算命数据
Real Estate Sale Prices, Regression, and Classification: Data Science is the Future of Fortune Telling
房地产销售价格,回归和分类:数据科学是算命的未来
As we all know, I am unusually blessed with totally-real psychic abilities.
众所周知,我拥有非凡的心理能力。
My background as a psychic extends way back to my childhood. On my sixth birthday, my mother got me a full astrological prediction printed out for the next year of my life. I, of course, was disappointed. Not because I was too young for uncanny predictions of the future. But because, I already had the psychic abilities needed to predict my fate. Each morning, I would read the patterns of cheerio-residue leftover in my breakfast cereal bowls. Obviously. I had a system for making sure my future stayed bright!
我的通灵背景可以追溯到童年时代。 在我的六岁生日那天,母亲为我提供了有关生命的第二年的完整的占星术预测。 我当然感到失望。 不是因为我还太年轻,无法对未来做出不可思议的预测。 但是,因为我已经具备了预测命运的心理能力。 每天早晨,我都会在早餐谷物碗中阅读残留的麦角酒残留的图案。 明显。 我有一个系统来确保我的前途一片光明!
In all seriousness though, as a 20-year-old young Data Scientist now, I discover more and more similarities between the skills of a fortune teller and a data scientist. Finally, I’ll be able to put my years of useless-seeming, arcane knowledge to good use. You don’t believe me?
严肃地说,作为一个现年20岁的年轻数据科学家,我发现算命先生和数据科学家之间的技能越来越相似。 最后,我将能够充分利用我多年的无用的神秘知识。 你不相信我吗?
Well algorithms and machine learning are a perfect example of modern fortune telling in practice. Nowadays, the experience of finding invasive amazon ads personally customized to your own interests is near universal:
好的算法和机器学习是实践中现代算命的完美示例。 如今,找到针对您自己的兴趣量身定制的侵入性亚马逊广告的经验几乎普及了:

Machine learning is the process of teaching a computer to be able to predict future data points from its previous body of information. The main form of machine learning I focused on in my data science project, “Predicting Real Estate Sale Prices with the Ames, Iowa Housing Dataset,” is linear regression. This model creates a line of best fit over the dataset in order to predict the likelihood of a house being a certain price (if it has, say, 20,000 sq. ft., a finished garage, no fence, etc.)
机器学习是教会计算机能够从其先前的信息主体预测未来数据点的过程。 在我的数据科学项目中,我关注的机器学习的主要形式是“使用爱荷华州住房数据集的Ames预测房地产销售价格”,是线性回归。 该模型在数据集中创建一条最合适的线,以预测房屋达到一定价格的可能性(例如,如果房屋有20,000平方英尺,已建成的车库,没有围栏等)。
The following infographic, for example, represents my analysis of the relationship between Real Estate Sale Price (the X-axis) and Gross Living Area (the Y-axis). Outliers have been removed from this particular set of data, helping preserve the quality of my linear regression predictor. This relationship between Sale Price and Gross Living Area, in addition to many other factors that are correlated with Sale Price highly, become my tools to predict how a house of a certain demographic will be priced.
例如,以下信息图代表我对房地产销售价格(X轴)和总居住面积(Y轴)之间关系的分析。 已从此特定数据集中删除了离群值,有助于保持线性回归预测变量的质量。 销售价格和总居住面积之间的这种关系,除了与销售价格高度相关的许多其他因素外,还成为我预测特定人口的房屋如何定价的工具。
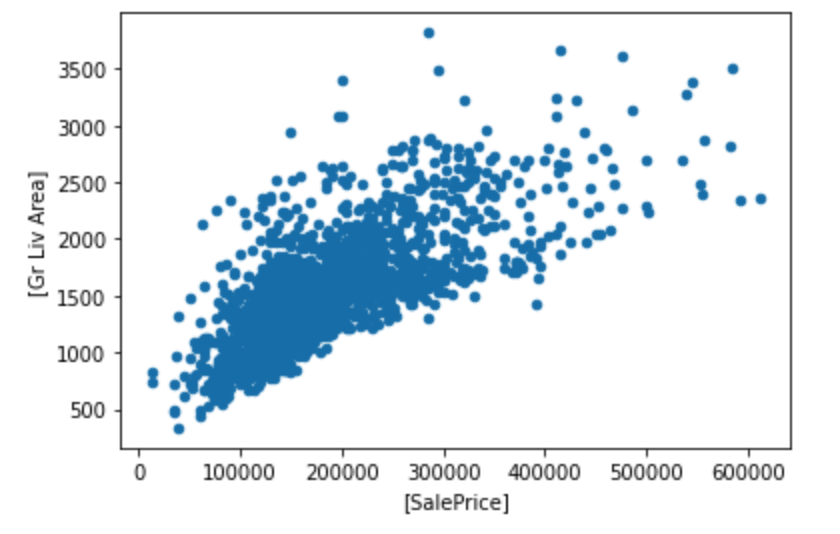
Ultimately, my linear regression model became able to predict houses with only a 27,000 Root Mean-Squared Error. This means that for any given house price prediction my model makes, the house’s actual (non-predicted) Sale Price will be on average $27,000 away from my prediction. Given the fact that the majority of houses sell for above $50,000 at least, this amount of error is relatively acceptable. However, my fortune-telling wizard powers now extend even further than just “Linear Regression.”
最终,我的线性回归模型开始能够预测只有27,000均方根误差的房屋。 这意味着,对于我的模型进行的任何给定的房价预测,该房屋的实际(未预测)售价均比我的预测平均低27,000美元。 考虑到大多数房屋的售价至少在50,000美元以上,因此这一误差是可以接受的。 但是,我算命向导的功能现在不仅可以扩展到“线性回归”。
I can also use “logistic regression” and “K-Nearest-Neighbors” classifiers to sort data, predicting which camps each of my data points will fall into. For instance, in my data science project “Tinder Problems or Relationship Advice?,” I scrape data from the subreddits for “Tinder” and “Relationship Advice” off of Reddit. Using a variety of Natural Language Processing techniques, I build a model that can predict whether or not that given post originates from “Tinder” or “Relationship Advice.”
我还可以使用“逻辑回归”和“ K最近邻”分类器对数据进行排序,以预测我的每个数据点将属于哪个阵营。 例如,在我的数据科学项目“ Tinder问题或关系建议?”中,我从Reddit的“ Tinder”和“ Relationship Advice”子目录中抓取了数据。 通过使用各种自然语言处理技术,我建立了一个模型,可以预测给定帖子是源自“ Tinder”还是“ Relationship Advice”。
Now, do I actually have the psychic ability to predict the future with ritual sacrifice? The world may never know. But, thankfully, I can just predict the future with Data Science skills like machine learning. I can create regressions to determine numerical predictions, classifiers to predict categorical outcomes, and I don’t even need to pull out my crystal ball.
现在,我真的有通过仪式牺牲来预测未来的心理能力吗? 世界可能永远不会知道。 但是,幸运的是,我可以借助诸如机器学习之类的数据科学技能来预测未来。 我可以创建回归来确定数值预测,创建分类器来预测分类结果,甚至不需要抽出水晶球。
And even better, unlike arcane sorcery, Data Science grounds all of its predictions in facts and previously gathered data. If anything, that’s the real magic of Data Science. I can take any amount of information in any field and, with enough time and effort, predict the future. What’s more magical than that?
甚至更好的是,与奥术法术不同,数据科学将其所有预测基于事实和先前收集的数据。 如果有的话,那就是数据科学的真正魔力。 我可以在任何领域获得大量信息,并花费足够的时间和精力来预测未来。 有什么比这更神奇的?
翻译自: https://medium.com/@jjp2196/data-scientist-or-fortune-telling-psychic-wizard-from-the-future-5e7a93025fe5
算命数据
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/389378.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

openai-gpt_为什么到处都看到GPT-3?

Pytorch高阶API示范——DNN二分类模型


puppet puppet模块、file模块

数据可视化及其重要性:Python

熊猫数据集_熊猫迈向数据科学的第三部分

Pytorch有关张量的各种操作
)
mongodb安装失败与解决方法(附安装教程)
![【洛谷算法题】P1046-[NOIP2005 普及组] 陶陶摘苹果【入门2分支结构】Java题解](http://pic.xiahunao.cn/【洛谷算法题】P1046-[NOIP2005 普及组] 陶陶摘苹果【入门2分支结构】Java题解)
【洛谷算法题】P1046-[NOIP2005 普及组] 陶陶摘苹果【入门2分支结构】Java题解
)
web性能优化(理论)

python多项式回归_如何在Python中实现多项式回归模型

充分利用UC berkeleys数据科学专业

文本二叉树折半查询及其截取值

nn.functional 和 nn.Module入门讲解

10.30PMP试题每日一题


ai驱动数据安全治理_AI驱动的Web数据收集解决方案的新起点

从Text文本中读值插入到数据库中

Dataset和DataLoader构建数据通道
