1.什么是arc?(arc是为了解决什么问题诞生的?)
首先解释ARC: automatic reference counting自动引用计数。
ARC几个要点:
在对象被创建时 retain count +1,在对象被release时 retain count -1.当retain count 为0 时,销毁对象。
程序中加入autoreleasepool的对象会由系统自动加上autorelease方法,如果该对象引用计数为0,则销毁。
那么ARC是为了解决什么问题诞生的呢?这个得追溯到MRC手动内存管理时代说起。
MRC下内存管理的缺点:
1.当我们要释放一个堆内存时,首先要确定指向这个堆空间的指针都被release了。(避免提前释放)
2.释放指针指向的堆空间,首先要确定哪些指针指向同一个堆,这些指针只能释放一次。(MRC下即谁创建,谁释放,避免重复释放)
3.模块化操作时,对象可能被多个模块创建和使用,不能确定最后由谁去释放。
4.多线程操作时,不确定哪个线程最后使用完毕
2.请解释以下keywords的区别: assign vs weak, __block vs __weak
assign适用于基本数据类型,weak是适用于NSObject对象,并且是一个弱引用。
首先__block是用来修饰一个变量,这个变量就可以在block中被修改(参考block实现原理)
__block:使用__block修饰的变量在block代码快中会被retain(ARC下,MRC下不会retain)
__weak:使用__weak修饰的变量不会在block代码块中被retain
同时,在ARC下,要避免block出现循环引用 __weak typedof(self)weakSelf = self;
3.__block在arc和非arc下含义一样吗?
是不一样的。
在MRC中__block variable在block中使用是不會retain的
但是ARC中__block則是會Retain的。
取而代之的是用__weak或是__unsafe_unretained來更精確的描述weak reference的目的
其中前者只能在iOS5之後可以使用,但是比較好 (該物件release之後,此pointer會自動設成nil)
而後者是ARC的環境下為了相容4.x的解決方案。
所以上面的範例中
__block MyClass* temp = …; // MRC環境下使用 __weak MyClass* temp = …; // ARC但只支援iOS5.0以上的版本 __unsafe_retained MyClass* temp = …; //ARC且可以相容4.x以後的版本 4.使用nonatomic一定是线程安全的吗?()
不是的。
atomic原子操作,系统会为setter方法加锁。 具体使用 @synchronized(self){//code }
nonatomic不会为setter方法加锁。
atomic:线程安全,需要消耗大量系统资源来为属性加锁
nonatomic:非线程安全,适合内存较小的移动设备
5.描述一个你遇到过的retain cycle例子。
block中的循环引用:一个viewController
@property (nonatomic,strong)HttpRequestHandler * handler; @property (nonatomic,strong)NSData *data; _handler = [httpRequestHandler sharedManager]; [ downloadData:^(id responseData){ _data = responseData; }];self 拥有_handler, _handler 拥有block, block拥有self(因为使用了self的_data属性,block会copy 一份self)
解决方法:
__weak typedof(self)weakSelf = self [ downloadData:^(id responseData){ weakSelf.data = responseData; }];6.+(void)load; +(void)initialize;有什么用处?
在Objective-C中,runtime会自动调用每个类的两个方法。+load会在类初始加载时调用,+initialize会在第一次调用类的类方法或实例方法之前被调用。这两个方法是可选的,且只有在实现了它们时才会被调用。
共同点:两个方法都只会被调用一次。
7.为什么其他语言里叫函数调用, objective c里则是给对象发消息(或者谈下对runtime的理解)
先来看看怎么理解发送消息的含义:
曾经觉得Objc特别方便上手,面对着 Cocoa 中大量 API,只知道简单的查文档和调用。还记得初学 Objective-C 时把[receiver message]当成简单的方法调用,而无视了“发送消息”这句话的深刻含义。于是[receiver message]会被编译器转化为: objc_msgSend(receiver, selector)
如果消息含有参数,则为: objc_msgSend(receiver, selector, arg1, arg2, ...)
如果消息的接收者能够找到对应的selector,那么就相当于直接执行了接收者这个对象的特定方法;否则,消息要么被转发,或是临时向接收者动态添加这个selector对应的实现内容,要么就干脆玩完崩溃掉。
现在可以看出[receiver message]真的不是一个简简单单的方法调用。因为这只是在编译阶段确定了要向接收者发送message这条消息,而receive将要如何响应这条消息,那就要看运行时发生的情况来决定了。
Objective-C 的 Runtime 铸就了它动态语言的特性,这些深层次的知识虽然平时写代码用的少一些,但是却是每个 Objc 程序员需要了解的。
Objc Runtime使得C具有了面向对象能力,在程序运行时创建,检查,修改类、对象和它们的方法。可以使用runtime的一系列方法实现。
顺便附上OC中一个类的数据结构 /usr/include/objc/runtime.h
struct objc_class { Class isa OBJC_ISA_AVAILABILITY; //isa指针指向Meta Class,因为Objc的类的本身也是一个Object,为了处理这个关系,r untime就创造了Meta Class,当给类发送[NSObject alloc]这样消息时,实际上是把这个消息发给了Class Object #if !__OBJC2__ Class super_class OBJC2_UNAVAILABLE; // 父类 const char *name OBJC2_UNAVAILABLE; // 类名 long version OBJC2_UNAVAILABLE; // 类的版本信息,默认为0 long info OBJC2_UNAVAILABLE; // 类信息,供运行期使用的一些位标识 long instance_size OBJC2_UNAVAILABLE; // 该类的实例变量大小 struct objc_ivar_list *ivars OBJC2_UNAVAILABLE; // 该类的成员变量链表 struct objc_method_list **methodLists OBJC2_UNAVAILABLE; // 方法定义的链表 struct objc_cache *cache OBJC2_UNAVAILABLE; // 方法缓存,对象接到一个消息会根据isa指针查找消息对象,这时会在method Lists中遍历,如果cache了,常用的方法调用时就能够提高调用的效率。 struct objc_protocol_list *protocols OBJC2_UNAVAILABLE; // 协议链表 #endif } OBJC2_UNAVAILABLE;OC中一个类的对象实例的数据结构(/usr/include/objc/objc.h):
typedef struct objc_class *Class; /// Represents an instance of a class. struct objc_object { Class isa OBJC_ISA_AVAILABILITY; }; /// A pointer to an instance of a class. typedef struct objc_object *id;向object发送消息时,Runtime库会根据object的isa指针找到这个实例object所属于的类,然后在类的方法列表以及父类方法列表寻找对应的方法运行。id是一个objc_object结构类型的指针,这个类型的对象能够转换成任何一种对象。
然后再来看看消息发送的函数:objc_msgSend函数
在引言中已经对objc_msgSend进行了一点介绍,看起来像是objc_msgSend返回了数据,其实objc_msgSend从不返回数据而是你的方法被调用后返回了数据。下面详细叙述下消息发送步骤:
检测这个 selector 是不是要忽略的。比如 Mac OS X 开发,有了垃圾回收就不理会 retain,release 这些函数了。
检测这个 target 是不是 nil 对象。ObjC 的特性是允许对一个 nil 对象执行任何一个方法不会 Crash,因为会被忽略掉。
如果上面两个都过了,那就开始查找这个类的 IMP,先从 cache 里面找,完了找得到就跳到对应的函数去执行。
如果 cache 找不到就找一下方法分发表。
如果分发表找不到就到超类的分发表去找,一直找,直到找到NSObject类为止。
如果还找不到就要开始进入动态方法解析了,后面会提到。
后面还有:
动态方法解析resolveThisMethodDynamically
消息转发forwardingTargetForSelector
详情可参考 https://app.yinxiang.com/shard/s10/nl/146175/7925ae66-03f7-487c-83a7-26c519aa897b/
8.什么是method swizzling?
Method Swizzling 原理(方法搅拌?)
在Objective-C中调用一个方法,其实是向一个对象发送消息,查找消息的唯一依据是selector的名字。利用Objective-C的动态特性,可以实现在运行时偷换selector对应的方法实现,达到给方法挂钩的目的。
每个类都有一个方法列表,存放着selector的名字和方法实现的映射关系。IMP有点类似函数指针,指向具体的Method实现。
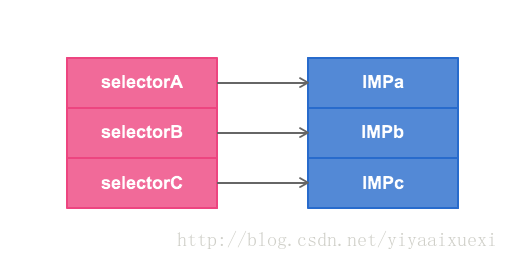
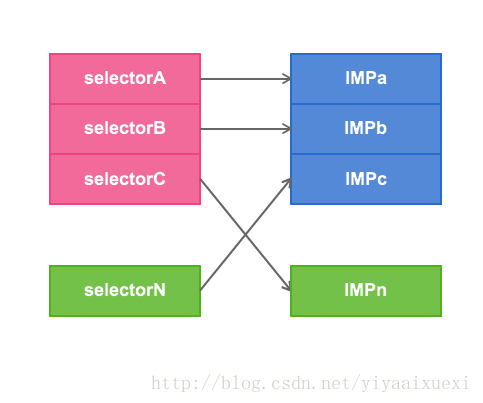
我们可以利用 method_exchangeImplementations 来交换2个方法中的IMP,
我们可以利用 class_replaceMethod 来修改类,
我们可以利用 method_setImplementation 来直接设置某个方法的IMP,
……
归根结底,都是偷换了selector的IMP,如下图所示:
详情:http://blog.csdn.net/yiyaaixuexi/article/details/9374411
9.UIView和CALayer是啥关系?
1.UIView是iOS系统中界面元素的基础,所有的界面元素都继承自它。它本身完全是由CoreAnimation来实现的 (Mac下似乎不是这样)。它真正的绘图部分,是由一个叫CALayer(Core Animation Layer)的类来管理。 UIView本身,更像是一个CALayer的管理器,访问它的跟绘图和跟坐标有关的属性,例如frame,bounds等 等,实际上内部都是在访问它所包含的CALayer的相关属性。
2.UIView有个layer属性,可以返回它的主CALayer实例,UIView有一个layerClass方法,返回主layer所使用的 类,UIView的子类,可以通过重载这个方法,来让UIView使用不同的CALayer来显示,例如通过
- (class) layerClass { return ([CAEAGLLayer class]); }=使某个UIView的子类使用GL来进行绘制。
3.UIView的CALayer类似UIView的子View树形结构,也可以向它的layer上添加子layer,来完成某些特殊的表 示。例如下面的代码
grayCover = [[CALayer alloc] init]; grayCover.backgroundColor = [[[UIColor blackColor] colorWithAlphaComponent:0.2] CGColor]; [self.layer addSubLayer: grayCover];会在目标View上敷上一层黑色的透明薄膜。
4.UIView的layer树形在系统内部,被系统维护着三份copy(这段理解有点吃不准)。
- 逻辑树,就是代码里可以操纵的,例如更改layer的属性等等就在这一份。
- 动画树,这是一个中间层,系统正在这一层上更改属性,进行各种渲染操作。
- 显示树,这棵树的内容是当前正被显示在屏幕上的内容。
这三棵树的逻辑结构都是一样的,区别只有各自的属性。
10. 如何高性能的给UIImageView加个圆角?(不准说layer.cornerRadius!)
我觉得应该是使用Quartz2D直接绘制图片,得把这个看看。
步骤:
a、创建目标大小(cropWidth,cropHeight)的画布。
b、使用UIImage的drawInRect方法进行绘制的时候,指定rect为(-x,-y,width,height)。
c、从画布中得到裁剪后的图像。
- (UIImage*)cropImageWithRect:(CGRect)cropRect { CGRect drawRect = CGRectMake(-cropRect.origin.x , -cropRect.origin.y, self.size.width * self.scale, self.size.height * self.scale); UIGraphicsBeginImageContext(cropRect.size); CGContextRef context = UIGraphicsGetCurrentContext(); CGContextClearRect(context, CGRectMake(0, 0, cropRect.size.width, cropRect.size.height)); [self drawInRect:drawRect]; UIImage *image = UIGraphicsGetImageFromCurrentImageContext(); UIGraphicsEndImageContext(); return image; } @end11. 使用drawRect有什么影响?(这个可深可浅,你至少得用过。。)
drawRect方法依赖Core Graphics框架来进行自定义的绘制,但这种方法主要的缺点就是它处理touch事件的方式:每次按钮被点击后,都会用setNeddsDisplay进行强制重绘;而且不止一次,每次单点事件触发两次执行。这样的话从性能的角度来说,对CPU和内存来说都是欠佳的。特别是如果在我们的界面上有多个这样的UIButton实例。
12. ASIHttpRequest或者SDWebImage里面给UIImageView加载图片的逻辑是什么样的?
详见SDWebImage的实现流程 http://www.cnblogs.com/6duxz/p/4159572.html
13. 麻烦你设计个简单的图片内存缓存器(移除策略是一定要说的)
14. 讲讲你用Instrument优化动画性能的经历吧(别问我什么是Instrument)
可以参考iOS App性能优化
15. loadView是干嘛用的?
当你访问一个ViewController的view属性时,如果此时view的值是nil,那么,ViewController就会自动调用loadView这个方法。这个方法就会加载或者创建一个view对象,赋值给view属性。
loadView默认做的事情是:如果此ViewController存在一个对应的nib文件,那么就加载这个nib。否则,就创建一个UIView对象。
如果你用Interface Builder来创建界面,那么不应该重载这个方法。
如果你想自己创建view对象,那么可以重载这个方法。此时你需要自己给view属性赋值。你自定义的方法不应该调用super。如果你需要对view做一些其他的定制操作,在viewDidLoad里面去做。
=========================================
根据上面的文档可以知道,有两种情况:
1、如果你用了nib文件,重载这个方法就没有太大意义。因为loadView的作用就是加载nib。如果你重载了这个方法不调用super,那么nib文件就不会被加载。如果调用了super,那么view已经加载完了,你需要做的其他事情在viewDidLoad里面做更合适。
2、如果你没有用nib,这个方法默认就是创建一个空的view对象。如果你想自己控制view对象的创建,例如创建一个特殊尺寸的view,那么可以重载这个方法,自己创建一个UIView对象,然后指定 self.view = myView; 但这种情况也没有必要调用super,因为反正你也不需要在super方法里面创建的view对象。如果调用了super,那么就是浪费了一些资源而已
参考:http://www.cnblogs.com/dyllove98/archive/2013/06/06/3123005.html
16. viewWillLayoutSubView你总是知道的。
横竖屏切换的时候,系统会响应一些函数,其中 viewWillLayoutSubviews 和 viewDidLayoutSubviews。
//
- (void)viewWillLayoutSubviews { [self _shouldRotateToOrientation:(UIDeviceOrientation)[UIApplication sharedApplication].statusBarOrientation]; } -(void)_shouldRotateToOrientation:(UIDeviceOrientation)orientation { if (orientation == UIDeviceOrientationPortrait ||orientation == UIDeviceOrientationPortraitUpsideDown) { // 竖屏 } else { // 横屏 } }通过上述一个函数就知道横竖屏切换的接口了。
注意:viewWillLayoutSubviews只能用在ViewController里面,在view里面没有响应。
17. GCD里面有哪几种Queue?你自己建立过串行queue吗?背后的线程模型是什么样的?
1.主队列 dispatch_main_queue(); 串行 ,更新UI
2.全局队列 dispatch_global_queue(); 并行,四个优先级:background,low,default,high
3.自定义队列 dispatch_queue_t queue ; 可以自定义是并行:DISPATCH_QUEUE_CONCURRENT或者串行DISPATCH_QUEUE_SERIAL
18. 用过coredata或者sqlite吗?读写是分线程的吗?遇到过死锁没?咋解决的?
参考:CoreData与SQLite的线程安全
19. http的post和get啥区别?(区别挺多的,麻烦多说点)
1.GET请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,参数之间以&相连,如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0%E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如:%E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST把提交的数据则放置在是HTTP包的包体中。
2.”GET方式提交的数据最多只能是1024字节,理论上POST没有限制,可传较大量的数据,IIS4中最大为80KB,IIS5中为100KB”??!
以上这句是我从其他文章转过来的,其实这样说是错误的,不准确的:
(1).首先是”GET方式提交的数据最多只能是1024字节”,因为GET是通过URL提交数据,那么GET可提交的数据量就跟URL的长度有直接关系了。而实际上,URL不存在参数上限的问题,HTTP协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制。IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。
注意这是限制是整个URL长度,而不仅仅是你的参数值数据长度。[见参考资料5]
(2).理论上讲,POST是没有大小限制的,HTTP协议规范也没有进行大小限制,说“POST数据量存在80K/100K的大小限制”是不准确的,POST数据是没有限制的,起限制作用的是服务器的处理程序的处理能力。
3.在ASP中,服务端获取GET请求参数用Request.QueryString,获取POST请求参数用Request.Form。在JSP中,用request.getParameter(\”XXXX\”)来获取,虽然jsp中也有request.getQueryString()方法,但使用起来比较麻烦,比如:传一个test.jsp?name=hyddd&password=hyddd,用request.getQueryString()得到的是:name=hyddd&password=hyddd。在PHP中,可以用GET和_POST分别获取GET和POST中的数据,而REQUEST则可以获取GET和POST两种请求中的数据。值得注意的是,JSP中使用request和PHP中使用_REQUEST都会有隐患,这个下次再写个文章总结。
4.POST的安全性要比GET的安全性高。注意:这里所说的安全性和上面GET提到的“安全”不是同个概念。上面“安全”的含义仅仅是不作数据修改,而这里安全的含义是真正的Security的含义,比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为(1)登录页面有可能被浏览器缓存,(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site request forgery攻击。
总结一下,Get是向服务器发索取数据的一种请求,而Post是向服务器提交数据的一种请求,在FORM(表单)中,Method默认为”GET”,实质上,GET和POST只是发送机制不同,并不是一个取一个发!
20. 我知道你大学毕业过后就没接触过算法数据结构了,但是请你一定告诉我什么是Binary search tree? search的时间复杂度是多少?
Binary search tree:二叉搜索树。
主要由四个方法:(用C语言实现或者Python)
1.search:时间复杂度为O(h),h为树的高度
2.traversal:时间复杂度为O(n),n为树的总结点数。
3.insert:时间复杂度为O(h),h为树的高度。
4.delete:最坏情况下,时间复杂度为O(h)+指针的移动开销。
可以看到,二叉搜索树的dictionary operation的时间复杂度与树的高度h相关。所以需要尽可能的降低树的高度,由此引出平衡二叉树Balanced binary tree。它要求左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。这样就可以将搜索树的高度尽量减小。常用算法有红黑树、AVL、Treap、伸展树等。
)
)
)
...)

(详解))

)
)


)
)

)
)
)

)
