本文参考《20天吃透Pytorch》来实现titanic数据集的模型建立和训练
在书中理论的同时加入自己的理解。
一,准备数据
数据加载
titanic数据集的目标是根据乘客信息预测他们在Titanic号撞击冰山沉没后能否生存。
结构化数据一般会使用Pandas中的DataFrame进行预处理。
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from torch import nn
from torch.utils.data import Dataset,DataLoader,TensorDataset
数据集字段如下:
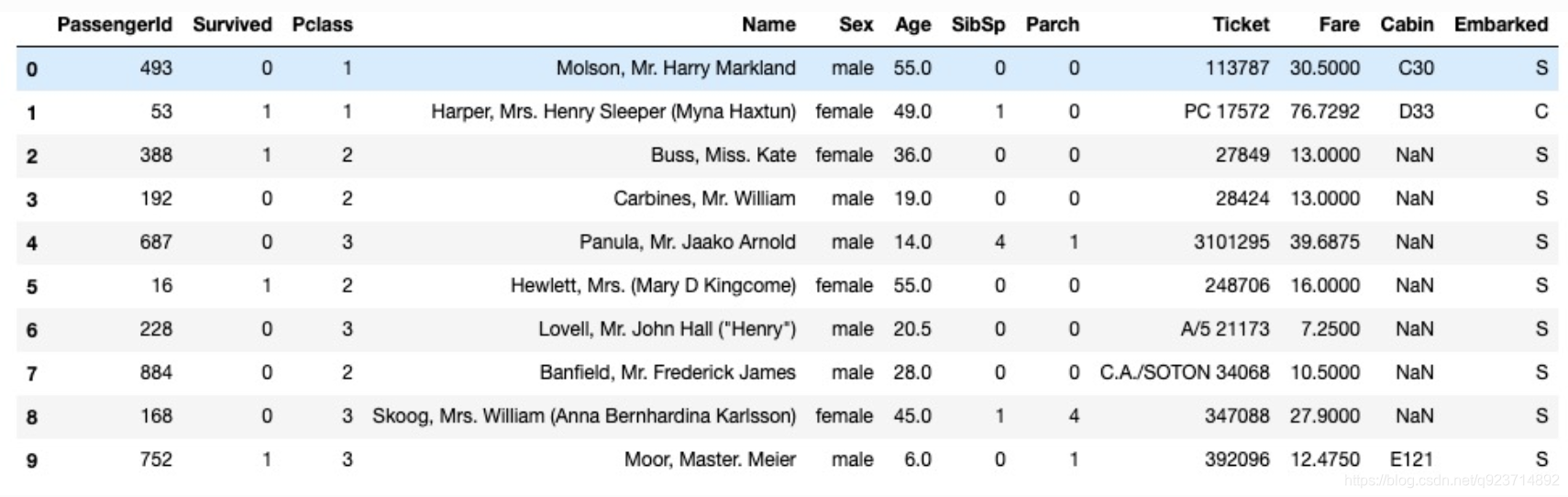
字段说明:
Survived:0代表死亡,1代表存活【y标签】
Pclass:乘客所持票类,有三种值(1,2,3) 【转换成onehot编码】
Name:乘客姓名 【舍去】
Sex:乘客性别 【转换成bool特征】
Age:乘客年龄(有缺失) 【数值特征,添加“年龄是否缺失”作为辅助特征】
SibSp:乘客兄弟姐妹/配偶的个数(整数值) 【数值特征】
Parch:乘客父母/孩子的个数(整数值)【数值特征】
Ticket:票号(字符串)【舍去】
Fare:乘客所持票的价格(浮点数,0-500不等) 【数值特征】
Cabin:乘客所在船舱(有缺失) 【添加“所在船舱是否缺失”作为辅助特征】
Embarked:乘客登船港口:S、C、Q(有缺失)【转换成onehot编码,四维度 S,C,Q,nan】
加载数据集:
#数据读取
train_data = pd.read_csv('./data/titanic/train.csv')
test_data = pd.read_csv('./data/titanic/test.csv')
test_datay = pd.read_csv('./data/titanic/titanic.csv')
#print(train_data.head(10)) #打印训练数据前十个
当我们获得数据集后,首先要查看数据中是否有缺失!!!这个很重要!
train_data.info() #查看训练数据有没有未知的的
test_data.info() #查看测试数据有没有未知的的
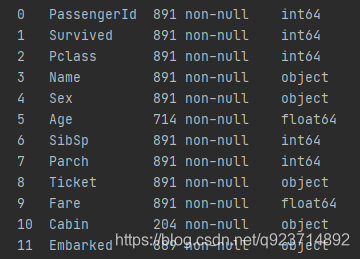
很明显,Age和Cabin数据都有缺失
接下来,先利用Pandas的数据可视化分析数据:
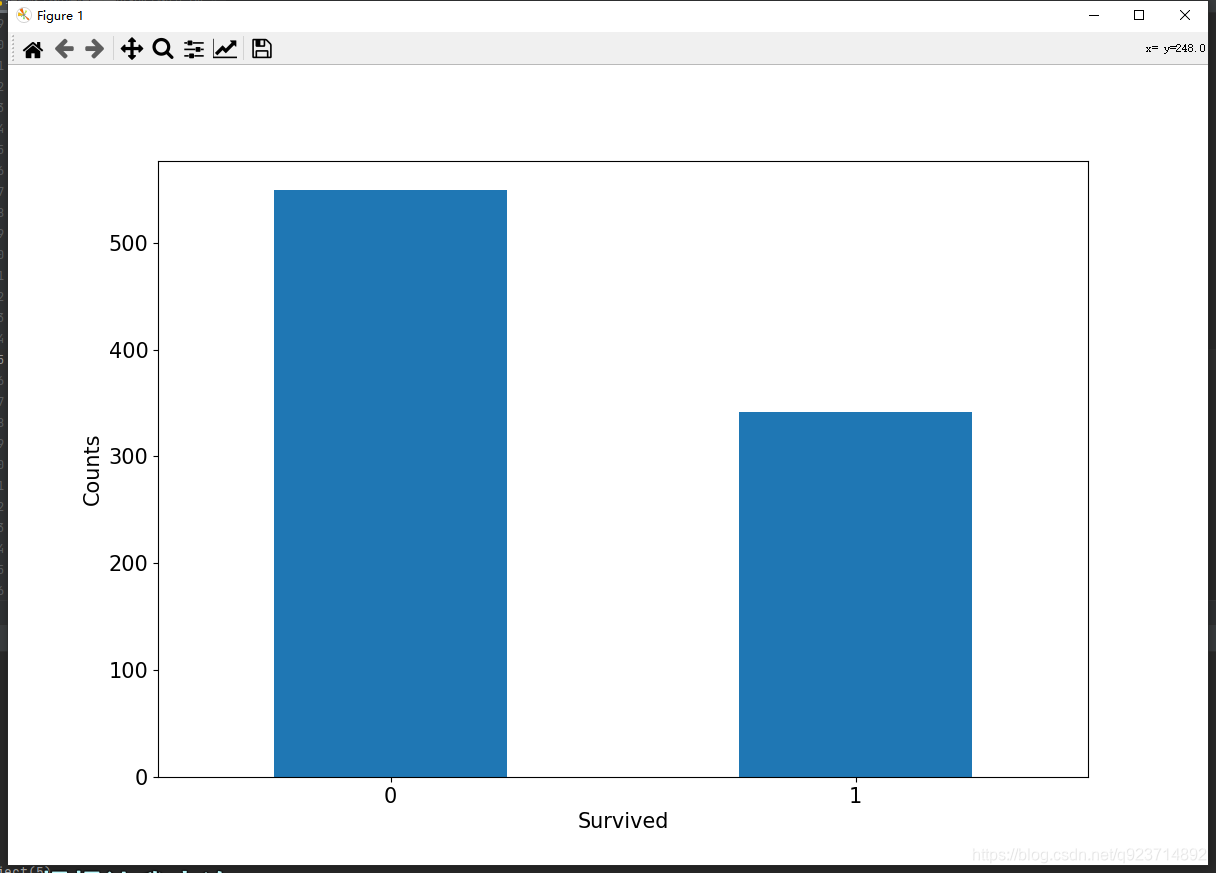
幸存情况
#幸存情况
ax = train_data['Survived'].value_counts().plot(kind = 'bar',figsize = (12,8),fontsize =15,rot = 0)
#value_counts是查询有多少个不同值且每个不同值有多少个重复的
ax.set_ylabel('Counts',fontsize = 15)
ax.set_xlabel('Survived',fontsize = 15)
plt.show()
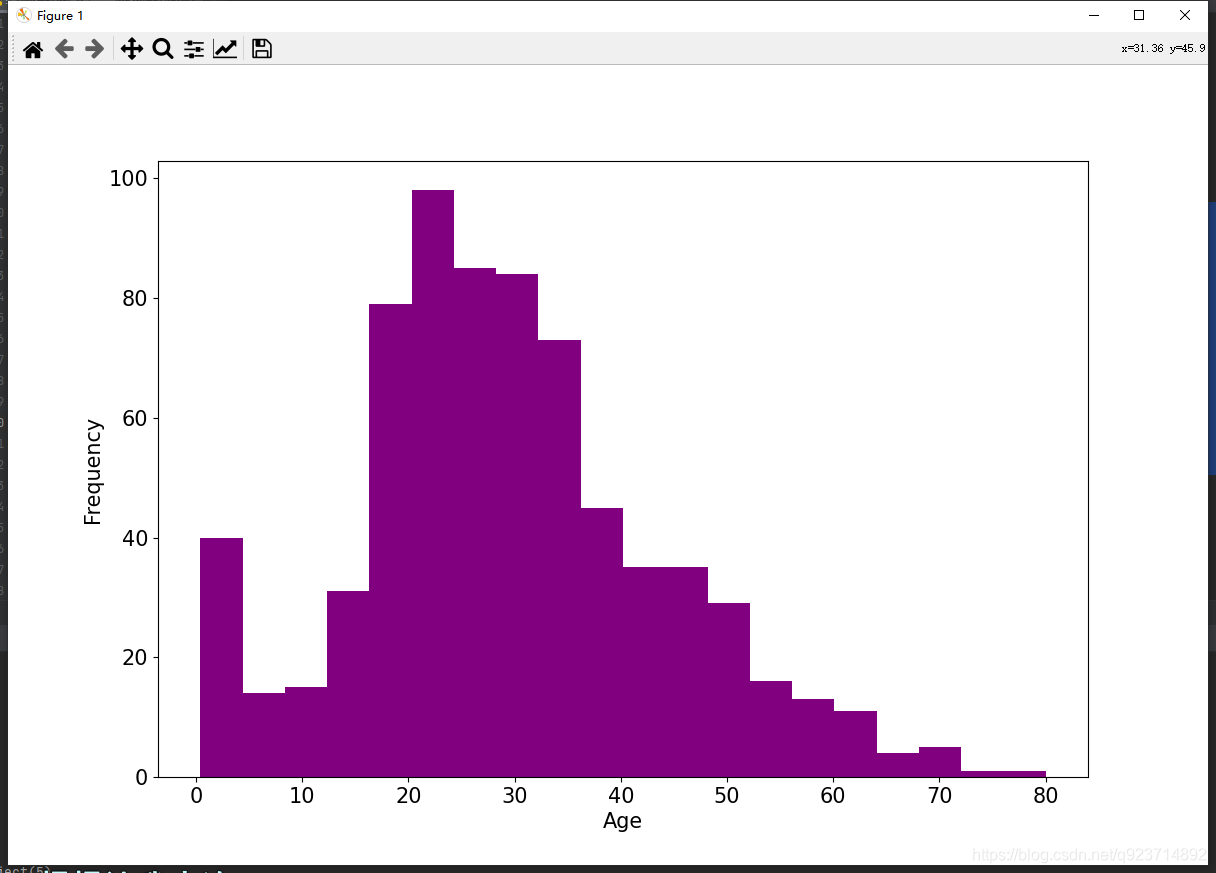
年龄分布情况
#年龄分布情况
ax = train_data['Age'].plot(kind = 'hist',bins = 20,color = 'purple',figsize = (12,8),fontsize = 15)
"""
hist方法常用的参数有以下几个
1. bins,控制直方图中的区间个数
2. color,指定柱子的填充色
3. edgecolor, 指定柱子边框的颜色
4. density,指定柱子高度对应的信息,有数值和频率两种选择
5. orientation,指定柱子的方向,有水平和垂直两个方向
6. histtype,绘图的类型
"""
ax.set_ylabel('Frequency',fontsize = 15)
ax.set_xlabel('Age',fontsize = 15)
plt.show()
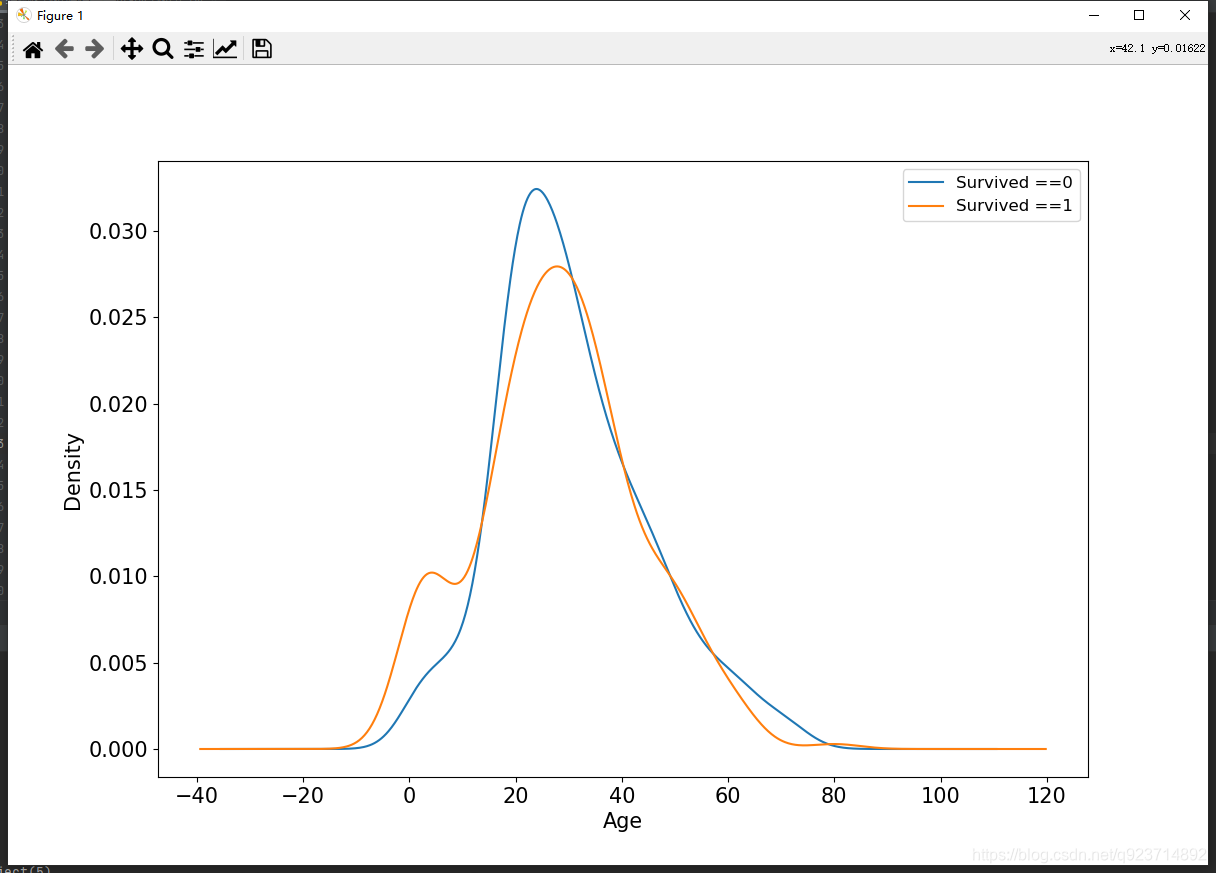
年龄和label的相关性
#年龄和label的相关性
ax = train_data.query('Survived == 0')['Age'].plot(kind = 'density',figsize = (12,8),fontsize = 15)
#使用python.query()函数对数据框进行(挑选行)的操作
train_data.query('Survived == 1')['Age'].plot(kind = 'density',figsize = (12,8),fontsize = 15)
ax.legend(['Survived ==0','Survived ==1'],fontsize = 12)
#plt.legend()函数主要的作用就是给图加上图例,plt.legend([x,y,z])里面的参数使用的是list的的形式将图表的的名称喂给这和函数。
ax.set_ylabel('Density',fontsize = 15)
ax.set_xlabel('Age',fontsize = 15)
plt.show()
数据预处理
这个步骤非常非常重要! 不仅要加载数据集,更重要的是如何处理NULL数据!
"""
数据预处理
"""
def preprocessing(dfdata):dfresult = pd.DataFrame() #存储结果#DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。#Pclass处理dfPclass = pd.get_dummies(dfdata['Pclass'])#对Pclass进行get_dummies,将该特征离散化dfPclass.columns = ['Pclass_'+str(x) for x in dfPclass.columns]dfresult = pd.concat([dfresult,dfPclass],axis=1)#concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合,axis: 需要合并链接的轴,0是行,1是列#SexdfSex = pd.get_dummies(dfdata['Sex'])dfresult = pd.concat([dfresult, dfSex], axis=1)#Agedfresult['Age'] = dfdata['Age'].fillna(0)dfresult['Age_null'] = pd.isna(dfdata['Age']).astype('int32')#pandas.isna(obj)检测array-like对象的缺失值# SibSp,Parch,Faredfresult['SibSp'] = dfdata['SibSp']dfresult['Parch'] = dfdata['Parch']dfresult['Fare'] = dfdata['Fare']# Carbindfresult['Cabin_null'] = pd.isna(dfdata['Cabin']).astype('int32')print(dfresult['Cabin_null'])# EmbarkeddfEmbarked = pd.get_dummies(dfdata['Embarked'], dummy_na=True)dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns]#DataFrame.columns属性以返回给定 DataFrame 的列标签。dfresult = pd.concat([dfresult, dfEmbarked], axis=1)return dfresult#获得训练x,y
x_train = preprocessing(train_data).values
y_train = train_data[['Survived']].values#获得测试x,y
x_test = preprocessing(test_data).values
y_test = test_datay[['Survived']].values# print("x_train.shape =", x_train.shape )
# print("x_test.shape =", x_test.shape )
# print("y_train.shape =", y_train.shape )
# print("y_test.shape =", y_test.shape )
这里重点讲解一下对数据缺失部分的处理!
以Age字段,我们通过fillna(0),将Age字段中的NaN替换成0
然后通过 pd.isna将空值点的地方记录下来(添加“年龄是否缺失”作为辅助特征)
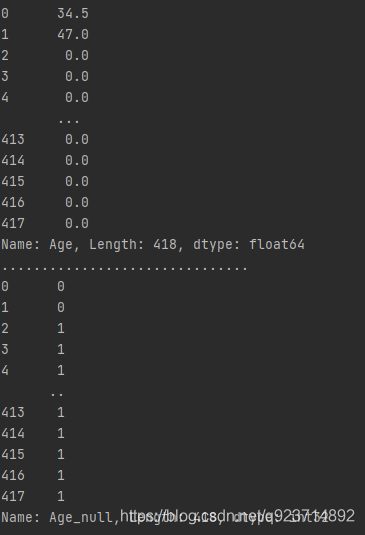
这里我把测试数据中的Age部分除了前两个后面全设置为NULL
然后把dfresult['Age'],dfresult['Age_null']打印出来:
可以看看下面这个文章,我收到了很多启发。
data是一个pandas.DataFrame数据对象,是从mysql读取的数据。由于有的列在数据库是int类型,而且有空值(Null),因此在从数据库抽取到df对象后,pandas自动将int转成float,比如10变成了10.0,15902912345变成了1.5902912345E10,Null变成了NaN。这种列由于存在NaN,因此不能用DataFrame.astype()方法转成int类型。
我们的目的就是尽量让pandas抽取的数据跟数据库“看上去”一致。比如原来是int类型的,如果被替换成float了,那么需要转换回去,原来是Null的,被pandas改成NaN了,需要替换成空字符串。由于pandas列的int类型不能为空,所以需统一转换成字符串类型。
为了达到将列转换成int类型原来的展现形式(可以是object类型,相当于str,此时10还是展示为10),且NaN转换成空值这个目的,可以采取如下步骤:
1.生成新的df对象,保存data里为NaN的位置标记
2.将data需要处理的列,NaN值替换为float能允许的类型,如0,下面会用到
3.将该列转换成int类型,此时10.0转换成10,1.5902912345E10转换成15902912345
4.将该列转换成object类型,此时所有数值按str类型原样保存
5.用NaN位置标记的df对象作为索引,替换原df对象中为0的值到空字符串
利用pandas.DataFrame.isna方法做替换(很棒的技巧)
进一步使用DataLoader和TensorDataset封装成可以迭代的数据管道。
"""
进一步使用DataLoader和TensorDataset封装成可以迭代的数据管道。
"""
dl_train = DataLoader(TensorDataset(torch.tensor(x_train).float(),torch.tensor(y_train).float()),shuffle = True, batch_size = 8)
dl_valid = DataLoader(TensorDataset(torch.tensor(x_test).float(),torch.tensor(y_test).float()),shuffle = False, batch_size = 8)# 测试数据管道
for features,labels in dl_train:print(features,labels)break
二,定义模型
使用Pytorch通常有三种方式构建模型:使用nn.Sequential按层顺序构建模型,继承nn.Module基类构建自定义模型,继承nn.Module基类构建模型并辅助应用模型容器进行封装。
此处选择使用最简单的nn.Sequential,按层顺序模型。
"""
二,定义模型
"""def creat_net():net = nn.Sequential()net.add_module("linear1",nn.Linear(15,20))net.add_module("relu1",nn.ReLU())net.add_module("linear2", nn.Linear(20, 15))net.add_module("relu2", nn.ReLU())net.add_module("linear3", nn.Linear(15, 1))net.add_module("sigmoid", nn.Sigmoid())return netnet = creat_net()
#print(net)
三,训练模型
"""
三,训练模型
"""from sklearn.metrics import accuracy_scoreloss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=net.parameters(),lr=0.01)
metric_func = lambda y_pred,y_true:accuracy_score(y_true.data.numpy(),y_pred.data.numpy()>0.5)
#lambda表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
#accuracy_score是分类准确率分数是指所有分类正确的百分比。
metric_name = "accuracy"
#metric就是准确率epochs = 10
log_step_freq = 30
dfhistory = pd.DataFrame(columns = ["epoch","loss",metric_name,"val_loss","val_"+metric_name])for epoch in range(1,epochs+1):#开始训练net.train()loss_sum = 0.0metric_sum = 0.0step = 1for step,(features,labels) in enumerate(dl_train,1):optimizer.zero_grad()#正向传播predictions = net(features)loss = loss_func(predictions,labels)metric = metric_func(predictions,labels)#反向传播loss.backward()optimizer.step()#打印batch日志loss_sum += loss.item()metric_sum += metric.item()if step%log_step_freq == 0:print(("[step = %d] loss: %.3f, " + metric_name + ": %.3f") %(step, loss_sum / step, metric_sum / step))#验证循环net.eval()val_loss_sum = 0.0val_metric_sum = 0.0val_step = 1for val_step, (features, labels) in enumerate(dl_valid, 1):predictions = net(features)val_loss = loss_func(predictions, labels)val_metric = metric_func(predictions,labels)val_loss_sum += val_loss.item()val_metric_sum += val_metric.item()#记录日志info = (epoch, loss_sum / step, metric_sum / step,val_loss_sum / val_step, val_metric_sum / val_step)dfhistory.loc[epoch - 1] = info# 打印epoch级别日志print(("\nEPOCH = %d, loss = %.3f," + metric_name + " = %.3f, val_loss = %.3f, " + "val_" + metric_name + " = %.3f")% info)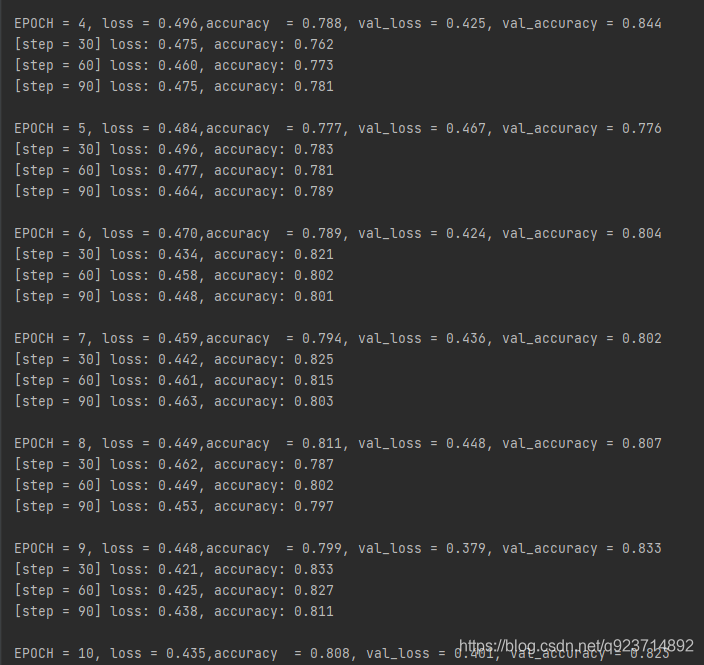
四,评估模型
"""
四,评估模型
"""
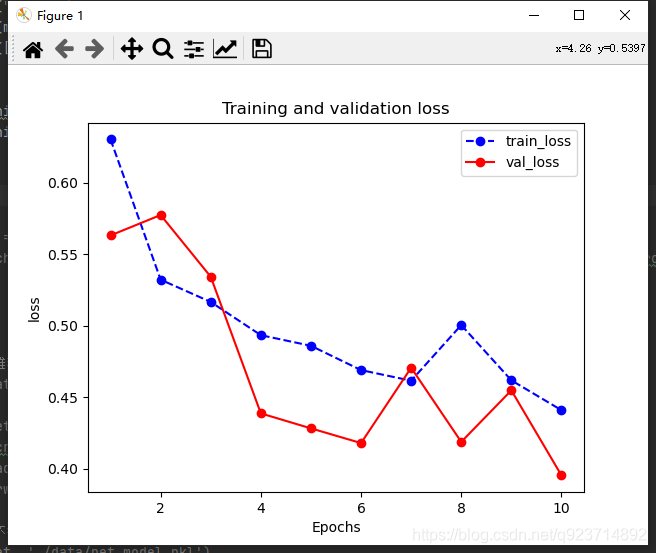
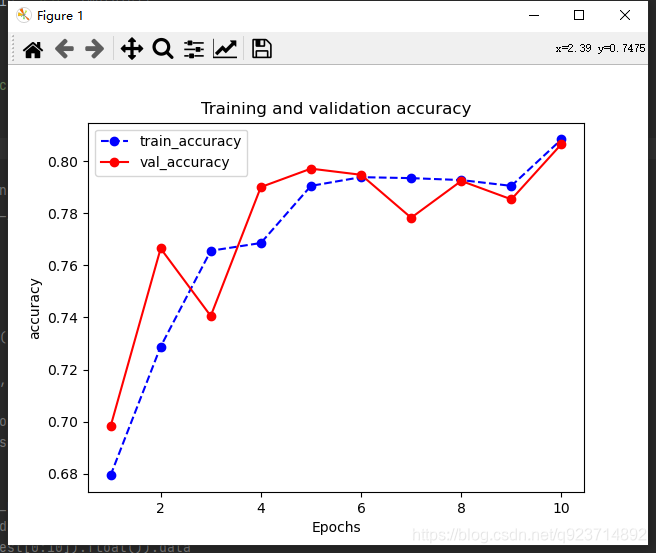
def plot_metric(dfhistory, metric):train_metrics = dfhistory[metric]val_metrics = dfhistory['val_'+metric]epochs = range(1, len(train_metrics) + 1)plt.plot(epochs, train_metrics, 'bo--')plt.plot(epochs, val_metrics, 'ro-')plt.title('Training and validation '+ metric)plt.xlabel("Epochs")plt.ylabel(metric)plt.legend(["train_"+metric, 'val_'+metric])plt.show()plot_metric(dfhistory,"loss")
plot_metric(dfhistory,"accuracy")
这里补充一下 dfhistory
dfhistory来源于第三部分训练模型中:
dfhistory = pd.DataFrame(columns = ["epoch","loss",metric_name,"val_loss","val_"+metric_name])
DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。
dfhistory的作用就是跟踪数据,在训练的过程中记录每一步的训练结果。
通过在dfhistory调取训练数据和测试数据进行对比绘图!
结果展示:
五,使用模型
"""
五,使用模型
"""
y_pred_probs = net(torch.tensor(x_test[0:10]).float()).data
y_pred = torch.where(y_pred_probs>0.5,torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs))六,保存模型
"""
# 六,保存模型
"""
#保存模型参数(推荐)
print(net.state_dict().keys())
# 保存模型参数
torch.save(net.state_dict(), "./data/net_parameter.pkl")
net_clone = creat_net()
net_clone.load_state_dict(torch.load("./data/net_parameter.pkl"))
net_clone.forward(torch.tensor(x_test[0:10]).float()).data#保存完整模型(不推荐)
torch.save(net, './data/net_model.pkl')
net_loaded = torch.load('./data/net_model.pkl')
net_loaded(torch.tensor(x_test[0:10]).float()).data
完整代码:
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from torch import nn
from torch.utils.data import Dataset,DataLoader,TensorDataset"""
一,准备数据
"""#数据读取
train_data = pd.read_csv('./data/titanic/train.csv')
test_data = pd.read_csv('./data/titanic/test.csv')
test_datay = pd.read_csv('./data/titanic/titanic.csv')
#print(train_data.head(10)) #打印训练数据前十个train_data.info() #查看训练数据有没有未知的的
test_data.info() #查看测试数据有没有未知的的# #查看各部分分布情况
#
# #幸存情况
# ax = train_data['Survived'].value_counts().plot(kind = 'bar',figsize = (12,8),fontsize =15,rot = 0)
# #value_counts是查询有多少个不同值且每个不同值有多少个重复的
# ax.set_ylabel('Counts',fontsize = 15)
# ax.set_xlabel('Survived',fontsize = 15)
# plt.show()
#
# #年龄分布情况
# ax = train_data['Age'].plot(kind = 'hist',bins = 20,color = 'purple',figsize = (12,8),fontsize = 15)
# """
# hist方法常用的参数有以下几个
# 1. bins,控制直方图中的区间个数
# 2. color,指定柱子的填充色
# 3. edgecolor, 指定柱子边框的颜色
# 4. density,指定柱子高度对应的信息,有数值和频率两种选择
# 5. orientation,指定柱子的方向,有水平和垂直两个方向
# 6. histtype,绘图的类型
# """
# ax.set_ylabel('Frequency',fontsize = 15)
# ax.set_xlabel('Age',fontsize = 15)
# plt.show()
#
# #年龄和label的相关性
# ax = train_data.query('Survived == 0')['Age'].plot(kind = 'density',figsize = (12,8),fontsize = 15)
# #使用python.query()函数对数据框进行(挑选行)的操作
# train_data.query('Survived == 1')['Age'].plot(kind = 'density',figsize = (12,8),fontsize = 15)
# ax.legend(['Survived ==0','Survived ==1'],fontsize = 12)
# #plt.legend()函数主要的作用就是给图加上图例,plt.legend([x,y,z])里面的参数使用的是list的的形式将图表的的名称喂给这和函数。
# ax.set_ylabel('Density',fontsize = 15)
# ax.set_xlabel('Age',fontsize = 15)
# plt.show()
#
"""
数据预处理
"""
def preprocessing(dfdata):dfresult = pd.DataFrame() #存储结果#DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。#Pclass处理dfPclass = pd.get_dummies(dfdata['Pclass'])#对Pclass进行get_dummies,将该特征离散化dfPclass.columns = ['Pclass_'+str(x) for x in dfPclass.columns]dfresult = pd.concat([dfresult,dfPclass],axis=1)#concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合,axis: 需要合并链接的轴,0是行,1是列#SexdfSex = pd.get_dummies(dfdata['Sex'])dfresult = pd.concat([dfresult, dfSex], axis=1)#Agedfresult['Age'] = dfdata['Age'].fillna(0)dfresult['Age_null'] = pd.isna(dfdata['Age']).astype('int32')#pandas.isna(obj)检测array-like对象的缺失值# SibSp,Parch,Faredfresult['SibSp'] = dfdata['SibSp']dfresult['Parch'] = dfdata['Parch']dfresult['Fare'] = dfdata['Fare']# Carbindfresult['Cabin_null'] = pd.isna(dfdata['Cabin']).astype('int32')# EmbarkeddfEmbarked = pd.get_dummies(dfdata['Embarked'], dummy_na=True)dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns]#DataFrame.columns属性以返回给定 DataFrame 的列标签。dfresult = pd.concat([dfresult, dfEmbarked], axis=1)return dfresult#获得训练x,y
x_train = preprocessing(train_data).values
y_train = train_data[['Survived']].values#获得测试x,y
x_test = preprocessing(test_data).values
y_test = test_datay[['Survived']].values# print("x_train.shape =", x_train.shape )
# print("x_test.shape =", x_test.shape )
# print("y_train.shape =", y_train.shape )
# print("y_test.shape =", y_test.shape )
#
"""
进一步使用DataLoader和TensorDataset封装成可以迭代的数据管道。
"""
dl_train = DataLoader(TensorDataset(torch.tensor(x_train).float(),torch.tensor(y_train).float()),shuffle = True, batch_size = 8)
dl_valid = DataLoader(TensorDataset(torch.tensor(x_test).float(),torch.tensor(y_test).float()),shuffle = False, batch_size = 8)
#
# # #测试数据管道
# for features,labels in dl_valid:
# print(features,labels)
# break
#
"""
二,定义模型
"""def creat_net():net = nn.Sequential()net.add_module("linear1",nn.Linear(15,20))net.add_module("relu1",nn.ReLU())net.add_module("linear2", nn.Linear(20, 15))net.add_module("relu2", nn.ReLU())net.add_module("linear3", nn.Linear(15, 1))net.add_module("sigmoid", nn.Sigmoid())return netnet = creat_net()
#print(net)"""
三,训练模型
"""from sklearn.metrics import accuracy_scoreloss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=net.parameters(),lr=0.01)
metric_func = lambda y_pred,y_true:accuracy_score(y_true.data.numpy(),y_pred.data.numpy()>0.5)
#lambda表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
#accuracy_score是分类准确率分数是指所有分类正确的百分比。
metric_name = "accuracy"
#metric就是准确率epochs = 10
log_step_freq = 30
dfhistory = pd.DataFrame(columns = ["epoch","loss",metric_name,"val_loss","val_"+metric_name])for epoch in range(1,epochs+1):#开始训练net.train()loss_sum = 0.0metric_sum = 0.0step = 1for step,(features,labels) in enumerate(dl_train,1):optimizer.zero_grad()#正向传播predictions = net(features)loss = loss_func(predictions,labels)metric = metric_func(predictions,labels)#反向传播loss.backward()optimizer.step()#打印batch日志loss_sum += loss.item()metric_sum += metric.item()if step%log_step_freq == 0:print(("[step = %d] loss: %.3f, " + metric_name + ": %.3f") %(step, loss_sum / step, metric_sum / step))#验证循环net.eval()val_loss_sum = 0.0val_metric_sum = 0.0val_step = 1for val_step, (features, labels) in enumerate(dl_valid, 1):predictions = net(features)val_loss = loss_func(predictions, labels)val_metric = metric_func(predictions,labels)val_loss_sum += val_loss.item()val_metric_sum += val_metric.item()#记录日志info = (epoch, loss_sum / step, metric_sum / step,val_loss_sum / val_step, val_metric_sum / val_step)dfhistory.loc[epoch - 1] = info# 打印epoch级别日志print(("\nEPOCH = %d, loss = %.3f," + metric_name + " = %.3f, val_loss = %.3f, " + "val_" + metric_name + " = %.3f")% info)"""
四,评估模型
"""
def plot_metric(dfhistory, metric):train_metrics = dfhistory[metric]val_metrics = dfhistory['val_'+metric]epochs = range(1, len(train_metrics) + 1)plt.plot(epochs, train_metrics, 'bo--')plt.plot(epochs, val_metrics, 'ro-')plt.title('Training and validation '+ metric)plt.xlabel("Epochs")plt.ylabel(metric)plt.legend(["train_"+metric, 'val_'+metric])plt.show()plot_metric(dfhistory,"loss")
plot_metric(dfhistory,"accuracy")"""
五,使用模型
"""
y_pred_probs = net(torch.tensor(x_test[0:10]).float()).data
y_pred = torch.where(y_pred_probs>0.5,torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs))# """
# # 六,保存模型
# """
# #保存模型参数(推荐)
# print(net.state_dict().keys())
# # 保存模型参数
# torch.save(net.state_dict(), "./data/net_parameter.pkl")
# net_clone = creat_net()
# net_clone.load_state_dict(torch.load("./data/net_parameter.pkl"))
# net_clone.forward(torch.tensor(x_test[0:10]).float()).data
#
# #保存完整模型(不推荐)
# torch.save(net, './data/net_model.pkl')
# net_loaded = torch.load('./data/net_model.pkl')
# net_loaded(torch.tensor(x_test[0:10]).float()).data

















)
![【洛谷算法题】P1046-[NOIP2005 普及组] 陶陶摘苹果【入门2分支结构】Java题解](http://pic.xiahunao.cn/【洛谷算法题】P1046-[NOIP2005 普及组] 陶陶摘苹果【入门2分支结构】Java题解)