大家好,我是若川。持续组织了6个月源码共读活动,感兴趣的可以点此加我微信 ruochuan12 参与,每周大家一起学习200行左右的源码,共同进步。同时极力推荐订阅我写的《学习源码整体架构系列》 包含20余篇源码文章。历史面试系列
本文来自读者@漫思维 投稿授权
原文链接:https://juejin.cn/post/7072677637117706270
1前言
以下我会列举出我业务中遇到的问题难点及相对应的解决方法,解释简繁体插件怎么诞生的整个过程
2背景
目前开发工作有大量的营销活动需要编写,特点是小而多,同时现阶段项目需要做大陆与港台两个版本
3现阶段实现的方案
先做完大陆版本,最后再复刻一份代码, 改成港台版本
将项目中的汉字、价格、登录方式进行替换。
4存在的问题
首先复制来复制去就不是一个很好的方案,容易复制出问题,其次两个版本都是需要同一个时间点上线,复刻代码的代码的时机存在问题,如果复刻的过早,如果提测阶段大陆版本有bug, 那么就需要修改两份bug, 如果复刻的过晚那么会存在港台版本测试时间不足,也易导致问题发生。
简繁体转换,都是将简体手动复制到谷歌翻译网页端中翻译好,再手动替换,繁琐且工程量大, 登录方式需要单独的复制一份。
5两个版本之间存在以下不同点
登录方式的不同, 大陆主要是用账号密码登录,而港台使用谷歌、脸书、苹果登录
价格、单位不同,¥ 与 NT$
汉字的形式不同,中文简体与中文繁体
核心问题在于复刻出一份项目存在的工作量与潜在风险较大,所以需要将两个项目合成一个项目,怎么解决?
6解决方案
1. 将两个项目合并成一个项目
如果需要将两个项目合成一个项目,并解决以上分析出来的不同点,那么显而易见,需要有个一标识去区分,那么使用环境变量解决这个问题是非常合适的,以vue项目举例, 可以编写对应的环境变量配置。
大陆版本生产环境:.env
VUE_APP_ENV=prod
VUE_APP_PUBLIC_PATH=/mainland大陆版本开发环境:.env
VUE_APP_ENV=dev
VUE_APP_PUBLIC_PATH=/mainland港台版本开发环境:.env.ht
VUE_APP_ENV=ht
VUE_APP_PUBLIC_PATH=/ht
NODE_ENV=productionpackage.json
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"build:ht": "vue-cli-service build --mode ht",可以看到这里使用了一个自定义变量 VUE_APP_ENV, 在项目代码中就可以使用 process.env.VUE_APP_ENV 去做区分当前是大陆还是港台了,同时为什么不使用NODE_ENV作为变量,因为该变量往往会有其他用途,如当NODE_ENV设置为production 时,打包时会做一些如压缩等优化操作。
注: 港台版本不做测试环境的区分,因为往往大陆版的逻辑没有问题,港台版的就没有问题,所以只需要基于大陆版开发,港台版只需要最后打包一次即可 **(测试环境可选,只需要多添加一个配置即可)**。
其他注意点: process.env.VUE_APP_ENV通常只能在node环境下才能访问的,但是vue-cli创建项目会自动将.env里的变量注入到运行时环境中,也就是使用一个全局变量存起来,通常是使用webpack的define-plugin插件实现的。
解决了环境变量的问题,接下来的工作就比较好进行了。
2. 解决登录方式的不同
将两套登录封装成两个不同的组件,因为登录往往涉及到一些全局状态,项目一般都会使用vuex等全局状态管理工具,所以默认使用vuex储存状态,把整个包含登录逻辑的代码制作成一个项目的基础模板,使用自定义脚手架拉取即可,同时注意使用vuex时,为登录相关的状态,放置到一个module下,这样基于该模板创建项目后, 每个项目的其它状态单独再写module即可,避免修改登录的module。
自定义脚手架:交互式创建项目,输入一些选项,如项目名称,项目描述之类的,再从gitlab等远程仓库拉取已经写好的模板,将模板中的一些特定变量,使用模板引擎将模板中的项目名称等替换,最终产生一个新的项目。(脚手架还有其他用途,这里只描述使用它创建一个简单的项目)
没有脚手架那就只能使用
git clone下来后再修改项目名称之类的东西,会增加一点额外的工作,但不影响不大。
封装的部分逻辑:
比如大陆的登录组件叫做 mainlandLogin, 港台的登录组件叫 htLogin,再写一个 login组件将他们整合,通过环境变量进行区分引入不同的组件,使用component动态加载对应的登录组件如下:
login.vue:
<component :is="currentLogin" @sure="sure" cancel="cancel"></component>data:{return {currentLogin: process.env.VUE_APP_ENV === 'ht' ? 'mainlandLogin' : 'htLogin'}
},
components: {mainlandLogin: () => import("./components/mainlandLogin.vue"),htLogin: () => import("./components/htLogin.vue"),
},
method:{sure(){this.$emit('sure')},cancel(){this.$emit('cancel')}
}注意: 引入组件的方式使用动态加载,打包时会将两个组件打包成两个单独的chunk, 因为大陆版本与港台版本只会用到一种登录,另一个用不到的不需要引入
经过如上操作将登录的组件封装好以后使用起来就很简单了
<login @sure="sure" cancel="cancel"></login>3. 解决价格不一致问题
与登录一样,根据环境变量区分即可,在原来大陆版本的商品JSON中加入一个字段即可如htPrice
const commodityList = [{id: 1name: "xxx",count:1,price:1,htPrice: 2}
]遍历的时候还是根据process.env.VUE_APP_ENV === 'ht'进行显示对应价格与单位
{{ isHt ? `${commodity.htPrice} NT$` : `${commodity.price} ¥` }}data() {return {isHt: process.env.VUE_APP_ENV === 'ht'}
}4. 简繁体转换
解决了两个项目合并成一个项目和登录、价格、单位不一致的问题,最后只剩下简体转繁体,也是最难解决的一部分,经过了多次技术调研没有找到合适的方案,最后只能自己写一套。
1. 使用i18n, 维护两套语言文件
优点: 国际化使用的最多的一个库,不用改动代码中的文字,使用变量替换,只需维护两套语言文件,改动点集中在一个文件中
缺点: 使用变量进行替换一定程度上增加了代码的复杂性,无法省去手动复制简体去翻译在额外写入特定的语言文件这一过程,对于这个场景不是一个最好的方案
2. 采用:language-tw-loader
优点: 看似 可以自动化将简体转换成繁体,方便快捷
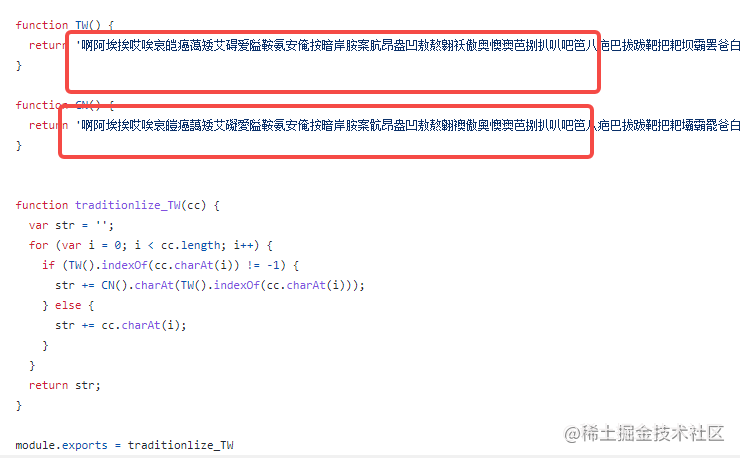
缺点: 在使用时发现一个致命的缺点, 无法准确替换,原因: 不同的词组,同一个词可能对应多个字形,如:联系 -> 聯繫, 系鞋带 -> 系鞋带。
基本原理: 列举常用的中文简体与繁体,一一对应,逐一替换, 如下图所示:
3. 采用 v-google-translate优点: 运行时采用谷歌翻译,自动将网页的简体翻译成繁体
缺点: 因为是运行时转义,所以页面始终会先展示简体,过一段时间再显示繁体
综上所述: 现有的一些方案存在以下几个问题
需要维护额外的语言文件,使用变量替换文字
编译时转换无法正确转换,运行时转换有延时
为了解决以上问题:
1. 无需写多套语言文件,正常开发使用中文进行编写即可
需要一个翻译的API,且翻译要准确,经测试简繁体转换谷歌翻译是最准确的。
2. 在编译时转换
编写打包工具的plugin,这里主要以webpack为打包工具,所以需要编写一个webpack的plugin。
翻译API
需要一个免费、准确、且不易挂的翻译服务,但是谷歌翻译API是需要付费的,有钱付费的很方便就能享受这个服务,但是为了一个简体转繁体产生额外的支出,不太现实。
开源项目中有很多的免费谷歌API, 但都是去尝试模拟生成其加密token,进行请求,服务很容易挂掉,所以很多 直接变成了没有。
但是!!!你要记得,谷歌翻译是提供免费的网页版的!
所以只需要打开一个浏览器,填入需要翻译的文字,获取翻译后的文字即可,只不过需要程序自动帮我们打开一个浏览器,你没想错,已经有很成熟的方案puppeteer 就是干这件事情的。
所以最终采用: 基于puppeteer的访问谷歌https://translate.google.cn 获得翻译结果,比其他方案都要稳定。
同时已有大佬写了一个基于puppeteer的转换服务 translateer,感兴趣的可以看看其源码,也不复杂。
但是注意,基于 translateer 启动API服务, 存在几个可以优化的点:
先看下为什么需要优化, 首先我们得要知道谷歌翻译网页端最大支持多少字符,测试得知如下最大支持一页最大支持 5000字符,超过的部分可以翻页。
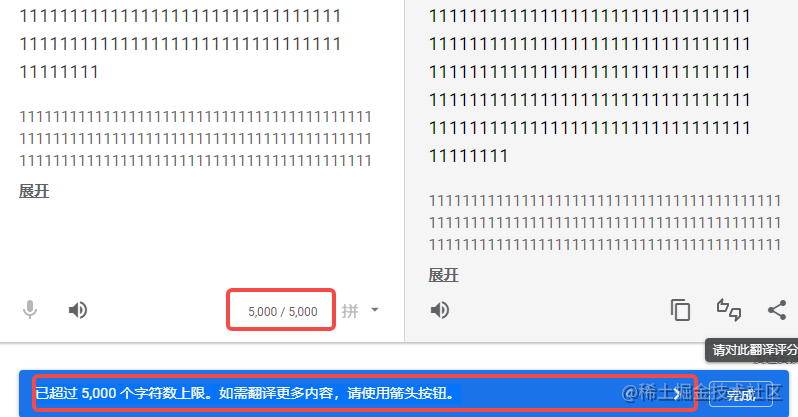 再以上左侧输入框内输入源文本,该网页会发送一个
再以上左侧输入框内输入源文本,该网页会发送一个post请求,一小会延迟右侧出现翻译后的内容,同时注意导航栏上的链接会变成如下形式:
https://translate.google.cn/?sl=zh-CN&tl=zh-TW&text=哈哈哈&op=translate上面几个参数分别的含义
sl: 源语言; tl: 目标语言; text: 翻译的文本; op: translate (翻译)如果直接使用以上链接进行请求,经过测试,将text值替换为'1'.repeat(16346), 16346 个字符时 (该数值不包括url上其它字符,算上其它字符,那么总的url长度是16411) ,谷歌接口会返回400错误。
值得提的是: 看了很多的文章都说chrome的get请求最大字符长度限制是2048或8182,但是都不太准确,上述测试就可以证明,总长度少于16411 谷歌翻译依旧可以正常访问,超过以后还是由谷歌翻译对应的后台服务器抛出的400 错误。
参考了GET请求的长度限制, 以下几点是可以知道的:
1、首先即使有长度限制,也是限制的是整个URI长度,而不仅仅是你的参数值数据长度。
2、HTTP协议从未规定GET/POST的请求长度限制是多少
3、所谓的请求长度限制是由浏览器和web服务器决定和设置的,浏览器和web服务器的设定均不一样
所以浏览器到底限制的是多少字符呢,暂时还没有找到正确答案,有知道的大佬可以帮忙解释一下
测试所用的谷歌浏览器版本: 98.0.4758.102(正式版本)(64 位)
分析了以上基本的限制,接下来看看translateer 的实现:
translateer 服务启动时创建一个 PagePool页面池,开启5个tab页面并且都跳转至https://translate.google.cn/, 以下为删减后的部分代码:
export default class PagePool {private _pages: Page[] = [];private _pagesInUse: Page[] = [];constructor(private browser: Browser, private pageCount: number = 5) {pagePool = this;}public async init() {this._pages = await Promise.all([...Array(this.pageCount)].map(() =>this.browser.newPage().then(async (page) => {await page.goto("https://translate.google.cn/", {waitUntil: "networkidle2",});return page;})));}
}然后使用fastify启动一个Node服务器,对外提供一个get请求API。以下为删减后的部分代码:
fastify.get("/",async (request, reply) => {const { text, from = "auto", to = "zh-CN", lite = false } = request.query;const page = pagePool.getPage();await page.evaluate(([from, to, text]) => {location.href = `?sl=${from}&tl=${to}&text=${encodeURIComponent(text)}`;},[from, to, text]);// translating...await page.waitForSelector(`span[lang=${to}]`);// get translated textlet result = await page.evaluate((to) =>(document.querySelectorAll(`span[lang=${to}]`)[0] as HTMLElement).innerText,to);
}传入sl: 源语言; tl: 目标语言; text: 翻译的文本 这几个参数,location.href 跳转至
?sl=${from}&tl=${to}&text=${encodeURIComponent(text)} 从而获得右侧输入框的返回结果。
分析了其基本的实现原理,接下来分析其中存在的坑点。
location.href 是个get请求,经过上面的分析暂时不知道浏览器get请求的字符长度限制,但是已经知道谷歌后台服务的对请求长度的限制为16411, 再粗略减去411个字符作为url的其他字符长度, 那么每次的翻译文本最大支持长度就为16000个字符。
而如上代码对text进行encodeURIComponent 编码 (get请求默认也会对中文及其它特殊字符进行编码)
需要注意的是中文一个字符编码后为9个字符 联 => %E8%81%94, 那么16000 / 9 约等于 1777个汉字
阶段总结:
由于谷歌翻译网页版的一些限制,直接使用get请求,一次最大支持翻译1777个汉字, 而在输入框内模拟输入汉字无字符长度限制,一页最大支持5000 字符,超出的部分可进行翻页。
需要达到的效果是一次翻译最少要能翻译5000个字符,尽量少请求次数,能减少翻译的时间,进而加快插件编译的速度,所以需要开始改进 translateer:
使用
fastify创建一个新的post请求API
export const post = ((fastify, opts, done) => {fastify.post('/',async (request, reply) => {...more...});done();
});跳转时只添加参数
sl源语言与tl目标语言不加text参数
await page.evaluate(([from, to]) => {location.href = `?sl=${from}&tl=${to}`;},[from, to]);选中谷歌翻译页面左侧的文本输入框,并将
需要翻译的文本赋值给输入框,并且需要使用page.type键入一个空字符,触发一次文本框的input事件,网页才会执行翻译。
await page.waitForSelector(`span[lang=${from}] textarea`);const fromEle = await page.$(`span[lang=${from}] textarea`);await page.evaluate((el, text) => {el.value= text},fromEle, text)// 模拟一次输入触发input事件,使得谷歌翻译可以翻译await page.type(`span[lang=${from}] textarea`, ' ');// translating...await page.waitForSelector(`span[lang=${to}]`);// get translated textconst result = await page.evaluate((to) =>(document.querySelectorAll(`span[lang=${to}]`)[0] as HTMLElement).innerText,to);这里有个坑点,就是 page.type 是模拟用户输入所以他会一个字一个字的输入,一开始的时候我使用它去给文本输入框赋值,文本过长时,输入的时间巨长,当时不知道怎么处理,为此我还专门提了个issue, 被指导后才改写成现在的写法: issues
总结:
前面提到,超过5000字符可以进行翻页,这里没有进行翻译处理,目前限制就每次请求翻译5000个字符已经够用,超过5000再请求一次翻译接口 (后续可处理一下翻页,不管多长的字符都一次翻译完毕, 不过还需要进一步对比两者的所用时间长短)
最后以上修改过的代码github地址: Translateer
translate-language-webpack-plugin
解决了翻译API的问题,剩下的事情就只剩将代码中的中文简体转换成繁体了,由于打包工具使用的webpack, 所以编写webpack plugin 进行读取中文并替换, 同时需要支持webpack5.0与webpack4.0版本,以下以5.0版本为例:
首先理一下该插件的思路
编写webpack插件
读取代码中所有的中文
请求翻译API, 获得翻译后的结果
将翻译后的结果写入至代码中
额外的功能:将每次读取的源文本与目标文本输出至日志中, 特别是在翻译返回的文本长度与源文本长度不一致时用于对照。
接下来一步步实现上述功能
1. 第一步需要编写一个插件,怎么写?这是个问题
4.0版本 和 5.0版本 的钩子是不一样的,而且很多,这里不会介绍webpack plugin中每个钩子的含义,不是两句话能说的清楚的, 网上有很多介绍的如揭秘webpack插件工作流程和原理,要想快速的写一个插件,那么最快的方式就是参考现有的成熟的插件,我在编写的时候就是直接参照的html-webpack-plugin, 4.0版本与5.0版本都是参照其对应版本写的。
tips: 看开源项目的源码的意义就在于此,可以学到很多的成熟的解决方案,可以稍微少踩一点坑, 所以最基本也需要学会如何找入口文件,如何调试代码。
部分代码如下,参考如下注释:
const { sources, Compilation } = require('webpack');
// 日志输出文件
const TRANSFROMSOURCETARGET = 'transform-source-target.txt';
// 谷歌翻译一次最大支持字符
const googleMaxCharLimit = 5000;
// 插件名称
const pluginName = 'TransformLanguageWebpackPlugin';class TransformLanguageWebpackPlugin {constructor(options = {}) {// 默认的一些参数const defaultOptions = { translateApiUrl: '', from: 'zh-CN', to: 'zh-TW', separator: '-', regex: /[\u4e00-\u9fa5]/g, outputTxt: false, limit: googleMaxCharLimit,};// translateApiUrl 翻译API必须传if (!options.translateApiUrl)throw new ReferenceError('The translateApiUrl parameter is required');// 将传入的参数与默认参数合并this.options = { ...defaultOptions, ...options };}// 添加apply方法,供webpack调用apply(compiler) {const {separator, translateApiUrl, from, to, regex, outputTxt, limit} = this.options;// 监听compiler 的thisCompilation 钩子compiler.hooks.thisCompilation.tap(pluginName, (compilation) => {// 监听compilation 的processAssets 钩子compilation.hooks.processAssets.tapAsync({name: pluginName,// stage 代表资源处理的阶段, PROCESS_ASSETS_STAGE_ANALYSE:analyze the existing assets.stage: Compilation.PROCESS_ASSETS_STAGE_ANALYSE,},// assets 代表所有chunk文件`路径及内容async (assets, callback) => {// TODO:在此处填充要实现的功能})})}
}以上为该插件的基本结构, webpack5.0中processAssets钩子用于处理文件,我们主要看一下 Compilation.PROCESS_ASSETS_STAGE_ANALYSE阶段assets 中有什么. 以提供的github仓库中提供的例子为例
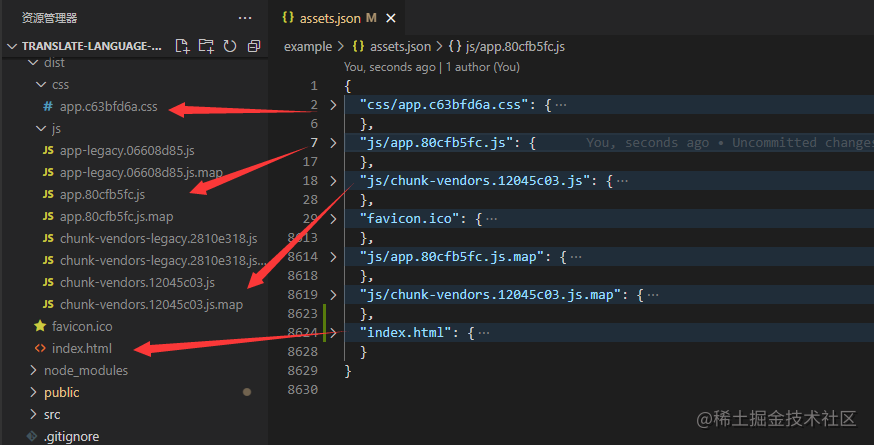 可以看到
可以看到assets就是最终会输出的文件,根据需要做的事选择不同的stage, 这里选择PROCESS_ASSETS_STAGE_ANALYSE的原因是,需要处理index.htm中的中文,所以需要选择一个非常靠后的钩子,其他钩子参考 (相关文档)
2. 读取代码中所有的中文
首先需要写一个函数,用于匹配相邻的中文字符,如,源码中含有<p>失联</p><div>系鞋带</div>, 返回:['失联', '系鞋带']。将返回的字符数组,以分隔符分隔,如['失联', '系鞋带'] => 失联'-'系鞋带' , 分隔的原因:如中文简体 => 中文繁体(存在多形字):失联系鞋带 => 失聯繫鞋帶, 而正确的结果应该是 失联系鞋带, 失联是一个词组,系鞋带是一个词组,转换后不会有变化的, 而联系在一起的时候就会变成 聯繫
/*** @description 返回中文词组数组, 如: <p>你好</p><div>世界</div>, 返回: ['你好', '世界']* @param {*} content 打包后的bundle文件内容* @returns*/
function getLanguageList(content, regex) {let index = 0,termList = [],term = '',list; // 遍历获取到的中文数组while ((list = regex.exec(content))) {if (list.index !== index + 1 && term) {termList.push(term);term = '';}term += list[0];index = list.index;}if (term !== '') {termList.push(term);}return termList;
}在以上代码TODO: 的位置继续编写, 获取所有chunk中的中文并保存至chunkAllList数组中
let chunkAllList = [];
// 先将所有的chunk中的`指定字符词组`存起来
for (const [pathname, source] of Object.entries(assets)) {// 只读取js与html文件中的中文,其他的文件不需要if (!(pathname.endsWith('js') || pathname.endsWith('.html'))) {continue;}// 获取当前chunk的源代码字符串let chunkSourceCode = source.source();// 获取chunk中所有的中文。const chunkSourceLanguageList = getLanguageList(chunkSourceCode, regex);// 如果小于0,说明当前文件中没有 `指定字符词组`,不需要替换if (chunkSourceLanguageList.length <= 0) continue;chunkAllList.push({// 原文本数组chunkSourceLanguageList,// separator为分割符默认为: -chunkSourceLanguageStr: chunkSourceLanguageList.join(separator),// chunk原代码chunkSourceCode,// chunk的输出路径pathname,});
}3. 请求翻译API, 获得翻译后的结果
因为有些chunk中中文是很少的, 比如一个chunk中只有2个字,另一个chunk中只有3个字,那么就没必要请求两次翻译接口,为了减少请求次数,先将所有chunk中的中文合成一个字符串,并用_分隔开用于区分是属于那个chunk中的内容。
const chunkAllSourceLanguageStr = chunkAllList
.map((item) => item.chunkSourceLanguageStr).join(`_`);合成一个字符串以后,还需要进行切割,因为一次最大支持翻译5000个字符
// 合理的分割所有chunk中读取的字符,供谷歌API翻译,不能超过谷歌翻译的限制
const sourceList = this.getSourceList(chunkAllSourceLanguageStr, limit);getSourceList(sourceStr, limit) {let len = sourceStr.length;let index = 0;if (limit) {}const chunkSplitLimitList = [];while (len > 0) {let end = index + limit;const str = sourceStr.slice(index, end);chunkSplitLimitList.push(str);index = end;len = len - limit;}return chunkSplitLimitList;
}切割完成后,最后使用Promise.all去请求所有的接口,所有的翻译成功才能算成功
// 翻译
const tempTargetList = await Promise.all(sourceList.map(async (text) => {return await transform({translateApiUrl: translateApiUrl,text: text,from: from,to: to,});})
);4. 将翻译后的结果写入至代码中
得到了所有chunk中的中文简体翻译后的繁体,最后遍历chunk数组chunkAllList,将源代码中的
for (let i = 0; i < chunkAllList.length; i++) {const {chunkSourceLanguageStr,chunkSourceLanguageList,pathname,chunkSourceCode,} = chunkAllList[i];let sourceCode = chunkSourceCode;// 将简体转换为繁体targetList[i].split(separator).forEach((phrase, index) => {sourceCode = sourceCode.replace(chunkSourceLanguageList[index],phrase);});// if (outputTxt) {writeContent += this.writeFormat(pathname,chunkSourceLanguageStr,targetList[i]);}compilation.updateAsset(pathname, new sources.RawSource(sourceCode));
}以上代码为不完全代码,完整代码及插件使用方式请参考:translate-language-webpack-plugin
5. 输出对照文本
如下:主要是输出每个chunk中的中文用于对照,如果说页面没有其它动态的文字,且这些文字需要应用特殊的字体,也可以使用这些读取出来的字打包一个字体文件,比一整个字体文件小很多很多。
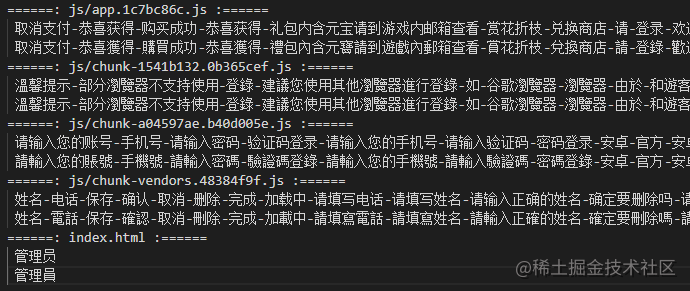
7总结
注意:会将页面上包括js中的中文全部替换,但是接口返回的文字是无法转换的,由后端返回对应繁体
至此一个完整的业务需求就已经优化的七七八八了,翻译插件理论上支持任意语言互转,但是由于翻译的语义不同,往往翻译出来的意思不是我们想要的,适用于简体繁体互转。

················· 若川简介 ·················
你好,我是若川,毕业于江西高校。现在是一名前端开发“工程师”。写有《学习源码整体架构系列》20余篇,在知乎、掘金收获超百万阅读。
从2014年起,每年都会写一篇年度总结,已经写了7篇,点击查看年度总结。
同时,最近组织了源码共读活动,帮助3000+前端人学会看源码。公众号愿景:帮助5年内前端人走向前列。

识别上方二维码加我微信、拉你进源码共读群
今日话题
略。分享、收藏、点赞、在看我的文章就是对我最大的支持~