笔记整理:杨露露,天津大学硕士
链接:https://ojs.aaai.org/index.php/AAAI/article/view/16522/16329
动机
在不确定知识图谱的嵌入中,实体之间的每个关系都有一个置信度。鉴于现有的嵌入方法可能会丢弃不确定性信息,或只加入特定类型的得分函数,或在训练中造成大量的假的负样本,本文提出PASSLEAF框架来解决上述问题。
亮点
PASSLEAF框架的亮点主要包括:
1.提出结合不同类型的评分函数来预测关系置信分数的模型。2.提出通过利用与估计的置信分数相关的正负样本的半监督学习模型。
此外,PASSLEAF利用样本池作为生成样本的中转站,进一步增强了半监督学习。实验结果表明,本文提出的框架在置信度评分预测和尾实体预测方面都具有较高的准确率,能够更好地学习嵌入。
概念及模型
PASSLEAF框架主要包括两个主要部分:不确定性预测模型的建立和基于池的半监督学习。
不确定性预测模型的目标是利用现有的知识嵌入评分函数来预测(h, r, t)样本的置信度。本文分别为基于翻译距离和基于语义的方法设计了相应的分数映射函数,并为其配备了损失函数,以形成一个置信度感知的嵌入模型。
基于池的半监督学习框架提供了一种更好的处理未见过样本的方法来缓解假的负样本问题,不仅将不可见的样本作为负样本处理,而且重新评估其潜在的置信度。
此外,本文维护了一个最新的半监督样本池,利用过去的学习经验,使嵌入的学习质量更好。
模型整体框架如下:
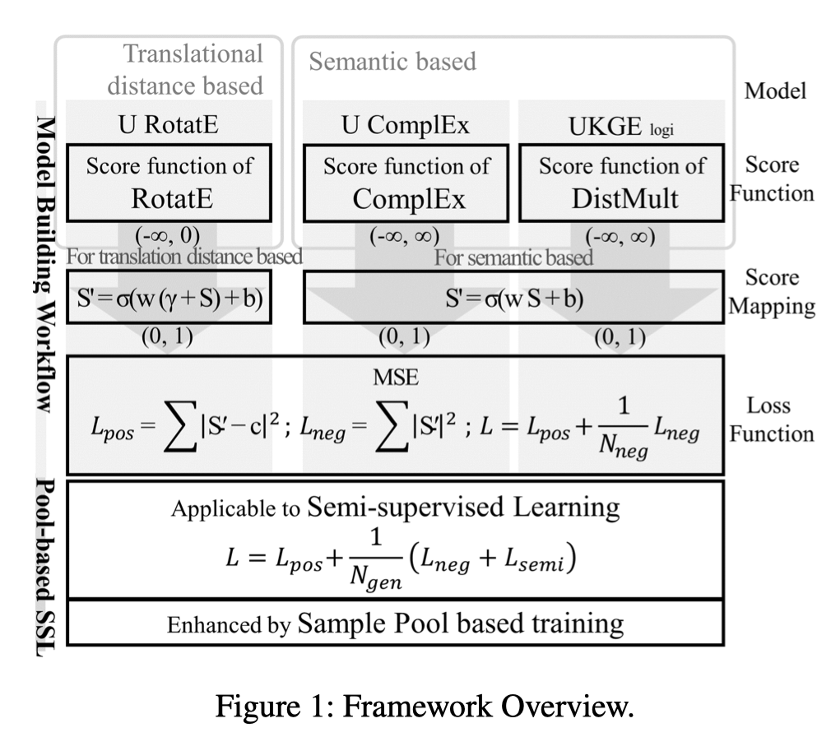
•模型构建流程
给定一个评分函数,PASSLEAF通过两步构建一个新的模型。
首先,根据评分函数是基于语义还是基于翻译距离的,评分函数将根据公式(1)和(5)所示的映射进行映射。
其次,评分函数和MSE损失共同构成模型。
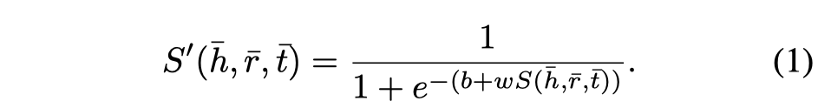

•半监督学习
半监督样本的选取方法与随机抽取的负样本相同,即破坏训练集三元组的头实体或尾实体。不同之处在于,每个半监督样本的置信度评分将由当前模型估计和指定,而不是归零。因此,它们可以是正样本的,也可以是负样本。这种半监督样本的选取方法缓解了假的负样本问题。
好处就是:一方面,随机抽取的负样本的重要性被稀释了;另一方面,半监督样本有望更好地估计未见过的三元组的真实置信度得分。此外,它还用作数据增强工具,特别是对于正样本。
半监督样本的MSE损失D_semi如下所示。

负样本和半监督样本的混合会带来最好的性能提升。因此,整体损失函数具体如下。

本文不使用上一步生成的半监督样本进行训练,而是应用一个样本池作为样本的中转站。
•样本池
PASSLEAF 维护一个样本池来保存 C 个最新的半监督样本。对于训练阶段i,需要采取两个步骤。首先,应生成 N_new (i) 个样本并将其存储到样本池中。
其次,根据(10)所示的损失函数,从池中随机抽取 N_semi (i) 样本与N_gen-N_semi (i) 随机抽取负样本一起训练模型。为了减少计算开销,将在样本池中选择一个连续的样本带,而不是一个一个地抽取。
本文N_new设计为一个相对于时间的阶跃函数,将N_semi设计为一个剪切线性函数,它从零开始,线性递增,直到给定的最大值,具体如下。

其中,T_(NEW SEMI)和T_(NEW TRAIN)分别是开始生成半监督样本的时期和开始从池中获取样本的时期;M_SEMI是每一步半监督样本的最大数量;α决定了半监督样本数量达到最大值所需的时间。合理地说,T_(NEW TRAIN)必须大于T_(NEW SEMI),以积累足够的半监督样本用于训练。
不同时间步骤生成的半监督样本保留了从不同随机抽取的负样本中积累的经验。因此,基于池的设计可以看作是过去模型的集合,进一步增强了半监督样本的有效性。
实验
本文在三个开放的不确定知识图谱上评估模型:PPI5K、NL27K、CN15K,此外,还在两种流行的确定性知识图谱, WN18RR和FB15K237进行评估。主要使用置信度预测(CSP)和尾实体预测(TEP)两个任务进行评估。
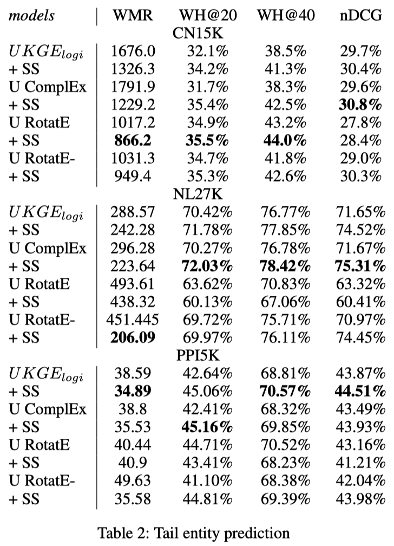
在三个数据集上的TEP结果如下表所示。在所有数据集上,具有半监督样本的模型在所有指标上都持续改进。特别是在NL27K上,采用基于池的半监督训练,U RotatE-的WMR降低了约50%,U ComplEx的nDCG提高了近4%。在CN15K上,有半监督训练的最佳模型的WMR接近无半监督训练的UKGE logi的一半。
对CSP的评估结果如下表。pos和neg分别为数据集内的正样本和随机抽取的负样本的MSE。+SS表示对上一行的模型进行半监督训练后的模型。
在应用半监督样本后,数据集内正样本的MSEs在所有模型和数据集上提高了五分之一以上。研究结果表明,基于池的半监督训练可以有效地缓解假的负样本带来的噪声,并进一步提高数据集内未见过的正样本的预测精度。

另一方面,负样本的MSE值在半监督样本训练后略有增加。这个结果是在意料之中的,因为这个实验的数据是随机抽取的负样本,本文认为这很容易出现假的负样本。事实上,稍高的MSE值可能意味着该模型能够检测假的负样本,这会引发人们对过度误报预测的担忧。然而,TEP的表现解除了这种担忧。可以说,这表明了其避免假的负样本和过去经验集合的优点超过了其潜在的误报影响。为了进一步支持这一论点,本文做了一个实验来确定负样本的MSE的界限。实验结果如下图。

这个扩展实验是为了找到潜在误报的上限。在不同的每步最大半监督样本数M_SEMI下,测试不确定的ComplEx模型。第一列中的值表示 M_SEMI 在每步生成的样本数中的比例,默认值为 0.8,值为0表示没有半监督样本。相反,在 M_SEMI=1.0下,在给定的训练步骤之后不会使用随机抽取的负样本,这是最极端的情况,容易出现误报。结果表明,即使在极端情况下,负样本的MSE仍然是可控的。
同时,本文以不确定的ComplEx模型为例来展示 PASSLEAF 模型发现的一些缺失的三元组。实验结果如下图,如果不应用半监督样本,就找不到它们。尽管假的负样本预测似乎很多,但通过基于池的半监督训练发现了更多的缺失三元组。

为了评估样本池对改进的贡献,本文将基于池的半监督训练与没有样本池的朴素方法进行比较,其中半监督样本在上一步生成。两种模型具有相同数量的N_semi。基线是一个没有任何半监督样本和朴素方法的消融模型。CSP和TEP的结果分别见下表。


为了证明不确定知识图谱量身定做的模型确实超过了不确定知识图谱上的确定性模型。本文将PASSLEAF方法与它们的确定性的对应方法进行比较。应用确定性的知识图谱方法需要进行二值化。因此,对每个阈值都要训练单独的模型,而只有一个不确定的嵌入模型。下图显示了几个二值化阈值下的结果。为了简单起见,只显示了不确定的ComplEx和ComplEx。

在NL27K和PPI5K上,不确定的ComplEx在大多数指标和阈值上一直优于ComplEx,这支持了PASSLEAF模型能够更好地处理不确定性的观点。此外,除了PPI5K,它们在WH@K和nDCG中的性能差距保持相对稳定。然而,在WMR中,在大多数数据集上,随着阈值的增加,差距扩大了。本文认为这是因为PASSLEAF模型保留了低可信度的三元组作为额外的信息来源。
总结
PASSLEAF概括了建立不确定的知识图谱嵌入模型的过程,并通过避免假的负样本和整合之前的时间步骤学习的经验来提高性能。未来的研究可能基于样本池样本大小函数的设计、超参数的选择和更复杂的损失函数。此外,本篇论文的想法也可能有利于确定性的知识图谱,这是另一个值得研究的课题。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。