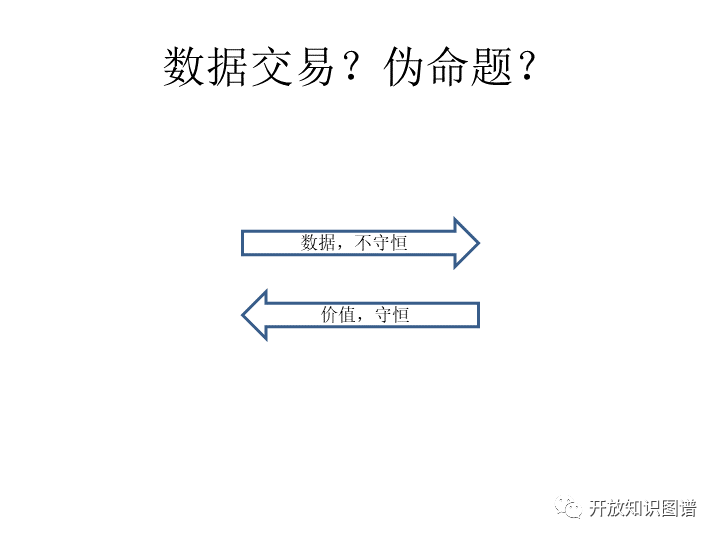
那么往下说,数据交易。有很多地方都有所谓的大数据交易中心。这个大数据交易那不是就是在做数据的共享吗?那么如果说做了大数据交易,是不是我们说的这个问题就解决了呢?我们从交易本身这个本身这个逻辑上看,交易是等价的一个交换,而价值它是满足守恒性的,但是我们的数据是不满足守恒性的。一个不满足守恒性的东西和满足守恒性的东西,互相之间怎么进行交换?这个命题自身就不太对头。而且裸数据交换也确实是不对,这个大家有很多的痛点,担心扩散,担心泄密的,担心数据的权属等等。

那么就换一种方式。也就是说我们不交易数据本身,我们交易这个数据的使用权 API。也就是我不卖 x 了,我卖f(x)。借助区块链来实现卖 f(x) 的一个想法,就是说大家把这个服务暴露出来,怎么调用,调用了多少,互相都是可以记账的。那么记账是落在区块链上,记下来的账,可以通过银行转账来付费。如果大家互相互认,也可以通过区块链上的代币来直接付费。那我有一部分知识图谱,你有一部分知识图谱,我也希望有分享的部分,同时我也不希望我的图谱你全拿走,那么至少有一个计量,在计量的基础上,我们也是要考虑等价性问题。
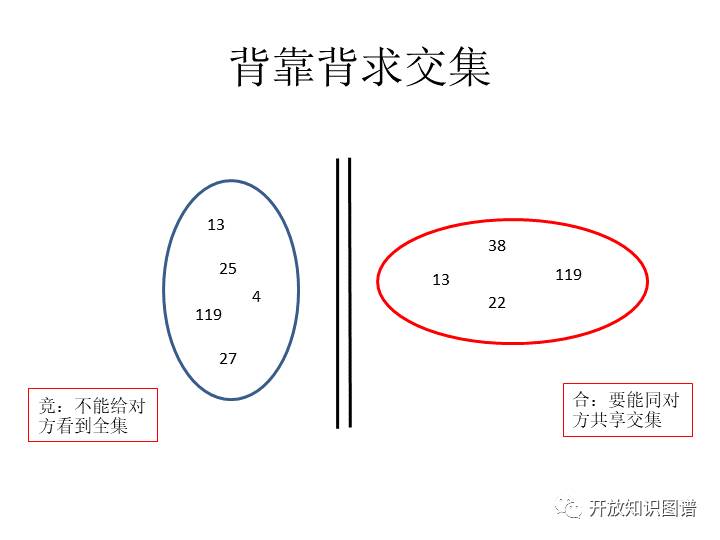
这里边还有另一个场景就是背靠背求交集。这个比较典型的案例,我们经常遇到的。之前就有这个两大著名的互联网公司,各自有一大批这个手机注册的账户,他们希望对手机号码的交集的部分互相推送一些服务。想法很好,但是为了求交集,我的集合要拿出来,你的也要拿出来,但是互相都不放心,担心整个数据被对方拿走。最后这个场景有两种做法,第一种做法,给第三方。第三个当然是签署保密协议,可是再怎么承诺,如果第三方不遵守承诺,这就是一个最糟糕的结果。那么还有一个最没面子的方法,就是大家把各自数据集带到一个固定的场所,机器都清空,重新格式化重新,然后求交集的代码,双方工程师认证检查好了,最后开始求交集。虽然方法很土,但是互相不信任就没有好办法。
我们现在有一个专利技术是可以解决这个问题的,而且互相之间可以放心,并且不会有第三方。我把数据加扰了给你,你再加扰给一个智能合约,这是我的数据。你的数据也是你加扰了给我,我再加扰给这个智能合约,然后那个智能合约就把这事做好了。整个过程谁也没有数据的全集,而且你想用一些套取的办法,比如不拿真实数据去跟你做交易,同样也不会暴露。
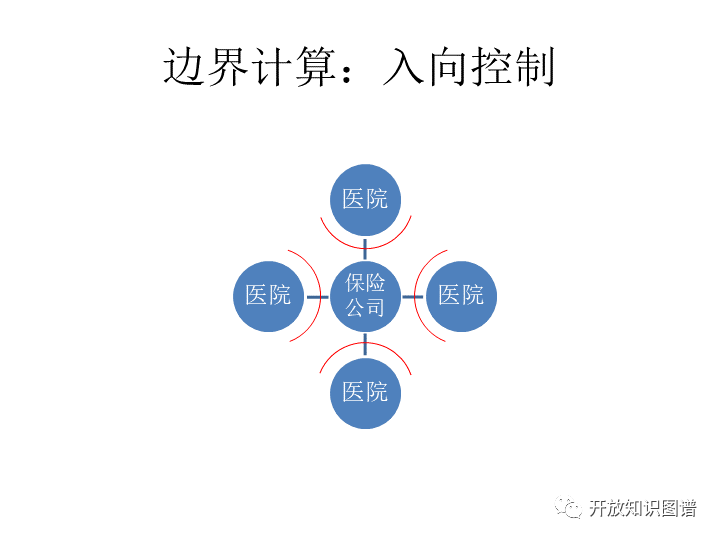
边界计算的入向控制。医院和保险公司之间数据往来,有所谓边界计算的问题。那么实际上这个问题是这样的,它就是看你要计算这个函数本身,如果具有某种所谓的aggregation,这种聚合性质,那么实际上就可以把一部分计算放到别人的边界里面去算。算个七分熟,然后再把那个剩下三分再送到一个保险公司计算。那么当然,这需要它本身确实有这种聚合的性质。再换个说法,就等于说有一部分计算是放在别人的边界里面去,然后脱敏,脱敏以后来聚合。如果本身的目的不是汇聚的时候就不能这么做。比如那种大的矩阵运算,那可能你分成块了以后,这个矩阵运算就成立了,而有可能在别人家算就不成立了。这个完全是有可能的,所以这个不是说对什么场景都是灵的。
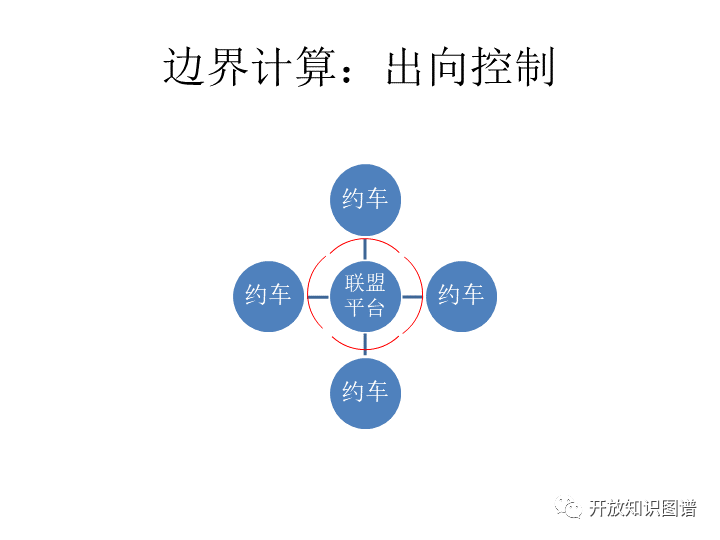
出向控制。这个说的是约车的约束问题。物理学家张首晟对这个也很关心。他也推荐一个算法就是所谓的同态加密。我们在同态加密的这个状态下,就能够把这些调度的问题都解决。但是这个也也许可以换一个思路,因为我们不怕把这个数据给程序,我们怕的是别人通过给程序再把数据拿走,那么只要把后者的路给堵住就可以。具体怎么做还会有其他的做法,那么刚才说的这些都是说有边界又要共享,又要防范的时候怎么办,这个思路供大家参考。那如果我们要成立这样的一个联盟,有很多人自带数据,自带一部分图谱,然后大家形成合力,然后又要尊重各自的边界怎么办?那么区块链和依托区块链上面长出来的一些密码学的技术加起来,可能会解决这一个问题。目前至少在区块链领域里,既关注区块链,又关注数据共享的人中,有一些人就在思考这样的一些问题,包括一些顶级的密码学家。这是第一部分的介绍。
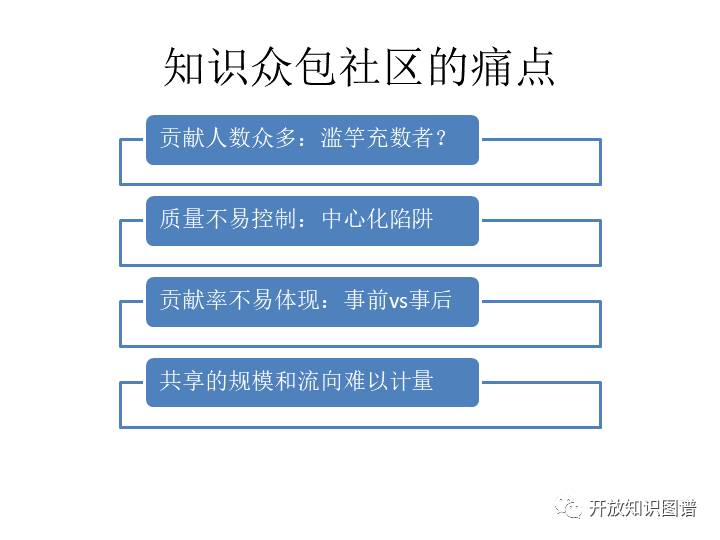
接下来我们进入知识众包社区这一部分。在我们会面临的一些问题中,主要还是激励的问题。当我们公布这个事情时,号召力还挺大,很多人都进来了,号称是我们的成员,号称是众包的一份子,但是有些成员出工不出力。我们不清楚他们的贡献度如何,很可能就是滥竽充数,那么这个时候我们怎么能够识别出来,审视图谱质量。在这种情况下一个成员的图谱质量好或者不好,谁说了算?如果最后又回到一个中心化的质量控制的团队,那么这个质量控制团队本身会不会又面临一些道德风险,会不会又面临一些他们自身的知识的局限导致的可能不如人民群众聪明?第三个问题就是,那这个就算是做好了,那是不是谁的数量多,那谁的贡献就大呢?也不一定。那是不是有事前的贡献,就是你做了多少活,交了多少东西,还有事后的贡献,就是用户用了你的,还是用了别人的。这也是一个问题。最后,到底是怎么共享的?纯粹的用户还有各个建设者互相之间看中了图谱,那么如何去计量使用量。图谱的一些流向和规模到底是怎么去计量,这个计量背后可能也是跟激励有关系的。
开源是不讲激励的。通常情况有个相应的基金会,有人打赏,有人干活。但是这是过去时,那么现在有了区块链,其实已经有很多这样的尝试,把区块链提供的一些跟激励有关的机制和这些众包的工作机制能够有机地结合起来。

我们大概有这么近几个建议的结合点,第一个就是要通过代币进行打赏。大家的成果记载在区块链上,同时这个区块链上要跑一种代币,而这个代币就成为打赏大家的一种价值工具。这是这第一个建议。
第二个建议是在质量控制当中引入竞争和共识。这个也是通过区块链,我们得到一些启示。比如说挖矿,很多人在算同一个反解这个哈希函数的一个题。那么最后谁最先发出来了,那么他一广播,然后别人看这个时间戳是最新的,那诚实记账的人就承认他,那么在这个短暂的瞬间也会有其他的一些人,它不是最新的时间戳,但是在它的局部,可能别人觉得它是最新的时间戳,但随着这个信息的传播发现不是,那么后续就改过来了。其实这就是一个版本问题。那么我们比如说发布知识图谱的编辑任务,或者是其他任务的时候,那也可以引入竞争。时间不一定是唯一的尺度,那么我们可以交叉评审,我们可以有用户反馈等等,这些都计算在内,整个尺度会比较长,版本也会比较多。但是尽管版本多,如果最后能够形成共识,而且形成共识以后就收敛到一个什么样的设定,那么其实这样一个过程就是跟区块链挖矿的过程很有可比性了,只不过它可能拉的时间更长一点。我们需要把这个机制设计好,就是版本控制,质量的控制,然后达成共识
第三个是计量。就是对大家的有效工作的衡量。我们希望能有一种不可更改不可撤销的方式记录下来,那么这个区块链也是长项,就是做这种存证。
第四个,实际上是大家最担心的,就是如何防止有价值的数据扩散到联盟外部。我们作为联盟内部,我们还有一个规范,那么如果扩散到联盟的外部,就不可收拾了。那么怎么样做这件事情,再结合刚才的大数据交易,我们可以考虑这样一个方式。就是对所有长在这个区块链上的知识图谱数据的使用,只有一个单一的入口,就是区块链服务这样一个入口。比如说谁使用了,肯定有使用的痕迹,这个痕迹就留在这个区块待着。“肉烂在锅里”也没问题的,但是不能出去。但是这个也可能发生拖库。那么为了防止拖库的话,我们能不能采用一种这个非线性定价的方式。也就是数据的使用定价是指数的往上涨不是线性的,让拖库的行为得不偿失。
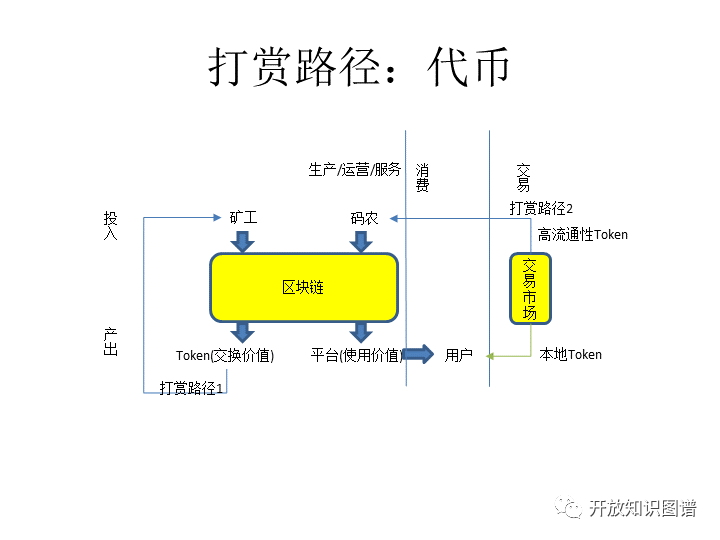
我们再具体展开一下,先说打赏。打赏在区块链这一领域经历了两个阶段,前一个阶段是没有应用,只有币。在没有应用只有币的情况下,等于说矿工用算力挖出来币,然后这个币是在别的地方体现出价值,比如它去买批萨,买这个军火等等。那么到了第二阶段,这个上面长出来应用,长出来这个平台,那么也长出了智能合约。到了这个时候又出现一个新的可能性,就是说拿这个平台上的币去获得那些长出来的应用的使用权,也就是说使用价值和它生产交流的交换价值在同一个平台里边就有了交换。所以这里面生产者是两类人,一类是矿工,一类是码农。那么打赏也是两类人,不是只打赏矿工,同时也要打赏码农,也就是所谓的ICO,就是通过代币的发行,然后再做对码农的打赏。那我们这个数据的生产者其实某种意义上跟码农是非常类似的,我们把生产出来的数据就放在上面,它有使用价值,那别人使用它,就要支付交换价值,然后在这个部门就会转起来,那么就要打赏这些提供使用价值的人,这个形成了一个闭环。

再说竞争和共识的问题。虽然是同样的一个任务,但是有不同的人在同时做不同质量的东西。那么经过大家大浪淘沙,不管用什么方式,用交叉评审的方式,用用户反馈的方式等等,只要最后确立了某一个版本的优势,那其他的版本消亡,而这个粗的箭头也就是确立的这一版本会发展下去。那么类似比特币挖矿,我们也希望好的知识图谱的版本也是这么演进的。
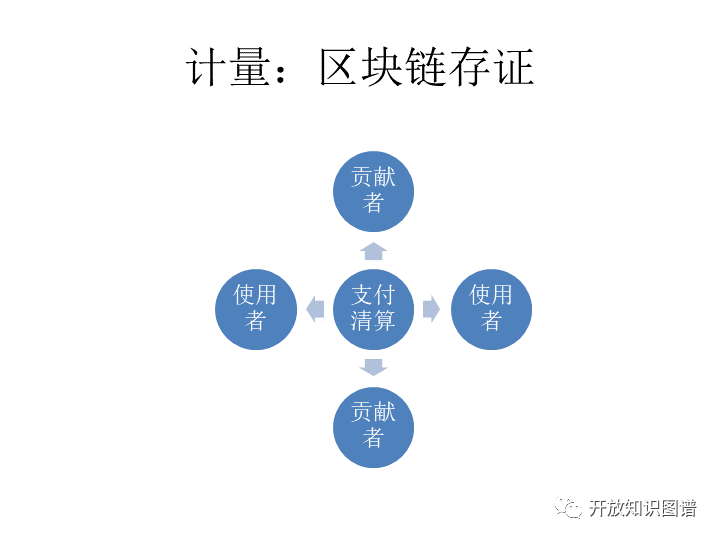
第三个,存证。这里面其实是两部分,一部分是纯使用者,那么他们使用了什么数据,这个是要有计量的,在计量的基础上我们才能计算让他支付多少。那么还有一部分就是贡献者互相之间的使用,那这不是一个简单的使用和支付的问题,还有清算的问题。也就是互相之间会比较,有一个抵消的过程。
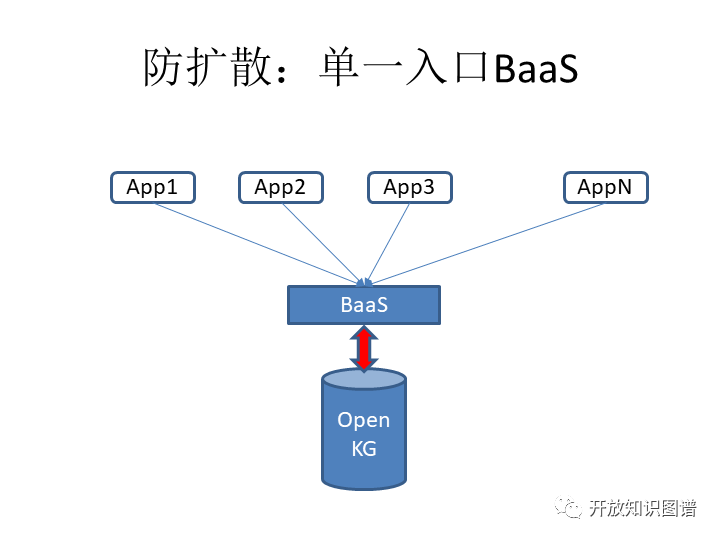
第四个是防扩散。我们希望比如说 OpenKG 是长在这个区块链机服务的一个总的入口的后面,大家所有的使用这里面数据的记录都是都是记录在案的。这样的话,在上面一些应用都是通过这个入口来调用。这是一个示意图,但是可能具体的架构比较复杂,在这先提出这样一个模型。这个模型是直接涉及到我们互相之间打赏的具体制度的安排的。
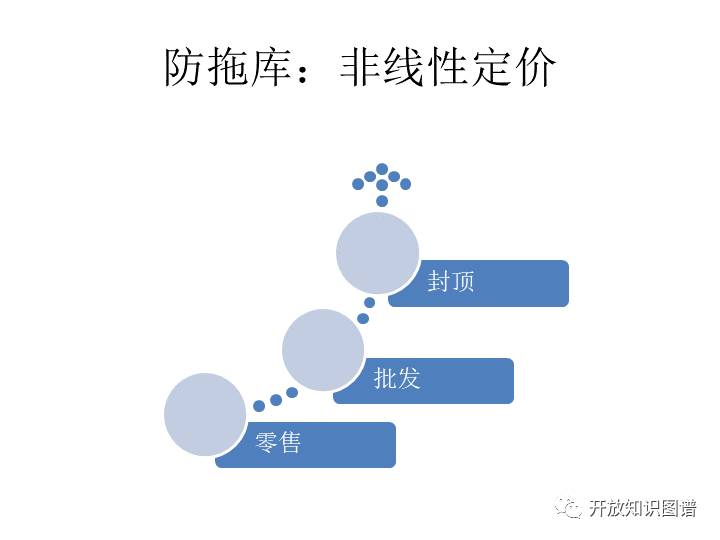
第五个是防拖库。也就是考虑使用非线性定价。那么不论是零售还是批发使用数据,都要有一个封顶,不能到一个离谱的量级。这样的话保证我们这个库是安全的,不会有恶意的拖走。
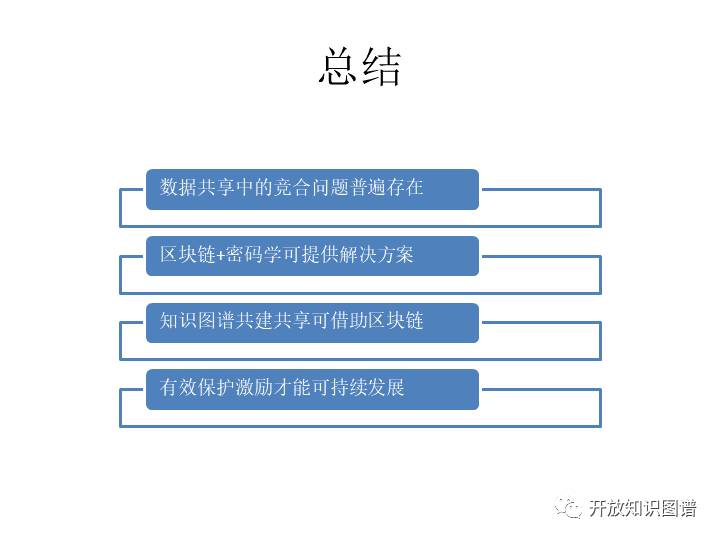
最后总结一下,第一个认识,就是数据共享当中这个竞合博弈问题是普遍存在的。目前大家见到的现有的区块链上面的这些技术还不足以完整的提供解决方案,还得追加上的一些比较高级的密码学技术才行。第三个就想跟大家说,知识图谱如果共建共享,那可能一个核心的问题就是说要保护它的价值,要体现它的价值。保护价值,当然就有一些互相这个防范的机制。体现价值,那么就要有一个这个所谓的像代币激励的机制。既有有效的保护,要有有效的激励,那么我们才能够可持续的发展。虽然是OPEN,按说是不谈钱的,但是在现在这个时,代币已经无孔不入,其实它是一个很好的工具,如果我们能够比较好的使用,我相信能够帮助我们更健康的发展好,谢谢!
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。
)


















