朴素贝叶斯和贝叶斯估计
Note from Towards Data Science’s editors: While we allow independent authors to publish articles in accordance with our rules and guidelines, we do not endorse each author’s contribution. You should not rely on an author’s works without seeking professional advice. See our Reader Terms for details.
Towards Data Science编辑的注意事项: 虽然我们允许独立作者按照我们的 规则和指南 发表文章 ,但我们不认可每位作者的贡献。 您不应在未征求专业意见的情况下依赖作者的作品。 有关 详细信息, 请参见我们的 阅读器条款 。
Maybe you’re an investor trying to decide whether a stock is worth investing in. Maybe you’ve only recently heard of Bayesian inference and want to get a sense of how it can be applied in the real world. Maybe you’re a seasoned analyst who stumbled upon this article and found the title interesting. Regardless of where you come from, I thank you for giving this piece a read. I’m going to talk about the normal-normal model, one of the foundational models in Bayesian statistics, and how it can be used to estimate the growth rate of a company’s revenue. That estimate can then be used to decide whether or not the company is a worthwhile investment.
也许您是试图确定股票是否值得投资的投资者。也许您只是最近才听说过贝叶斯推理,并想了解如何将其应用到现实世界中。 也许您是一位经验丰富的分析师,偶然发现了这篇文章,并发现标题很有趣。 无论您来自何处,我都感谢您阅读本文。 我将讨论贝叶斯统计中的基本模型之一,正常-正常模型,以及如何将其用于估计公司收入的增长率。 然后,可以使用该估算值来确定公司是否值得投资。
The first objective of this piece is to demonstrate how the normal-normal model can be used to incorporate a subjective overlay into data analysis. The second is to provide some intuition behind the normal-normal model and Bayesian inference in general without getting too bogged down in the mechanics. I’ll say it here and again at the end of the article, but this piece does not constitute investment advice. It is meant to be educational.
本文的第一个目的是演示如何使用正常-正常模型将主观叠加纳入数据分析。 第二个目的是在法线-法线模型和贝叶斯推理之后提供一些直觉,而又不会过于迷惑力学。 我将在本文的结尾处一再说,但这并不构成投资建议。 这是为了教育。
With that disclaimer out of the way, let’s get to it!
有了这个免责声明,让我们开始吧!
手头的任务 (The Task at Hand)
Financial modeling generally refers to projecting fundamental values for a company in order to arrive at a fair price estimate for the company’s stock. Some of the most common metrics used to arrive at valuations are revenue, earnings, and cash flow. The company we’re going to look at is MongoDB, a software services company. It began trading publicly back in 2017, and its revenue growth has been tremendous.
财务建模通常是指预测公司的基本价值,以便得出公司股票的合理价格估计。 用于得出估值的一些最常见的指标是收入,收益和现金流量。 我们要看的公司是软件服务公司MongoDB。 它于2017年开始公开交易,其收入增长巨大。
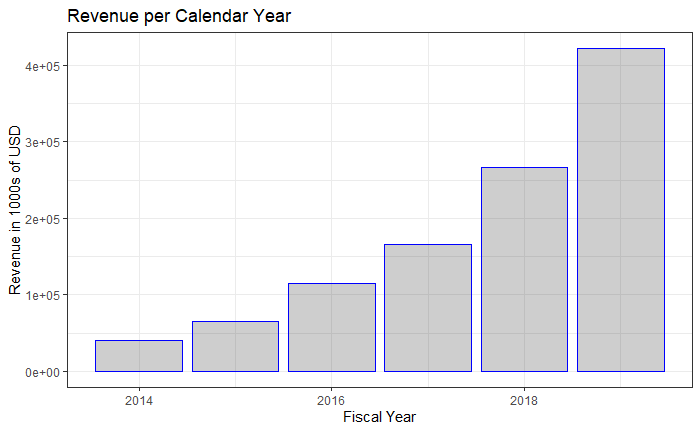
Given how young the company is and how it’s in a growth-oriented phase of its existence, it’s reasonable to focus on revenue in order to value the company. Data in the company’s 10-K filings, the annual financial reports, shows revenue numbers on a quarterly basis starting in fiscal 2016. Annual numbers are present from the year 2014. To give us more data than the six annual numbers (which translate into five growth numbers), I’ve computed rolling one-year revenue growth on a quarterly basis. That data is shown below.
考虑到公司的年轻程度以及它处于生存发展阶段的方式,合理地关注收入以对公司进行估值是合理的。 该公司10-K档案(年度财务报告)中的数据显示了从2016财年开始的季度收入数字。从2014年开始提供年度数字。为我们提供的数据要比六个年度数字(这意味着五个增长数字),我已经计算出了一个季度滚动的一年收入增长。 该数据如下所示。
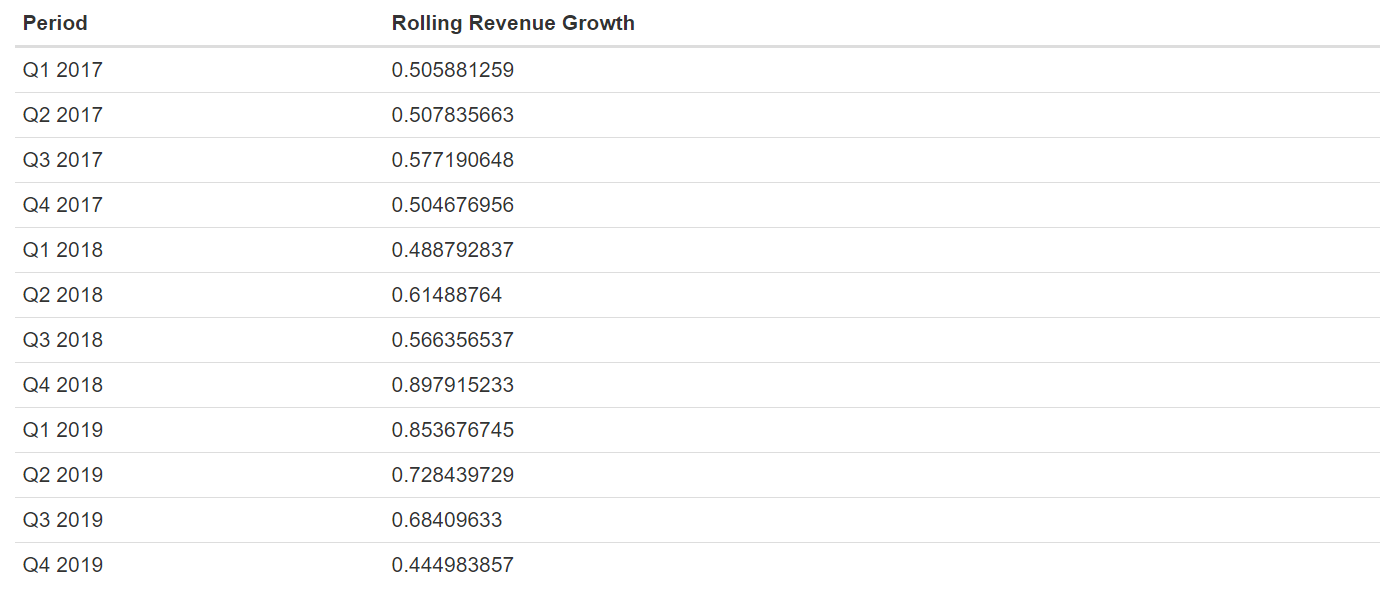
Closer to the end of this piece, I’ll compare the results of our analysis using year-end data versus quarterly data. (Although I haven’t run a formal analysis, I assume there’s a degree of serial correlation in the quarterly data. This won’t matter in terms of explaining the concepts of the normal-normal model, but it is certainly something to be mindful of in practice.)
在本文的最后,我将比较使用年末数据和季度数据进行分析的结果。 (尽管我没有进行正式的分析,但我假设季度数据中存在一定程度的序列相关性。这在解释法线-法线模型的概念方面并不重要,但一定要注意在实践中。)
A common way to project revenue for a company is to use the average historical revenue growth rate over a certain amount of time. For companies with many years of data, this isn’t necessarily a bad practice, especially if the growth rates follow a normal distribution. Given how little sample data we have and the histogram of the data which I’ll plot below, we may feel that using the sample mean in this case is unwise.
预测公司收入的一种常用方法是使用一定时间内的平均历史收入增长率。 对于拥有多年数据的公司而言,这不一定是坏习惯,尤其是当增长率遵循正态分布时。 考虑到我们只有很少的样本数据以及我将在下面绘制的数据直方图,我们可能会觉得在这种情况下使用样本均值是不明智的。
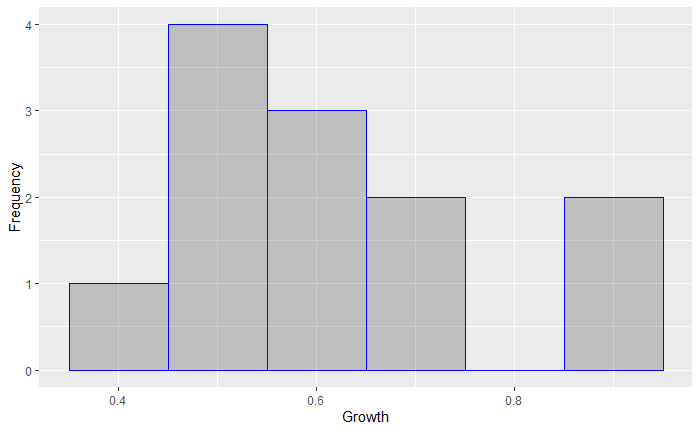
Bayesian inference is particularly useful in situations where our sample size is small and we hold a subjective belief that our sample data does not appropriately represent what a larger sample would look like.
在样本量较小并且我们主观认为样本数据不能适当代表较大样本的情况下,贝叶斯推断特别有用。
To conduct Bayesian inference, we’ll need a prior distribution and a sampling model. Before defining those distributions in our context, I’ll go over some of the basics of Bayesian inference and how the prior distribution and sampling model come into play. Feel free to skip this section if you’re familiar with Bayes’ theorem and how it applies to distributions.
要进行贝叶斯推断,我们需要先验分布和采样模型。 在我们的上下文中定义这些分布之前,我将介绍贝叶斯推断的一些基础知识以及先验分布和采样模型如何发挥作用。 如果您熟悉贝叶斯定理及其在分布中的应用,请随时跳过本节。
贝叶斯定理和分布 (Bayes’ Theorem and Distributions)
In its simplest form, Bayes’ theorem is defined as
以最简单的形式,贝叶斯定理定义为
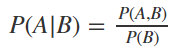
which is equivalent to
相当于
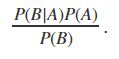
This is all well and good if we have neatly defined probabilities to use, but distributions complicate the process a little.
如果我们有明确定义的使用概率,那么这一切都很好,但是分布会使过程复杂化了一点。
First, let’s substitute A with θ and B with Y. In this case, Y refers to the points in our sample data, and θ refers to the true average growth rate in revenue for MongoDB. Re-writing the second form of the formula with our substitutions, we have
首先,让我们用θ替换A并用Y替换B。 在这种情况下, Y表示示例数据中的点, θ表示MongoDB的收入的真实平均增长率。 用我们的替换来重写公式的第二种形式,我们有
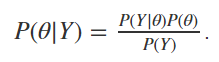
In words, the distribution we’re trying to model is the distribution of average revenue growth rate GIVEN our sample growth rates. We will use our sample data and a little bit of judgement to define this distribution P(Y|θ). We will also need a prior distribution P(θ) for our average growth rate and the marginal distribution of our data P(Y). The onus is on us to define our sampling distribution as well as define a prior distribution for θ. Once we have a sampling distribution P(Y|θ), the correct way to obtain P(Y) would be to solve for the integral below:
换句话说,我们要建模的分布是根据我们的样本增长率得出的平均收入增长率的分布。 我们将使用样本数据和一些判断来定义此分布P ( Y | θ )。 对于平均增长率和数据的边际分布P ( Y ),我们还将需要先验分布P ( θ )。 我们有责任定义采样分布以及θ的先验分布。 一旦有了采样分布P ( Y | θ ),获得P ( Y )的正确方法就是求解以下积分:
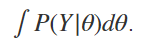
In practice, this may be difficult to do, but we can use a shortcut. Since Y is only conditional on θ in this instance, P(Y) is an unconditional probability distribution and encompasses all possibilities of Y. This means that the area under the distribution will be equal to 1 (the sum of all probabilities for an event equals 1), and the integral will be equal to 1 multiplied by a normalizing constant. Rather than solve for this normalizing constant, we can instead say
实际上,这可能很难做到,但是我们可以使用快捷方式。 由于在这种情况下Y仅以θ为条件,因此P ( Y )是无条件的概率分布,并且包含Y的所有可能性。 这意味着分布下的面积将等于1(一个事件的所有概率之和等于1),并且积分将等于1乘以归一化常数。 除了解决这个标准化常数外,我们可以说
P(θ|Y)∝P(Y|θ)P(θ)
P ( θ | Y )∝ P ( Y | θ ) P ( θ )
where ∝ stands for “is proportional to.” In other words, we don’t need to worry about P(Y). With one task eliminated, we only have to define our sampling and prior distributions.
∝代表“正比于”。 换句话说,我们不必担心P ( Y )。 消除一项任务后,我们只需定义采样和先验分布即可。
(Note: technically, Y is conditional on sample variance. In this case, we are going to assume that the variance is known and constant. Because our variance is assumed to be known and a constant, we can omit it from the notation.)
(注意:从技术上讲, Y以样本方差为条件。在这种情况下,我们将假设方差是已知的并且是常数。因为我们的方差被假定为已知并且是常数,所以可以从符号中忽略它。)
定义我们的抽样模型和先验分布 (Defining Our Sampling Model and Prior Distribution)
We’re going to use a normal model for our sampling distribution. Having looked at the histogram for our data, one may think that there are distributions available to us that better represent the data. I like the normal distribution in this case because it is continuous and has support along all real numbers (revenue growth could theoretically be negative or positive).
我们将使用正常模型进行抽样分配。 在查看了我们数据的直方图之后,我们可能会认为有一些可用的分布更好地表示了数据。 在这种情况下,我喜欢正态分布,因为它是连续的并且在所有实数上都有支持(理论上收入增长可以是负数或正数)。
To define this sampling model, we compute the mean and variance for this data set and use these as the parameters for our sampling model. The form this will take is
为了定义该采样模型,我们计算该数据集的均值和方差,并将其用作我们的采样模型的参数。 采取的形式是
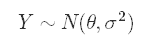
where the first term represents the unknown true average growth rate for MongoDB’s revenue and the second term represents the variance of the growth rates; we will treat this variance as known. We could just as easily assume that we know our mean but not our variance or that we know neither; all three classes of situations are well-documented and have substantial literature regarding how to work them. The normal-normal model applies to the situation with known variance and unknown mean, hence why we are making our current assumptions.
其中第一项代表MongoDB收入的未知真实平均增长率,第二项代表增长率的方差; 我们将这种差异视为已知。 我们可以很容易地假设我们知道我们的平均值,但是我们不知道方差,或者我们都不知道。 这三类情况都有充分的文献记录,并有大量有关如何工作的文献。 正常-正常模型适用于方差已知且均值未知的情况,因此我们为什么要进行当前的假设。
Next, we need to define a prior distribution for θ. For the same reasons that we’re using a normal distribution for the sampling model (continuous, support along positive and negative values), we’re going to use a normal distribution as our prior. We need to define a mean and a variance for the variable θ. We’ll define this distribution as
接下来,我们需要定义θ的先验分布。 出于同样的原因,我们在抽样模型中使用正态分布(连续的,沿正值和负值的支持),因此我们将使用正态分布作为先验。 我们需要为变量θ定义均值和方差。 我们将这种分布定义为
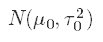
where the first term is the prior mean and the second term is the prior variance. There is significant literature dedicated to selecting priors; the main focus of this piece is how to apply the normal-normal model, so I didn’t put extensive effort in defining my prior distribution.
其中第一项是先验均值,第二项是先验方差。 有大量文献致力于选择先验。 本文的主要重点是如何应用正态-正态模型,因此我没有花太多精力来定义我的先前分布。
To select a value for the prior mean, I looked at the average revenue growth rate of sales of the S&P 500 index over the last 19 years (multpl.com) and then multiplied it by the β of MongoDB. In the world of equities, β refers to the covariance of an individual stock’s returns with the return of broader basket of stocks (often called an index) divided by the variance of the index returns. MongoDB has a β of about 1.26 according to Seeking Alpha, a research site with news, data, and analyses of many stocks. Whenever we see a β > 1, we can assume that the stock we are looking at is more volatile than the index it is being compared to; for this reason, I multiply the revenue growth of the index by β. Other approaches could involve looking at slightly older companies in the software service industries or similar age companies across industries. No method is perfect, and all are viable.
为了为先前的均值选择一个值,我查看了标普500指数过去19年的平均销售收入增长率(multpl.com) ,然后将其乘以MongoDB的β。 在股票世界中,β指的是单个股票收益与更广泛的一篮子股票(通常称为指数)的收益除以指数收益的方差的协方差。 根据提供新闻,数据和许多股票分析的研究网站Seeking Alpha的数据,MongoDB的β约为1.26。 每当我们看到β> 1时,我们就可以假设我们所看的股票的波动性大于它所比较的指数; 因此,我将指数的收入增长乘以β。 其他方法可能涉及查看软件服务行业中稍老的公司或跨行业的类似年龄的公司。 没有一种方法是完美的,并且所有方法都是可行的。
The next parameter we have to assign is the prior variance. Just to be clear, this is not what we presume is the variance in growth rates, but the presumed variance of the AVERAGE growth rate; this prior variance is meant to reflect our certainty in the accuracy of the prior mean. If we had full confidence that this was the correct mean to use, we could set our variance effectively equal to 0 (for computation purposes, we can’t actually use 0, but we can use a very small number such as .00001). On the other hand, if we have very little confidence in our estimate, we can use a large variance to indicate this level of certainty. In this case, where our prior mean is about 4.5%, I don’t have much of an opinion of how confident I am with this estimate. To define my distribution, I’ll use a standard deviation of 10%. With this, I’m effectively stating that I’m 95% confident that the true value for theta lies between -15.5% and 24.5% (4.5+/-2 standard deviations). This estimate may seem highly conservative given how MongoDB’s average growth rate has been about 61%, but this is exactly why Bayesian inference is powerful. MongoDB has spent the majority of its time trading in a bull market that was particularly favorable for software names. The prior distribution reflects data from multiple market cycles and consequently multiple phases of growth and contraction. Between the possibility of economic contraction, the chance MongoDB doesn’t execute its strategy effectively, and revenue growth slowing simply due to scale, I’m holding the subjective belief that MongoDB’s true average growth rate is less than what the sample data suggests. The prior distribution I’ve selected represents that belief. Now, we can study the output of our analysis.
我们必须分配的下一个参数是先验方差。 需要明确的是,这不是我们所假定的增长率的方差,而是假定的平均增长率的方差。 此先验方差旨在反映我们对先验均值准确性的确定性。 如果我们完全有信心使用这是正确的平均值,则可以将方差有效地设置为0(出于计算目的,我们实际上不能使用0,但是可以使用非常小的数字,例如.00001)。 另一方面,如果我们对估计的信心很小,则可以使用较大的方差来表示此确定性级别。 在这种情况下,我们之前的均值约为4.5%,我对这个估计有多自信没有多少看法。 为了定义我的分布,我将使用10%的标准偏差。 借此,我有效地表明,我有95%的信心认为theta的真实值在-15.5%和24.5%之间(4.5 +/- 2标准偏差)。 考虑到MongoDB的平均增长率如何达到61%左右,这个估计值似乎非常保守,但这正是贝叶斯推断强大的原因。 MongoDB大部分时间都在牛市中交易,这对软件名称特别有利。 先前的分布反映了来自多个市场周期的数据,因此反映了增长和收缩的多个阶段。 在经济收缩的可能性,MongoDB无法有效执行其战略的机会以及仅仅是由于规模而导致的收入增长放缓之间,我主观地认为MongoDB的真实平均增长率低于样本数据所表明的水平。 我选择的先前分配代表了这一信念。 现在,我们可以研究分析的结果。
To recap, here are the forms for our two models:
回顾一下,这是我们两个模型的表格:
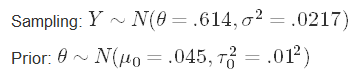
Great, let’s move on to our analysis!
太好了,让我们继续进行分析!
后验分析和直觉 (Posterior Analysis and Intuition)
I’ll focus more on the intuition offered by these forms rather than walk through a derivation by hand. Anyone truly interested in using the normal-normal model should study the derivation of the above parameters. Wikipedia has some good documentation, and most introductory textbooks to Bayesian statistics cover the derivations in detail.
我将更多地关注这些形式提供的直觉,而不是手工进行推导。 任何对使用法线-法线模型感兴趣的人都应该研究上述参数的推导。 Wikipedia有一些很好的文档,并且有关贝叶斯统计的大多数入门教科书都详细介绍了派生方法。
When we have a normal distribution for our sampling model as well as a normal for our prior distribution on the sample mean, the resulting posterior distribution is a product of two normal models. The power of the normal-normal model is that the product of these distributions is also a normal distribution, albeit with updated parameters. In Bayesian jargon, a normal prior distribution is a conjugate prior distribution, meaning that it and its resulting posterior distribution have the same form. The fact that our posterior distribution is a normal distribution may not seem like that big of a deal, but depending on the data we’re trying to model and the parameters we’re trying to estimate, there are many instances where our posterior does not take such a familiar form. Because this posterior distribution is well-defined, we can sample from it directly and consequently compute summary statistics on it easily.
当我们的采样模型具有正态分布,并且样本均值具有先验分布的正态分布时,所得后验分布是两个正态模型的乘积。 正态-正态模型的功效在于,尽管具有更新的参数,但这些分布的乘积也是正态分布。 在贝叶斯行话中,正态先验分布是共轭先验分布,这意味着它和它的后验分布具有相同的形式。 后验分布是正态分布这一事实似乎没什么大不了的,但是根据我们要建模的数据和我们要估算的参数,在很多情况下我们的后验分布不是采取这样熟悉的形式 由于此后验分布是定义明确的,因此我们可以直接从中进行采样,从而轻松地计算出其后的摘要统计量。
The notations and re-parametrizations below are from Chapter 5 in Peter Hoff’s textbook, “A First Course in Bayesian Statistics,” the book I used in my first undergraduate Bayesian statistics course and the book I’ve been studying in recent times.
下面的表示法和重新参数化来自彼得·霍夫(Peter Hoff)教科书“贝叶斯统计学的第一门课程”的第5章,这是我在我的第一门贝叶斯统计学课程中使用的书,也是我最近所研究的书。
Our posterior distribution takes the form
我们的后验分布形式为
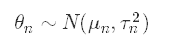
where the first term refers to the posterior mean and second term refers to the posterior variance. The formulas to calculate these updated parameters are
其中第一项指的是后均值,第二项指的是后方方差。 计算这些更新参数的公式是
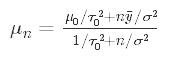
and
和
These formulas may look somewhat intimidating, but hopefully you see some similarities between them. A common practice and a particularly helpful one for gaining intuition about these formulas is to look at the formulas in terms of precision rather than variance. Precision is the inverse of variance.
这些公式可能看起来有些吓人,但希望您能看到它们之间的相似之处。 获得这些公式的直觉的一种常见实践和一种特别有用的方法是,从精度而不是方差的角度来看这些公式。 精度是方差的倒数。
In this case, we have three relevant precisions to observe:
在这种情况下,我们需要观察三个相关的精度:
If we invert the posterior variance formula to calculate posterior precision, we see that the posterior precision in terms of standard deviations is
如果我们反转后验方差公式以计算后验精度,则可以看到以标准差表示的后验精度为
This can be written in terms of precisions as
这可以用精度来表示为
In this form we can clearly see that the posterior precision is the sum of the prior precision and the sample precision multiplied by the sample size. We can also re-write the posterior mean in terms of precisions:
在这种形式下,我们可以清楚地看到后验精度是先验精度与样本精度的和乘以样本大小。 我们还可以根据精度重写后验均值:
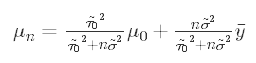
Here, we can clearly see that the posterior mean is a weighted average of the prior mean and sample mean.
在这里,我们可以清楚地看到后验均值是先验均值和样本均值的加权平均值。
For our data, the posterior parameters are:
对于我们的数据,后验参数为:
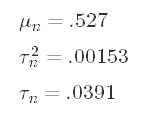
And there we have them — our updated parameters. Our posterior estimate for the average growth rate is about 52.7% — a decent bit lower than our sample average, but not overwhelmingly lower. We’ve taken a subjective belief, represented that belief with a distribution, and used that distribution to augment our analysis. Hooray! This is the power of Bayesian inference. As long as we can define our beliefs, we can incorporate them in a rigorous way in our analysis. Let’s talk a little more about what we have and also what we don’t have.
有了它们-我们更新的参数。 我们对平均增长率的后验估计约为52.7%,虽然比我们的样本平均值低了很多,但绝不算低。 我们采用了主观信念,用分布表示了该信念,并使用该分布来扩大我们的分析。 万岁! 这就是贝叶斯推理的力量。 只要我们能够定义我们的信念,我们就可以将其严格地纳入我们的分析中。 让我们再谈一些关于我们拥有和不拥有的东西。
With our posterior standard deviation, we can compute a credible interval for our estimate. For those new to Bayesian statistics, a credible interval is not the same thing as a confidence interval even though they are computed in a similar manner. Our 95% credible interval for the posterior mean is .527+/−2∗.0391.527+/−2∗.0391 which leads to points of 44.88% and 60.52%. With this credible interval, we’re making the statement that we’re 95% sure that the true value of the posterior mean falls within the interval. Even at this point, we don’t treat this updated mean as a known entity. Furthermore, we are not saying that 52.7% is our forecast for revenue growth rate over the next rolling one-year period. If we wanted to make a forecast within this framework, we’d use the posterior predictive distribution. Since that is a separate topic, I won’t touch on it here, but the process of deriving that distribution is similar to deriving the posterior distribution.
利用我们的后验标准差,我们可以计算出可信的区间。 对于贝叶斯统计新手来说,可信区间与置信区间并不相同,即使它们是以类似方式计算的。 我们的后验平均值的95%可信区间为.527 +/- 2 * .0391.527 + /-/ 2 * .0391,得出的分数分别为44.88%和60.52%。 在此可信区间内,我们声明95%的后验均值的真实值落在该区间内。 即使在这一点上,我们也不会将这种更新的均值视为已知实体。 此外,我们并不是说52.7%是我们对下一个滚动的一年期内收入增长率的预测。 如果我们想在此框架内进行预测,则可以使用后验预测分布。 由于这是一个单独的主题,因此在此不再赘述,但是推导该分布的过程类似于推导后验分布。
Two key implications should be noted from this analysis: the first is that as sample size grows larger, the posterior mean and posterior variance are more and more determined by the sample data. I’m not going to state that there’s an explicit cutoff, but at some amount of data, adding a prior doesn’t move the needle much all else equal. Intuitively, this is reasonable. If you have rich enough sampling data, the sampling data likely represents the actual structure in the data, and you may not see the need to utilize a prior distribution.
此分析应注意两个关键含义:首先是随着样本量的增加,后均值和后方差越来越多地由样本数据决定。 我不会说有一个明确的界限,但是在一定数量的数据下,添加一个先验不会使其他所有条件都变差。 凭直觉,这是合理的。 如果您有足够丰富的采样数据,则采样数据可能表示数据中的实际结构,并且您可能看不到需要利用先验分布。
To emphasize the first point, we can re-run our analysis using strictly the year-end data which would leave us with a sample size of five data points. Using the same prior distribution, our new sampling mean and variance are about 59.8% and .012 (or 11.1% standard deviation), and our posterior mean and variance are 23% and .0019 (or 4.45% standard deviation). This posterior estimate for the mean is much lower than what we saw in our first iteration; with our sample size cut significantly, the prior plays a much heavier role in the output. The standard deviation didn’t change as much, but we can see that it’s larger even though our sampling standard deviation was smaller the second time around. We have a much lower estimate, and we have slightly less confidence in the estimate (wider credible interval).
为了强调第一点,我们可以严格使用年终数据来重新运行分析,这将使我们拥有五个数据点的样本量。 使用相同的先验分布,我们的新采样均值和方差分别为59.8%和.012(或11.1%标准偏差),而后验均值和方差分别为23%和.0019(或4.45%标准偏差)。 该均值的后验估计值比我们在第一次迭代中看到的要低得多。 由于我们的样本量大大减少,因此先验数据在输出中起着举足轻重的作用。 标准偏差变化不大,但是即使第二次采样标准偏差较小,我们也可以看到它更大。 我们的估算值要低得多,而我们对估算值的信心则稍差(可信区间更大)。
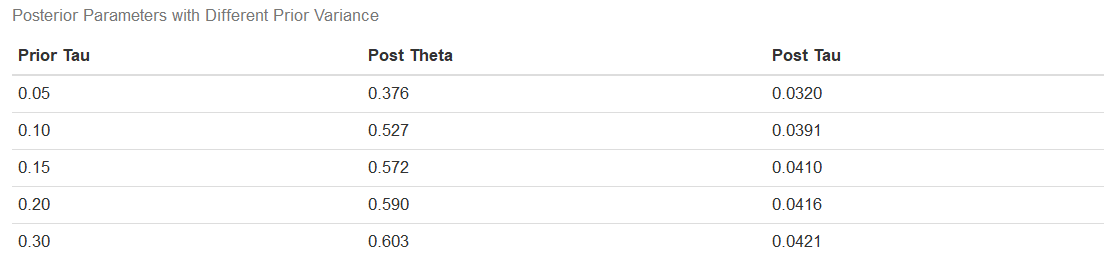
The second implication of our analysis is that the smaller the prior variance, the greater the prior precision and the greater impact it has on both the posterior mean and posterior variance. The more confidence we have in our prior, the more it will affect our posterior estimates. To illustrate this point, I re-ran our original analysis with different values for the prior variance. The values for the prior mean are all .045, and the sampling mean and variance come from our rolling revenue data. The table below shows the results of this experiment.
我们的分析的第二个含义是,先验方差越小,先验精度越高,它对后均值和后方方差的影响越大。 我们对先验的信心越高,对后验估计的影响就越大。 为了说明这一点,我使用先前的方差的不同值重新运行了我们的原始分析。 先前均值均为0.045,而抽样均值和方差来自我们的滚动收入数据。 下表显示了该实验的结果。
I’ll also plot the distributions.
我还将绘制分布。
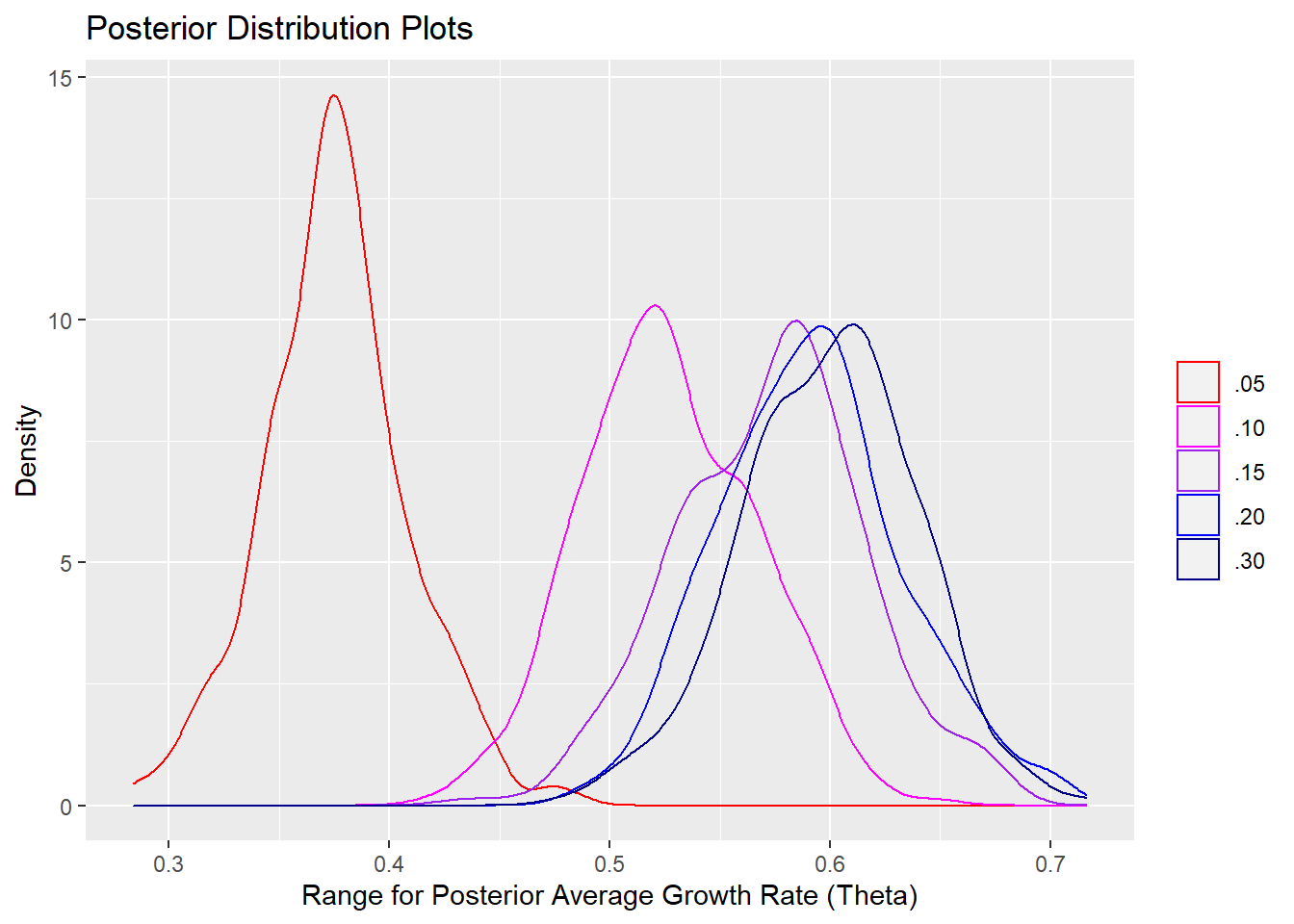
Notice how much closer to the prior mean our posterior distribution with prior variance set to .05 is. As we increase our prior variance (effectively signifying less confidence in the prior mean), the center of our posterior distribution moves closer to the sample mean. Also, while the magnitude of the changes in the posterior variances may not appear that great in the table, from the distribution plots above, we can see how the distributions get progressively wider; in other words, the credible interval for the true value of average growth widens.
注意,先验方差设置为.05的后验分布离先验均值有多近。 随着我们增加先验方差(有效地表示对先验均值的置信度降低),我们后验分布的中心移近样本均值。 同样,尽管后验方差变化的幅度在表格中可能看起来不太大,但从上面的分布图来看,我们可以看到分布如何逐渐变宽。 换句话说,平均增长真实值的可信区间变宽了。
摘要 (Summary)
Just to recap, we were analyzing a young company and wanted to estimate the true growth rate of its revenue. Given the small amount of sample data we had and a subjective belief that the average growth rate will be less than what the sample data suggests, we used Bayesian inference to augment our analysis. We defined a sampling model for our data, defined a prior for the average growth rate that reflected our subjective view, and utilized the normal-normal model to arrive at a posterior estimate and interval for the company’s average growth rate. I hope you found this brief introduction to Bayesian inference as well as the analysis of the results useful. I don’t recommend using the specific numbers in this piece for any valuation of MongoDB, but hopefully you can apply the concepts to your own analysis. I’m attaching a link to the GitHub repository for the code; nothing is particularly complicated, but I’ll share it in the spirit of transparency and reproducibility.
回顾一下,我们正在分析一家年轻的公司,并希望估计其收入的真实增长率。 考虑到我们拥有的样本数据量很少,并且主观认为平均增长率将低于样本数据表明的速度,因此我们使用贝叶斯推断来增强我们的分析。 我们为数据定义了一个采样模型,为反映我们主观观点的平均增长率定义了先验,并利用正常-正常模型得出了公司平均增长率的后验估计和区间。 我希望您对贝叶斯推理的简要介绍以及对结果的分析有用。 对于MongoDB的任何评估,我不建议使用本文中的特定数字,但希望您可以将这些概念应用于您自己的分析。 我正在将代码的链接附加到GitHub存储库; 没有什么特别复杂,但是我将本着透明和可复制的精神来分享。
https://github.com/vinai-oddiraju/TDS_Blog_Post1.git
https://github.com/vinai-oddiraju/TDS_Blog_Post1.git
Lastly, I want to thank the friends and family members who took time to read my drafts and provide feedback throughout the process. As this is my first time writing about a project in this manner, their support is especially appreciated. Thanks, and take care!
最后,我要感谢花时间阅读我的草稿并在整个过程中提供反馈的朋友和家人。 由于这是我第一次以此方式撰写项目,因此特别感谢他们的支持。 谢谢,保重!
免责声明 (Disclaimer)
The thoughts and views expressed in this report are mine alone and do not necessarily reflect the views of my firm. This report is intended to be educational in nature and should not be construed as individual investment advice nor as a recommendation to buy, sell, or hold any security or to adopt any investment strategy.
本报告中表达的思想和观点仅属于我个人,不一定反映我公司的观点。 本报告本质上是具有教育意义的报告,不应解释为个人投资建议,也不能解释为购买,出售或持有任何证券或采用任何投资策略的建议。
资料来源 (Sources)
[1] Hoff, Peter D. A First Course in Bayesian Statistical Methods (2007). Print.
[1] Hoff,PeterD。 贝叶斯统计方法的第一门课程 (2007年)。 打印。
翻译自: https://towardsdatascience.com/a-bayesian-approach-to-estimating-revenue-growth-55d029efe2dd
朴素贝叶斯和贝叶斯估计
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/389457.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

numpy统计分布显示

python数据结构:进制转化探索

Keras框架:人脸检测-mtcnn思想及代码

python中格式化字符串_Python中所有字符串格式化的指南

Javassist实现JDK动态代理

数据图表可视化_数据可视化如何选择正确的图表第1部分

Keras框架:实例分割Mask R-CNN算法实现及实现

机器学习 缺陷检测_球检测-体育中的机器学习。

莫烦Pytorch神经网络第二章代码修改


使用python和javascript进行数据可视化

Android 事件处理

莫烦Pytorch神经网络第三章代码修改

)
New Distinct Substrings(后缀数组)

Android dependency 'com.android.support:support-v4' has different version for the compile (26.1.0...

先知模型 facebook_使用Facebook先知进行犯罪率预测

莫烦Pytorch神经网络第四章代码修改

github gists 101使代码共享漂亮
