更多内容,欢迎关注微信公众号:全菜工程师小辉~
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
LRU算法的表现
- 新数据插入到容器头部;
- 每当缓存命中(即缓存数据被访问),则将数据移到容器头部;
- 当容器满的时候,将容器尾部的数据丢弃。
实现LRU的方法
- 用一个数组来存储数据,给每一个数据项标记一个访问时间戳,每次插入新数据项的时候,先把数组中所有的数据项的时间戳自增,并将新数据项的时间戳置为0并插入到数组中。每次访问数组中的数据项的时候,将被访问的数据项的时间戳置为0。当数组空间已满时,将时间戳最大的数据项淘汰。
- 利用一个链表来实现,每次新插入数据的时候将新数据插到链表的头部;每次缓存命中(即数据被访问),则将数据移到链表头部;那么当链表满的时候,就将链表尾部的数据丢弃。
- 利用链表和HashMap。当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1。这样一来在链表尾部的节点就是最近最久未访问的数据项。HashMap提供快速定位功能,具体可以参见下文。
比较三种方法优劣:
对于第一种方法,需要不停地维护数据项的访问时间戳,另外,在插入数据、删除数据以及访问数据时,时间复杂度都是O(n)。对于第二种方法,链表在定位数据的时候时间复杂度为O(n)。所以在一般使用第三种方式来是实现LRU算法。
LinkedHashMap的实现方案
LinkedHashMap继承于HashMap,来一张LinkedHashMap的结构图
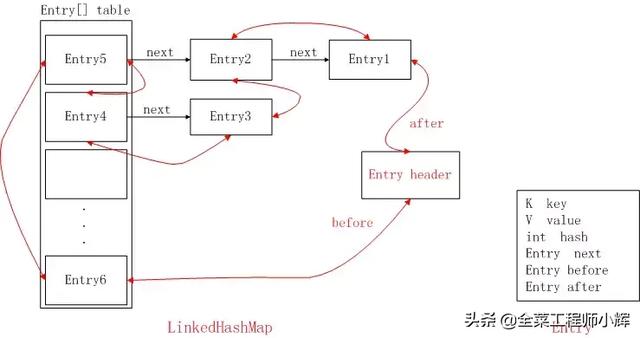
LinkedHashMap的结构图
其中next是用于维护HashMap指定table位置上连接的Entry的顺序的,before、after是用于维护Entry插入的先后顺序的
LinkedHashMap底层就是用的HashMap加双链表实现的。实现LRU算法主要有两个注意的地方:
- LinkedHashMap本身已经实现了按照访问顺序的存储。LinkedHashMap的构造函数中有一个accessOrder参数,平时使用LinkedHashMap一般该值为false。不过在LRU算法实现中我们要设置该参数为true,当构造函数中为true时,我们每次调用get方法时都会调用该方法,将我们访问的Node移动到最后,使之成为尾部节点,从而改变了数据在LinkedHashMap中的存储顺序。
- LinkedHashMap中本身就实现了一个方法removeEldestEntry用于判断是否需要移除最不常读取的数,方法默认是直接返回false,不会移除元素,所以需要重写该方法。即当缓存满后就移除最不常用的数。
所以使用LinkedHashMap很简单的实现了LRU算法,代码如下。另外如果生产中使用的话,一定要记得线程安全加锁。
class LRULinkedHashMap extends LinkedHashMap { // 定义缓存的容量 private int capacity; // 带参数的构造器 LRULinkedHashMap(int capacity){ // 第三个参数为accessOrder super(16,0.75f,true); // 传入指定的缓存最大容量 this.capacity=capacity; } // 实现LRU的关键方法,如果map里面的元素个数大于了缓存最大容量,则删除链表的顶端元素 @Override public boolean removeEldestEntry(Map.Entry eldest){ return size()>capacity; } }更多内容,欢迎关注微信公众号:全菜工程师小辉~


![[蓝桥杯2015初赛]手链样式-思维+next_permutation枚举(好题)](http://pic.xiahunao.cn/[蓝桥杯2015初赛]手链样式-思维+next_permutation枚举(好题))
)

开源C# WPF控件库《AduSkin – UI》)
![[NOIP2008 提高组] 笨小猴-map容器用来标记](http://pic.xiahunao.cn/[NOIP2008 提高组] 笨小猴-map容器用来标记)




![[蓝桥杯2015初赛]生命之树-求树的最大子树权值和](http://pic.xiahunao.cn/[蓝桥杯2015初赛]生命之树-求树的最大子树权值和)


![[蓝桥杯2016初赛]剪邮票-dfs+next_permutation(好题)](http://pic.xiahunao.cn/[蓝桥杯2016初赛]剪邮票-dfs+next_permutation(好题))

的日志通知?)

![[蓝桥杯2017初赛]九宫幻方-数论+next_permutation枚举](http://pic.xiahunao.cn/[蓝桥杯2017初赛]九宫幻方-数论+next_permutation枚举)
