硅谷教父凯文凯利在他新书《必然》中谈到了网页 2.0:“…今天的网络就是所有可以访问到的超链接文件… 但在未来的 30 年中…超链接的触手会不断延伸,把所有的比特连接起来。一个主机游戏中发生的事件会像新闻一样搜索即得。你还能寻找一段 YouTube 视频里面发生的事情…超链接还会延伸到实体中…把一块几乎免费的小芯片嵌入到产品中,就能让你对你的房间,甚至整栋房子展开搜索…”。
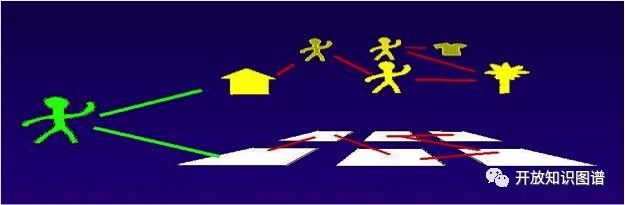
互联网是以链接为中心的系统。在未来的世界里,超链接会无处不在。从链接文件,到链接不同的数据库,到链接文本、图像、视频和音频中的事物,到链接各种设备、传感器和万事万物。链接的对象范围越来广,粒度也越来越细小,并被不但植入和延伸到各种不同的设备当中。
早在 1945 年,美国人 Vannevar Bush 提出了一个称为 Memex 的“记忆机器”(Collective Memory Machine),目的是让人们更加容易记录和访问知识。Bush 认为人脑记忆偏重“关联”和“连接”,而不是基于“索引”或“层次化”。 Memex 模拟了人脑记忆的这种特点,并启发了超文本(Hypertext)和万维网(World Wide Web)的发明。
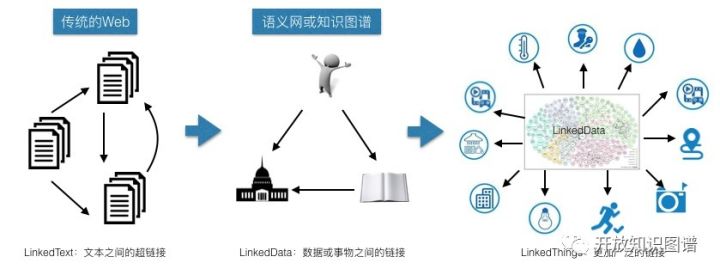
1989 年,万维网之父 Tim Berners-Lee 提出构建一个分布式超文本系统,并把它命名为 Web。在这份建议书里,他提出要构建一个基于“链接”的信息系统(Linked Information System)。这个系统以“链接”为中心,并能在开放的互联网环境里面逐步演化、生长和扩大链接的范围。他认为这种基于图和链接的组织方式,比起基于树的层次化组织方式,更加适合于互联网这种复杂开放的系统。这一思想逐步被人们实现,并演化发展成为今天的万维网。

1994 年,Tim Berners-Lee 又提出,Web 不应该仅仅只是网页之间的互相链接。实际上,网页上所描述的是现实世界中的个体对象和人脑中的概念。网页之间的链接实际包含有语义,即这些个体对象或概念之间的关系,然而机器却无法有效的从网页中识别出其中蕴含的语义。如果人们在发布这些信息时,就建立对这些个体对象和关系的语义描述,再加上互联网的开放网络扩张效应(Network Effect),就能涌现出一个全球互联的“数据互联网”。
他于 1998 年提出了语义互联网(Semantic Web)的概念。语义互联网仍然基于图和链接的组织方式,只是图中的节点代表的不是网页,而是个体对象(如:人、机构、地点等),而超链接也被增加了类型描述,具体标明对象之间的语义关系(如:出生地是、创办人是等)。相对于传统的网页互联网,语义网的本质是(结构化)数据的互联网。Tim Berners-Lee 希望人们都能用尽可能标准和规范的方式发布自己的数据,并像建立超文本链接一样建立数据之间的链接,从而构建一个庞大、分布互联的全球数据库。这种结构化的链接数据将使得Web上的信息更加易于被机器所理解和处理,而不仅仅像网页那样只是供人浏览。
如今,语义互联网早期关于建立数据或事物之间链接的设想正被知识图谱一步一步实现。知识图谱本质上也是一种以链接为中心的系统。而这种以链接为中的系统从早期的文本之间链接逐渐发展为数据之间的链接、事物之间的链接、设备和万物之间的链接。正如凯文凯利所指出,网页链接的触角正在飞速的扩展,链接对象的粒度越来越细小,链接的范围也越来越大,并变得无所不在。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。




![]搜索引擎的文档相关性计算和检索模型(BM25/TF-IDF)](http://upload.wikimedia.org/wikipedia/zh/math/b/0/6/b06a060c28253c8dd2528811c447862e.png)