RNN循环神经网络
整体思想:
将整个序列划分成多个时间步,将每一个时间步的信息依次输入模型,同时将模型输出的结果传给下一个时间步,也就是说后面的结果受前面输入的影响。

RNN的实现公式:
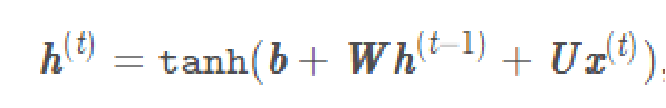

个人思路:
首先设置一个初始权重h(一般情况下设置为全0矩阵),将h(0)与权重W相乘在加上输入X(0)与权重U相乘再加上偏差值b(本文设为0)的和通过tanh这个激活函数后的结果为第二层的h(1),依次类推。各层h(除了h(0)和最后一个输出的h(n)以外)组成的向量既为输出结果,h(n)为预测隐含层结果。
Pytorch模型下RNN代码实现:
import torch
import torch.nn as nn
import numpy as np"""
实现简单的神经网络
使用pytorch实现RNN
不考虑偏差值
"""
class TorchRNN(nn.Module):def __init__(self, input_size, hidden_size):super(TorchRNN, self).__init__()self.layer = nn.RNN(input_size, hidden_size, bias=False, batch_first=True)def forward(self, x):return self.layer(x)x = np.array([[1, 2, 3], [3, 4, 5], [5, 6, 7]]) #网络输入#torch实验
hidden_size = 4 #隐单元是4维 1×4矩阵
torch_model = TorchRNN(3, hidden_size) #输入是3维,因此输出应为3×4矩阵
#print(len(torch_model.state_dict()))
w_ih = torch_model.state_dict()["layer.weight_ih_l0"] #获得随机初始化的权重U
w_hh = torch_model.state_dict()["layer.weight_hh_l0"] #获得随机初始化的权重Wtorch_x = torch.FloatTensor([x])
output, h = torch_model.forward(torch_x)
print(output.detach().numpy(), "torch模型预测结果")
#这里的输出第一行是第一个输入值之后得到的h,以此类推
#print(h.detach().numpy(), "torch模型预测隐含层结果")
#预测隐含层结果就是最后一个输入值得到的h
在自定义模型中的RNN的代码实现:
"""
手动实现简单的神经网络
手动实现RNN
需要将该代码放入pytorch模型中才能运行
对比理解过程
"""
#自定义RNN模型
class DiyModel:def __init__(self, w_ih, w_hh, hidden_size):self.w_ih = w_ihself.w_hh = w_hhself.hidden_size = hidden_sizedef forward(self, x):ht = np.zeros((self.hidden_size)) #初始化h为全0矩阵output = []for xt in x:ux = np.dot(self.w_ih, xt) #函数实现wh = np.dot(self.w_hh, ht) #函数实现ht_next = np.tanh(ux + wh) #函数实现output.append(ht_next) #放入output列表中ht = ht_next #h向下更新return np.array(output), htdiy_model = DiyModel(w_ih, w_hh, hidden_size)
output, h = diy_model.forward(x)
print(output, "diy模型预测结果")
# print(h, "diy模型预测隐含层结果")
因为自定义模型中需要得到跟pytorch模型中的输入和随机初始化的W和,如果需要运行需将自定义模型代码放在pytorch模型的下面运行。同样不考虑偏差值。
结果如下:

可以看到两者运行结果相同,说明运算逻辑没有问题。














方法源码解析(二))
)

python在anaconda安装opencv库及skimage库(scikit_image库)诸多问题解决办法)

