本文代码下载地址:我的github
本文主要讲解将CNN应用于人脸识别的流程,程序基于Python+numpy+theano+PIL开发,采用类似LeNet5的CNN模型,应用于olivettifaces人脸数据库,实现人脸识别的功能,模型的误差降到了5%以下。本程序只是个人学习过程的一个toy implement,样本很小,模型随时都会过拟合。
但是,本文意在理清程序开发CNN模型的具体步骤,特别是针对图像识别,从拿到图像数据库,到实现一个针对这个图像数据库的CNN模型,我觉得本文对这些流程的实现具有参考意义。
《本文目录》
一、olivettifaces人脸数据库介绍
二、CNN的基本“构件”(LogisticRegression、HiddenLayer、LeNetConvPoolLayer)
三、组建CNN模型,设置优化算法,应用于Olivetti Faces进行人脸识别
四、训练结果以及参数设置的讨论
五、利用训练好的参数初始化模型
六、一些需要说明的
一、olivettifaces人脸数据库介绍
Olivetti Faces是纽约大学的一个比较小的人脸库,由40个人的400张图片构成,即每个人的人脸图片为10张。每张图片的灰度级为8位,每个像素的灰度大小位于0-255之间,每张图片大小为64×64。如下图,这个图片大小是1190*942,一共有20*20张人脸,故每张人脸大小是(1190/20)*(942/20)即57*47=2679:

本文所用的训练数据就是这张图片,400个样本,40个类别,乍一看样本好像比较小,用CNN效果会好吗?先别下结论,请往下看。
要运行CNN算法,这张图片必须先转化为数组(或者说矩阵),这个用到python的图像库PIL,几行代码就可以搞定,具体的方法我之前刚好写过一篇文章,也是用这张图,考虑到文章冗长,就不复制过来了,链接在此:《利用Python PIL、cPickle读取和保存图像数据库》。
训练机器学习算法,我们一般将原始数据分成训练数据(training_set)、验证数据(validation_set)、测试数据(testing_set)。本程序将training_set、validation_set、testing_set分别设置为320、40、40个样本。它们的label为0~39,对应40个不同的人。这部分的代码如下:
- """
- 加载图像数据的函数,dataset_path即图像olivettifaces的路径
- 加载olivettifaces后,划分为train_data,valid_data,test_data三个数据集
- 函数返回train_data,valid_data,test_data以及对应的label
- """
- def load_data(dataset_path):
- img = Image.open(dataset_path)
- img_ndarray = numpy.asarray(img, dtype='float64')/256
- faces=numpy.empty((400,2679))
- for row in range(20):
- for column in range(20):
- faces[row*20+column]=numpy.ndarray.flatten(img_ndarray [row*57:(row+1)*57,column*47:(column+1)*47])
- label=numpy.empty(400)
- for i in range(40):
- label[i*10:i*10+10]=i
- label=label.astype(numpy.int)
- #分成训练集、验证集、测试集,大小如下
- train_data=numpy.empty((320,2679))
- train_label=numpy.empty(320)
- valid_data=numpy.empty((40,2679))
- valid_label=numpy.empty(40)
- test_data=numpy.empty((40,2679))
- test_label=numpy.empty(40)
- for i in range(40):
- train_data[i*8:i*8+8]=faces[i*10:i*10+8]
- train_label[i*8:i*8+8]=label[i*10:i*10+8]
- valid_data[i]=faces[i*10+8]
- valid_label[i]=label[i*10+8]
- test_data[i]=faces[i*10+9]
- test_label[i]=label[i*10+9]
- #将数据集定义成shared类型,才能将数据复制进GPU,利用GPU加速程序。
- def shared_dataset(data_x, data_y, borrow=True):
- shared_x = theano.shared(numpy.asarray(data_x,
- dtype=theano.config.floatX),
- borrow=borrow)
- shared_y = theano.shared(numpy.asarray(data_y,
- dtype=theano.config.floatX),
- borrow=borrow)
- return shared_x, T.cast(shared_y, 'int32')
- train_set_x, train_set_y = shared_dataset(train_data,train_label)
- valid_set_x, valid_set_y = shared_dataset(valid_data,valid_label)
- test_set_x, test_set_y = shared_dataset(test_data,test_label)
- rval = [(train_set_x, train_set_y), (valid_set_x, valid_set_y),
- (test_set_x, test_set_y)]
- return rval
二、CNN的基本“构件”(LogisticRegression、HiddenLayer、LeNetConvPoolLayer)
代码太长,就不贴具体的了,只给出框架,具体可以下载我的代码看看:
- #分类器,即CNN最后一层,采用逻辑回归(softmax)
- class LogisticRegression(object):
- def __init__(self, input, n_in, n_out):
- self.W = ....
- self.b = ....
- self.p_y_given_x = ...
- self.y_pred = ...
- self.params = ...
- def negative_log_likelihood(self, y):
- def errors(self, y):
- #全连接层,分类器前一层
- class HiddenLayer(object):
- def __init__(self, rng, input, n_in, n_out, W=None, b=None,activation=T.tanh):
- self.input = input
- self.W = ...
- self.b = ...
- lin_output = ...
- self.params = [self.W, self.b]
- #卷积+采样层(conv+maxpooling)
- class LeNetConvPoolLayer(object):
- def __init__(self, rng, input, filter_shape, image_shape, poolsize=(2, 2)):
- self.input = input
- self.W = ...
- self.b = ...
- # 卷积
- conv_out = ...
- # 子采样
- pooled_out =...
- self.output = ...
- self.params = [self.W, self.b]
三、组建CNN模型,设置优化算法,应用于Olivetti Faces进行人脸识别
上面定义好了CNN的几个基本“构件”,现在我们使用这些构件来组建CNN模型,本程序的CNN模型参考LeNet5,具体为:input+layer0(LeNetConvPoolLayer)+layer1(LeNetConvPoolLayer)+layer2(HiddenLayer)+layer3(LogisticRegression)
这是一个串联结构,代码也很好写,直接用第二部分定义好的各种layer去组建就行了,上一layer的输出接下一layer的输入,具体可以看看代码evaluate_olivettifaces函数中的“建立CNN模型”部分。
CNN模型组建好了,就剩下用优化算法求解了,优化算法采用批量随机梯度下降算法(MSGD),所以要先定义MSGD的一些要素,主要包括:代价函数,训练、验证、测试model、参数更新规则(即梯度下降)。这部分的代码在evaluate_olivettifaces函数中的“定义优化算法的一些基本要素”部分。
优化算法的基本要素也定义好了,接下来就要运用人脸图像数据集来训练这个模型了,训练过程有训练步数(n_epoch)的设置,每个epoch会遍历所有的训练数据(training_set),本程序中也就是320个人脸图。还有迭代次数iter,一次迭代遍历一个batch里的所有样本,具体为多少要看所设置的batch_size。关于参数的设定我在下面会讨论。这一部分的代码在evaluate_olivettifaces函数中的“训练CNN阶段”部分。
代码很长,只贴框架,具体可以下载我的代码看看:
- def evaluate_olivettifaces(learning_rate=0.05, n_epochs=200,
- dataset='olivettifaces.gif',
- nkerns=[5, 10], batch_size=40):
- #随机数生成器,用于初始化参数....
- #加载数据.....
- #计算各数据集的batch个数....
- #定义几个变量,x代表人脸数据,作为layer0的输入......
- ######################
- #建立CNN模型:
- #input+layer0(LeNetConvPoolLayer)+layer1(LeNetConvPoolLayer)+layer2(HiddenLayer)+layer3(LogisticRegression)
- ######################
- ...
- ....
- ......
- #########################
- # 定义优化算法的一些基本要素:代价函数,训练、验证、测试model、参数更新规则(即梯度下降)
- #########################
- ...
- ....
- ......
- #########################
- # 训练CNN阶段,寻找最优的参数。
- ########################
- ...
- .....
- .......
另外,值得一提的是,在训练CNN阶段,我们必须定时地保存模型的参数,这是在训练机器学习算法时一个经常会做的事情,这一部分的详细介绍我之前写过一篇文章《DeepLearning tutorial(2)机器学习算法在训练过程中保存参数》。简单来说,我们要保存CNN模型中layer0、layer1、layer2、layer3的参数,所以在“训练CNN阶段”这部分下面,有一句代码:
- save_params(layer0.params,layer1.params,layer2.params,layer3.params)
这个函数具体定义为:
- #保存训练参数的函数
- def save_params(param1,param2,param3,param4):
- import cPickle
- write_file = open('params.pkl', 'wb')
- cPickle.dump(param1, write_file, -1)
- cPickle.dump(param2, write_file, -1)
- cPickle.dump(param3, write_file, -1)
- cPickle.dump(param4, write_file, -1)
- write_file.close()
如果在其他算法中,你要保存的参数有五个六个甚至更多,那么改一下这个函数的参数就行啦。
四、训练结果以及参数设置的讨论
- 调节learning_rate
(2)nkerns=[20, 50], batch_size=40,poolsize=(2,2),learning_rate=0.01时,训练到epoch 60多时,validation-error降到5%,test-error降到15%
(3)nkerns=[20, 50], batch_size=40,poolsize=(2,2),learning_rate=0.05时,训练到epoch 36时,validation-error降到2.5%,test-error降到5%
PS:学习速率应该自适应地减小,是有专门的一些算法的,本程序没有实现这个功能,有时间再研究一下。
- 调节batch_size
回到本文的模型,首先因为我们train_dataset是320,valid_dataset和test_dataset都是40,所以batch_size最好都是40的因子,也就是能让40整除,比如40、20、10、5、2、1,否则会浪费一些样本,比如设置为30,则320/30=10,余数时20,这20个样本是没被利用的。并且,如果batch_size设置为30,则得出的validation-error和test-error只是30个样本的错误率,并不是全部40个样本的错误率。这是设置batch_size要注意的。特别是样本比较少的时候。
下面是我实验时的记录,固定其他参数,改变batch_size:
batch_size=1、2、5、10、20时,validation-error一直是97.5%,没降下来。我觉得可能是样本类别覆盖率过小,因为我们的数据是按类别排的,每个类别10个样本是连续排在一起的,batch_size等于20时其实只包含了两个类别,这样优化会很慢。
因此最后我将batch_size设为40,也就是valid_dataset和test_dataset的大小了,没办法,原始数据集样本太少了。一般我们都不会让batch_size达到valid_dataset和test_dataset的大小的。
- 关于n_epochs
n_epochs也就是最大的训练步数,比如设为200,那训练过程最多遍历你的数据集200遍,当遍历了200遍你的dataset时,程序会停止。n_epochs就相当于一个停止程序的控制参数,并不会影响CNN模型的优化程度和速度,只是一个控制程序结束的参数。
- nkerns=[20, 50]
20表示第一个卷积层的卷积核的个数,50表示第二个卷积层的卷积核的个数。这个我也是瞎调的,暂时没什么经验可以总结。
不过从理论上来说,卷积核的个数其实就代表了特征的个数,你提取的特征越多,可能最后分类就越准。但是,特征太多(卷积核太多),会增加参数的规模,加大了计算复杂度,而且有时候卷积核也不是越多越好,应根据具体的应用对象来确定。所以我觉得,CNN虽号称自动提取特征,免去复杂的特征工程,但是很多参数比如这里的nkerns还是需要去调节的,还是需要一些“人工”的。
下面是我的实验记录,固定batch_size=40,learning_rate=0.05,poolsize=(2,2):
(1)nkerns=[20, 50]时,训练到epoch 36时,validation-error降到2.5%,test-error降到5%
(2)nkerns=[10, 30]时,训练到epoch 46时,validation-error降到5%,test-error降到5%
(3)nkerns=[5, 10]时,训练到epoch 38时,validation-error降到5%,test-error降到7.5%
- poolsize=(2, 2)
poolzize在本程序中是设置为(2,2),即从一个2*2的区域里maxpooling出1个像素,说白了就算4和像素保留成1个像素。本例程中人脸图像大小是57*47,对这种小图像来说,(2,2)时比较合理的。如果你用的图像比较大,可以把poolsize设的大一点。
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++分割线+++++++++++++++++++++++++++++++++++++++++++
上面部分介绍完了CNN模型构建以及模型训练的过程,代码都在train_CNN_olivettifaces.py里面,训练完可以得到一个params.pkl文件,这个文件保存的就是最后的模型的参数,方便你以后直接使用这个模型。以后只需利用这些保存下来的参数来初始化CNN模型,就得到一个可以使用的CNN系统,将人脸图输入这个CNN系统,预测人脸图的类别。
接下来就介绍怎么使用训练好的参数的方法,这部分的代码放在use_CNN_olivettifaces.py文件中。
五、利用训练好的参数初始化模型
- self.W = params_W
- self.b = params_b
params_W,params_b就是从params.pkl文件中读取来的,读取的函数:
- #读取之前保存的训练参数
- #layer0_params~layer3_params都是包含W和b的,layer*_params[0]是W,layer*_params[1]是b
- def load_params(params_file):
- f=open(params_file,'rb')
- layer0_params=cPickle.load(f)
- layer1_params=cPickle.load(f)
- layer2_params=cPickle.load(f)
- layer3_params=cPickle.load(f)
- f.close()
- return layer0_params,layer1_params,layer2_params,layer3_params
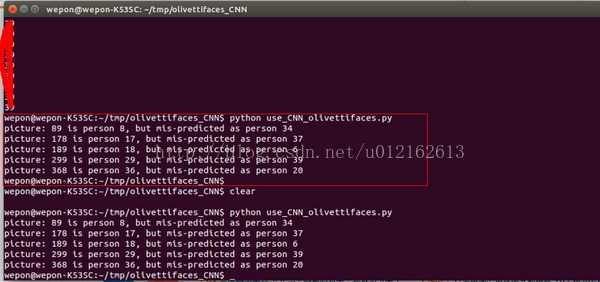

六、一些需要说明的
@author:wepon
@blog:http://blog.csdn.net/u012162613/article/details/43277187
本文代码下载地址:我的github
本文主要讲解将CNN应用于人脸识别的流程,程序基于Python+numpy+theano+PIL开发,采用类似LeNet5的CNN模型,应用于olivettifaces人脸数据库,实现人脸识别的功能,模型的误差降到了5%以下。本程序只是个人学习过程的一个toy implement,样本很小,模型随时都会过拟合。
但是,本文意在理清程序开发CNN模型的具体步骤,特别是针对图像识别,从拿到图像数据库,到实现一个针对这个图像数据库的CNN模型,我觉得本文对这些流程的实现具有参考意义。
《本文目录》
一、olivettifaces人脸数据库介绍
二、CNN的基本“构件”(LogisticRegression、HiddenLayer、LeNetConvPoolLayer)
三、组建CNN模型,设置优化算法,应用于Olivetti Faces进行人脸识别
四、训练结果以及参数设置的讨论
五、利用训练好的参数初始化模型
六、一些需要说明的
一、olivettifaces人脸数据库介绍
Olivetti Faces是纽约大学的一个比较小的人脸库,由40个人的400张图片构成,即每个人的人脸图片为10张。每张图片的灰度级为8位,每个像素的灰度大小位于0-255之间,每张图片大小为64×64。如下图,这个图片大小是1190*942,一共有20*20张人脸,故每张人脸大小是(1190/20)*(942/20)即57*47=2679:
本文所用的训练数据就是这张图片,400个样本,40个类别,乍一看样本好像比较小,用CNN效果会好吗?先别下结论,请往下看。
要运行CNN算法,这张图片必须先转化为数组(或者说矩阵),这个用到python的图像库PIL,几行代码就可以搞定,具体的方法我之前刚好写过一篇文章,也是用这张图,考虑到文章冗长,就不复制过来了,链接在此:《利用Python PIL、cPickle读取和保存图像数据库》。
训练机器学习算法,我们一般将原始数据分成训练数据(training_set)、验证数据(validation_set)、测试数据(testing_set)。本程序将training_set、validation_set、testing_set分别设置为320、40、40个样本。它们的label为0~39,对应40个不同的人。这部分的代码如下:
- """
- 加载图像数据的函数,dataset_path即图像olivettifaces的路径
- 加载olivettifaces后,划分为train_data,valid_data,test_data三个数据集
- 函数返回train_data,valid_data,test_data以及对应的label
- """
- def load_data(dataset_path):
- img = Image.open(dataset_path)
- img_ndarray = numpy.asarray(img, dtype='float64')/256
- faces=numpy.empty((400,2679))
- for row in range(20):
- for column in range(20):
- faces[row*20+column]=numpy.ndarray.flatten(img_ndarray [row*57:(row+1)*57,column*47:(column+1)*47])
- label=numpy.empty(400)
- for i in range(40):
- label[i*10:i*10+10]=i
- label=label.astype(numpy.int)
- #分成训练集、验证集、测试集,大小如下
- train_data=numpy.empty((320,2679))
- train_label=numpy.empty(320)
- valid_data=numpy.empty((40,2679))
- valid_label=numpy.empty(40)
- test_data=numpy.empty((40,2679))
- test_label=numpy.empty(40)
- for i in range(40):
- train_data[i*8:i*8+8]=faces[i*10:i*10+8]
- train_label[i*8:i*8+8]=label[i*10:i*10+8]
- valid_data[i]=faces[i*10+8]
- valid_label[i]=label[i*10+8]
- test_data[i]=faces[i*10+9]
- test_label[i]=label[i*10+9]
- #将数据集定义成shared类型,才能将数据复制进GPU,利用GPU加速程序。
- def shared_dataset(data_x, data_y, borrow=True):
- shared_x = theano.shared(numpy.asarray(data_x,
- dtype=theano.config.floatX),
- borrow=borrow)
- shared_y = theano.shared(numpy.asarray(data_y,
- dtype=theano.config.floatX),
- borrow=borrow)
- return shared_x, T.cast(shared_y, 'int32')
- train_set_x, train_set_y = shared_dataset(train_data,train_label)
- valid_set_x, valid_set_y = shared_dataset(valid_data,valid_label)
- test_set_x, test_set_y = shared_dataset(test_data,test_label)
- rval = [(train_set_x, train_set_y), (valid_set_x, valid_set_y),
- (test_set_x, test_set_y)]
- return rval
二、CNN的基本“构件”(LogisticRegression、HiddenLayer、LeNetConvPoolLayer)
代码太长,就不贴具体的了,只给出框架,具体可以下载我的代码看看:
- #分类器,即CNN最后一层,采用逻辑回归(softmax)
- class LogisticRegression(object):
- def __init__(self, input, n_in, n_out):
- self.W = ....
- self.b = ....
- self.p_y_given_x = ...
- self.y_pred = ...
- self.params = ...
- def negative_log_likelihood(self, y):
- def errors(self, y):
- #全连接层,分类器前一层
- class HiddenLayer(object):
- def __init__(self, rng, input, n_in, n_out, W=None, b=None,activation=T.tanh):
- self.input = input
- self.W = ...
- self.b = ...
- lin_output = ...
- self.params = [self.W, self.b]
- #卷积+采样层(conv+maxpooling)
- class LeNetConvPoolLayer(object):
- def __init__(self, rng, input, filter_shape, image_shape, poolsize=(2, 2)):
- self.input = input
- self.W = ...
- self.b = ...
- # 卷积
- conv_out = ...
- # 子采样
- pooled_out =...
- self.output = ...
- self.params = [self.W, self.b]
三、组建CNN模型,设置优化算法,应用于Olivetti Faces进行人脸识别
上面定义好了CNN的几个基本“构件”,现在我们使用这些构件来组建CNN模型,本程序的CNN模型参考LeNet5,具体为:input+layer0(LeNetConvPoolLayer)+layer1(LeNetConvPoolLayer)+layer2(HiddenLayer)+layer3(LogisticRegression)
这是一个串联结构,代码也很好写,直接用第二部分定义好的各种layer去组建就行了,上一layer的输出接下一layer的输入,具体可以看看代码evaluate_olivettifaces函数中的“建立CNN模型”部分。
CNN模型组建好了,就剩下用优化算法求解了,优化算法采用批量随机梯度下降算法(MSGD),所以要先定义MSGD的一些要素,主要包括:代价函数,训练、验证、测试model、参数更新规则(即梯度下降)。这部分的代码在evaluate_olivettifaces函数中的“定义优化算法的一些基本要素”部分。
优化算法的基本要素也定义好了,接下来就要运用人脸图像数据集来训练这个模型了,训练过程有训练步数(n_epoch)的设置,每个epoch会遍历所有的训练数据(training_set),本程序中也就是320个人脸图。还有迭代次数iter,一次迭代遍历一个batch里的所有样本,具体为多少要看所设置的batch_size。关于参数的设定我在下面会讨论。这一部分的代码在evaluate_olivettifaces函数中的“训练CNN阶段”部分。
代码很长,只贴框架,具体可以下载我的代码看看:
- def evaluate_olivettifaces(learning_rate=0.05, n_epochs=200,
- dataset='olivettifaces.gif',
- nkerns=[5, 10], batch_size=40):
- #随机数生成器,用于初始化参数....
- #加载数据.....
- #计算各数据集的batch个数....
- #定义几个变量,x代表人脸数据,作为layer0的输入......
- ######################
- #建立CNN模型:
- #input+layer0(LeNetConvPoolLayer)+layer1(LeNetConvPoolLayer)+layer2(HiddenLayer)+layer3(LogisticRegression)
- ######################
- ...
- ....
- ......
- #########################
- # 定义优化算法的一些基本要素:代价函数,训练、验证、测试model、参数更新规则(即梯度下降)
- #########################
- ...
- ....
- ......
- #########################
- # 训练CNN阶段,寻找最优的参数。
- ########################
- ...
- .....
- .......
另外,值得一提的是,在训练CNN阶段,我们必须定时地保存模型的参数,这是在训练机器学习算法时一个经常会做的事情,这一部分的详细介绍我之前写过一篇文章《DeepLearning tutorial(2)机器学习算法在训练过程中保存参数》。简单来说,我们要保存CNN模型中layer0、layer1、layer2、layer3的参数,所以在“训练CNN阶段”这部分下面,有一句代码:
- save_params(layer0.params,layer1.params,layer2.params,layer3.params)
这个函数具体定义为:
- #保存训练参数的函数
- def save_params(param1,param2,param3,param4):
- import cPickle
- write_file = open('params.pkl', 'wb')
- cPickle.dump(param1, write_file, -1)
- cPickle.dump(param2, write_file, -1)
- cPickle.dump(param3, write_file, -1)
- cPickle.dump(param4, write_file, -1)
- write_file.close()
如果在其他算法中,你要保存的参数有五个六个甚至更多,那么改一下这个函数的参数就行啦。
四、训练结果以及参数设置的讨论
- 调节learning_rate
(2)nkerns=[20, 50], batch_size=40,poolsize=(2,2),learning_rate=0.01时,训练到epoch 60多时,validation-error降到5%,test-error降到15%
(3)nkerns=[20, 50], batch_size=40,poolsize=(2,2),learning_rate=0.05时,训练到epoch 36时,validation-error降到2.5%,test-error降到5%
PS:学习速率应该自适应地减小,是有专门的一些算法的,本程序没有实现这个功能,有时间再研究一下。
- 调节batch_size
回到本文的模型,首先因为我们train_dataset是320,valid_dataset和test_dataset都是40,所以batch_size最好都是40的因子,也就是能让40整除,比如40、20、10、5、2、1,否则会浪费一些样本,比如设置为30,则320/30=10,余数时20,这20个样本是没被利用的。并且,如果batch_size设置为30,则得出的validation-error和test-error只是30个样本的错误率,并不是全部40个样本的错误率。这是设置batch_size要注意的。特别是样本比较少的时候。
下面是我实验时的记录,固定其他参数,改变batch_size:
batch_size=1、2、5、10、20时,validation-error一直是97.5%,没降下来。我觉得可能是样本类别覆盖率过小,因为我们的数据是按类别排的,每个类别10个样本是连续排在一起的,batch_size等于20时其实只包含了两个类别,这样优化会很慢。
因此最后我将batch_size设为40,也就是valid_dataset和test_dataset的大小了,没办法,原始数据集样本太少了。一般我们都不会让batch_size达到valid_dataset和test_dataset的大小的。
- 关于n_epochs
n_epochs也就是最大的训练步数,比如设为200,那训练过程最多遍历你的数据集200遍,当遍历了200遍你的dataset时,程序会停止。n_epochs就相当于一个停止程序的控制参数,并不会影响CNN模型的优化程度和速度,只是一个控制程序结束的参数。
- nkerns=[20, 50]
20表示第一个卷积层的卷积核的个数,50表示第二个卷积层的卷积核的个数。这个我也是瞎调的,暂时没什么经验可以总结。
不过从理论上来说,卷积核的个数其实就代表了特征的个数,你提取的特征越多,可能最后分类就越准。但是,特征太多(卷积核太多),会增加参数的规模,加大了计算复杂度,而且有时候卷积核也不是越多越好,应根据具体的应用对象来确定。所以我觉得,CNN虽号称自动提取特征,免去复杂的特征工程,但是很多参数比如这里的nkerns还是需要去调节的,还是需要一些“人工”的。
下面是我的实验记录,固定batch_size=40,learning_rate=0.05,poolsize=(2,2):
(1)nkerns=[20, 50]时,训练到epoch 36时,validation-error降到2.5%,test-error降到5%
(2)nkerns=[10, 30]时,训练到epoch 46时,validation-error降到5%,test-error降到5%
(3)nkerns=[5, 10]时,训练到epoch 38时,validation-error降到5%,test-error降到7.5%
- poolsize=(2, 2)
poolzize在本程序中是设置为(2,2),即从一个2*2的区域里maxpooling出1个像素,说白了就算4和像素保留成1个像素。本例程中人脸图像大小是57*47,对这种小图像来说,(2,2)时比较合理的。如果你用的图像比较大,可以把poolsize设的大一点。
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++分割线+++++++++++++++++++++++++++++++++++++++++++
上面部分介绍完了CNN模型构建以及模型训练的过程,代码都在train_CNN_olivettifaces.py里面,训练完可以得到一个params.pkl文件,这个文件保存的就是最后的模型的参数,方便你以后直接使用这个模型。以后只需利用这些保存下来的参数来初始化CNN模型,就得到一个可以使用的CNN系统,将人脸图输入这个CNN系统,预测人脸图的类别。
接下来就介绍怎么使用训练好的参数的方法,这部分的代码放在use_CNN_olivettifaces.py文件中。
五、利用训练好的参数初始化模型
- self.W = params_W
- self.b = params_b
params_W,params_b就是从params.pkl文件中读取来的,读取的函数:
- #读取之前保存的训练参数
- #layer0_params~layer3_params都是包含W和b的,layer*_params[0]是W,layer*_params[1]是b
- def load_params(params_file):
- f=open(params_file,'rb')
- layer0_params=cPickle.load(f)
- layer1_params=cPickle.load(f)
- layer2_params=cPickle.load(f)
- layer3_params=cPickle.load(f)
- f.close()
- return layer0_params,layer1_params,layer2_params,layer3_params