文 | 子龙
自GPT、BERT问世以来,预训练语言模型在NLP领域大放异彩,刷新了无数榜单,成为当前学界业界的心头爱,其主体结构——Transformer——也在逐步的运用于其他领域的任务中,常见的如与CV的跨界,也有相对小众的bioinfo的任务(如蛋白质分类),然后此时问题来了,NLP领域技术成熟数据丰富,相比之下,其他领域或许不那么充足,那么曾经在 文本 数据上预训练的模型对 模态 有没有迁移作用呢?
今天的文章 Pretrained Transformers As Universal Computation Engines 就探索了文本模态预训练对其他模态的迁移作用,作者发现当模型学会了语言,对其他模态有着很好的指导作用,能够极大地提高其他模态任务上的学习效果。
论文题目:
Pretrained Transformers As Universal Computation Engines
论文链接:
https://arxiv.org/abs/2103.05247
Arxiv访问慢的小伙伴也可以在 【夕小瑶的卖萌屋】订阅号后台回复关键词 【0401】 下载论文PDF~
熟悉预训练语言模型或者迁移学习的读者应该已经意识到了,实际上,这篇文章的作者是将原本在文本数据上预训练的模型,在其他类型数据上finetune。以往我们通常强调,预训练一定要和下游任务相关联,然而这次的实验中,却可能需要将已经学会文本信息的模型用于鉴别蛋白质、识别数字,上下游任务风马牛不相及。
而且,为了凸显文本预训练的重要性,文中所使用的模型GPT-2在finetune阶段,将中间层层连接的Transformer层“冻结”,下游finetune的时候仅仅优化输入层、输出层、Position Embedding和Layer Norm Parameters。如此设计,用于非文本模态下游任务的语言模型最大程度上保留了文本预训练所得到的信息,也极大的减少了finetune时的参数。
文章将这种冻结中间Transformer层的语言模型称作Frozen Pretrained Transformer (FPT),具体结构如图所示:
作者在文章中研究了FPT相关的12个问题,限于篇幅,这里选取了其中6个问题(方括号内为原文标号):
文本预训练模型真的可以迁移到其他模态吗?
[3.1]预训练用哪种模态重要吗?
[3.2]文本预训练与随机初始化相比能够提高训练效率吗?
[3.4]模型表现会随着模型大小提升吗?
[3.7]在finetune阶段哪些参数最为重要?
[3.10]在其他语言模型上,这样的结果可以继续保持吗?(文章主要使用的是GPT-2)
[3.11]
文本预训练模型真的可以迁移到其他模态吗?
这正是文章所关注的最主要的问题,从海量文本训练出来的文本模型在毫不相干的下游任务上finetune效果如何呢?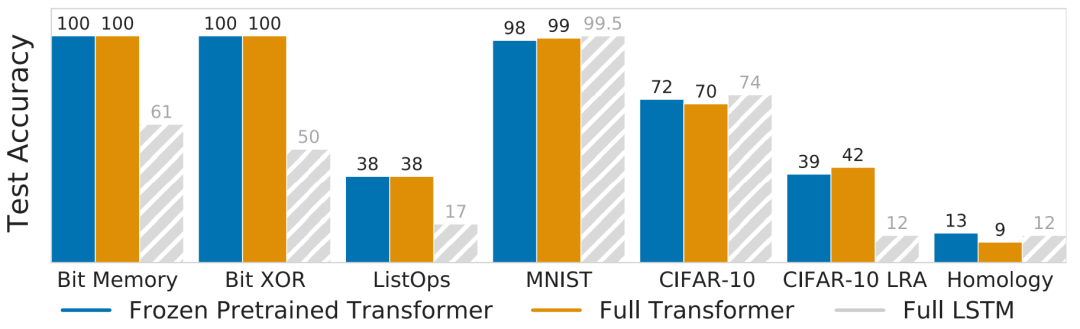
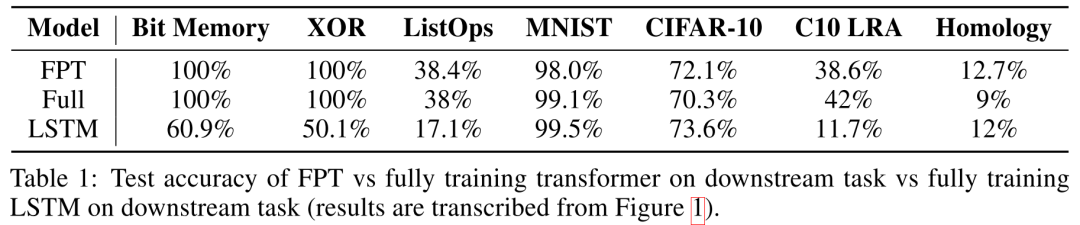
文中所涉及的几个任务:Bit Memory和Bit XOR是基于bit string的任务,分别要求模型恢复masked bit string和计算两个bit string的异或值;ListOps是预测一串操作的结果,如;MINST是手写数字识别;CIFAR-10和CIFAR-10 LRA(C10 LRA)是常见的图片识别数据集和Long Range Arena提出的变种,主要改变的图片序列化的方法,具体可以参见往期Transformer哪家强?Google爸爸辨优良!;Homology是预测蛋白质折叠。
参与比较的几个模型:FPT是文中所关注的冻结Transformer层的预训练语言模型,Full是全部参数参与finetune训练的语言模型,LSTM是全部参数参与训练的长短时记忆网络。
从结果中可以看出,FPT在各个任务上都有着和全参数参与训练的Full有着相近的能力,甚至在一些任务上有着更优的表现,说明在文本上做预训练的语言模型对于其他模态的任务有着一定的迁移能力,可以选择冻结部分参数而不影响效果。
预训练用哪种模态重要吗?
接下来文章考察的问题是模型迁移能力与预训练模态的关系,此前的FPT都是在文本上做预训练,这是由于文本预训练资源最为丰富、方法最为成熟。然而,近些年多模态预训练模型也有着很多成果,如基于图片的视觉预训练模型等等。于是,这部分实验对比了在不同模态上做预训练的模型向其余任务的迁移能力,这里对比的主要有原本在文本上做预训练的FPT、在图片上做与预训练的ViT、在Bit Memory任务上做预训练的Bit和随机初始化的Random。 从结果中可以看出在文本上做预训练的模型FPT具有相对更好的结果,在多个任务上达到了最优,虽然在图片上做预训练的ViT能够在视觉任务(C10、C10 LRA)上超过FPT,但是在其他大部分任务上落后于FPT,尤其是蛋白质分类任务(Homology)上,FPT大大超越了ViT,作者猜测这是应该蛋白质序列和语言相近有着的所谓“语法”结构。
从结果中可以看出在文本上做预训练的模型FPT具有相对更好的结果,在多个任务上达到了最优,虽然在图片上做预训练的ViT能够在视觉任务(C10、C10 LRA)上超过FPT,但是在其他大部分任务上落后于FPT,尤其是蛋白质分类任务(Homology)上,FPT大大超越了ViT,作者猜测这是应该蛋白质序列和语言相近有着的所谓“语法”结构。
文本预训练与随机初始化相比能够提高训练效率吗?
预训练虽然有着优越的性能,但往往代价昂贵,虽然人人均知大力出奇迹,但是也只有大公司才可能烧得起经费,所以训练效率是finetune的重要指标,本身finetune就是希望利用到预训练的信息,进而规避昂贵的训练过程。于是,这部分实验中,作者对比了FPT和Random的拟合速度,即进行梯度下降的步数。 答案显而易见,FPT拟合数据集的速度相比Random有着极大的提升,更何况,参照前文有关预训练模态的实验,在Bit Memory任务上,Random (75.8%s)的效果远低于FPT (100%)。
答案显而易见,FPT拟合数据集的速度相比Random有着极大的提升,更何况,参照前文有关预训练模态的实验,在Bit Memory任务上,Random (75.8%s)的效果远低于FPT (100%)。
模型表现会随着模型大小提升吗?
我们平时使用的语言模型,往往有着不同的版本,比如Bert-base和Bert-large,XLNet-base和XLNet-large,一方面对模型规格的约定让模型间对比起来更加公平,同时也要求更大规模的模型意味着更优的性能,因为如果模型设计不够精准合理,增加模型规格,同时意味着更多的参数、更慢的拟合、更复杂的训练,可能效果还不及简单的模型。
于是,这部分实验中,作者设计了三种规格的FPT:small、medium、large,分别为12层、24层、36层,分别对比了这些模型在CIFAR-10任务上的结果。 从结果中可以看出,随着层数的增加,模型的效果在不断提升,这说明FPT的表达能力能够随着层数的增加而提高,也说明冻结中间Transformer层的手段并不会应该冻结层数的增加而影响模型在下游任务中的效果。
从结果中可以看出,随着层数的增加,模型的效果在不断提升,这说明FPT的表达能力能够随着层数的增加而提高,也说明冻结中间Transformer层的手段并不会应该冻结层数的增加而影响模型在下游任务中的效果。
在finetune阶段哪些参数最为重要?
FPT特别之处在于它冻结中间的Transformer层,而只对很小一部分参数进行优化,那么冻结哪些参数比较合理呢?这一部分实验考察究竟哪些参数对finetune比较重要,那么以后在下游任务中就可以有选择的进行优化。
首先,作者增加了Transformer层中的FeedForward层和Attention部分的参数进行finetune,结果如下。
进一步,对比了其他参数的效果。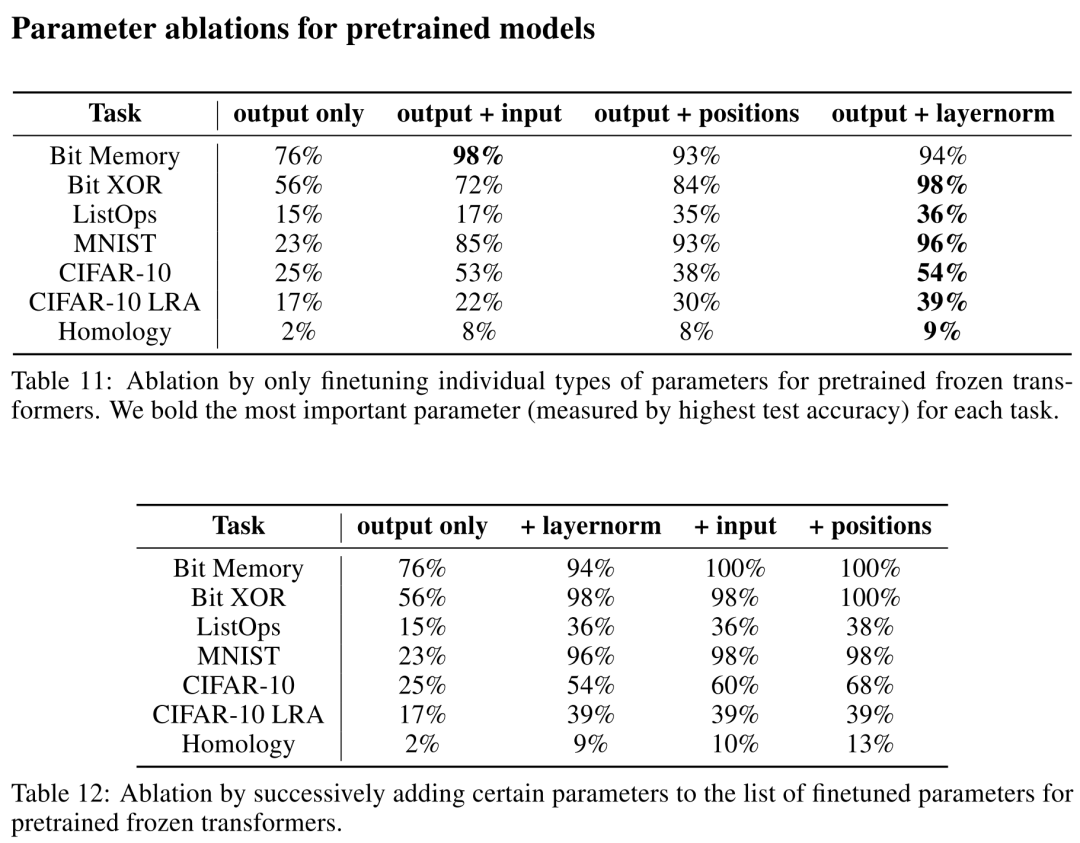
综合上述结果,增加FeedForward层确实能够提升效果,但是优化Attention部分参数却会分散模型能力,降低结果。此外,layer norm的参数对finetune结果最为重要。
在其他语言模型上,这样的结果可以继续保持吗?
本文作者提出的FPT是基于GPT-2的语言模型加上冻结Transfomer层的策略,而我们知道现在语言模型品种繁多、各有千秋,于是作者采取相同的冻结策略,考察了以上结论在其他语言模型中的情况。
对比实验中选取了BERT、T5、Longformer,这些模型各有侧重,BERT是autoencoder模型,T5是seq2seq模型,这里作者只用其中的encoder,Longformer是针对长文本提出的模型。从结果中可以看出,不同的Transformer结果对结果的影响不大,只有T5相比其他模型在ListOps上有所下降。
本文所涉及的实验众多,得到结果也十分丰富,从多方面考察了FPT的冻结策略对模型效果的影响,一方面启发了借助文本预训练对其他模态任务的迁移,另一方面也让NLPer对预训练语言模型的各个组件有了更加深刻的理解,了解他们各自对结果的贡献的区别,从某个角度上说,也让缺少显存的程序员放心冻结庞大的预训练语言模型的部分参数,而不必担心以效果换显存了。
萌屋作者:子龙(Ryan)
本科毕业于北大计算机系,曾混迹于商汤和MSRA,现在是宅在家里的UCSD(Social Dead)在读PhD,主要关注多模态中的NLP和data mining,也在探索更多有意思的Topic,原本只是贵公众号的吃瓜群众,被各种有意思的推送吸引就上了贼船,希望借此沾沾小屋的灵气,paper++,早日成为有猫的程序员!
作品推荐:
1.别再搞纯文本了!多模文档理解更被时代需要!
2.Transformer哪家强?Google爸爸辨优良!
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!