Mysql高级
DQL查询语句
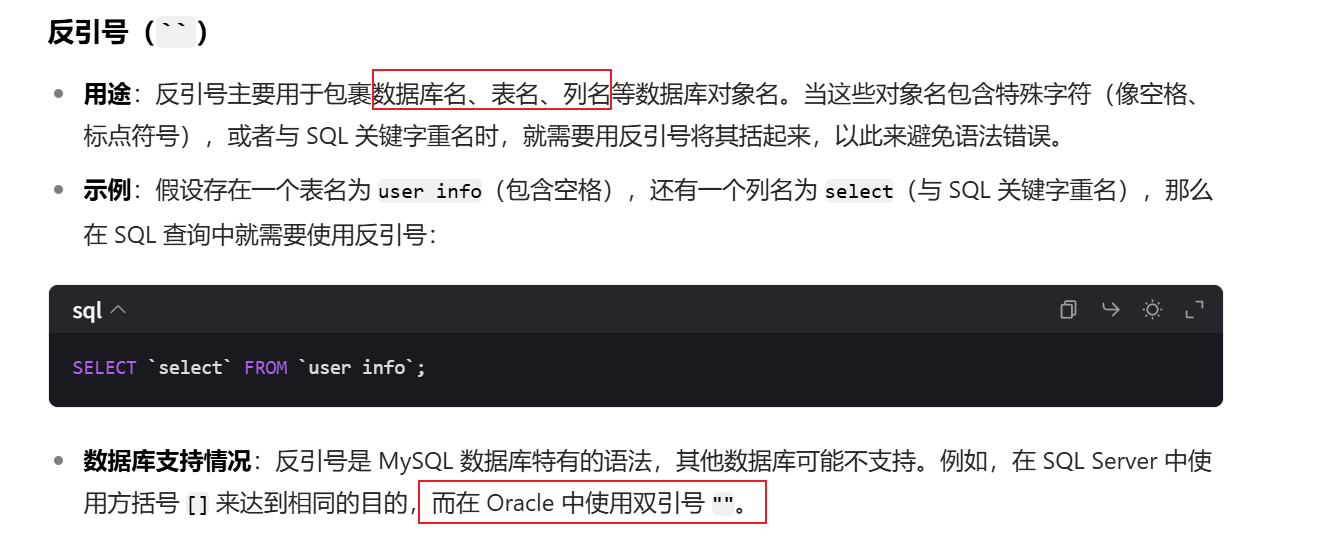
反引号
模糊查询避免%出现在开头,会造成索引失效
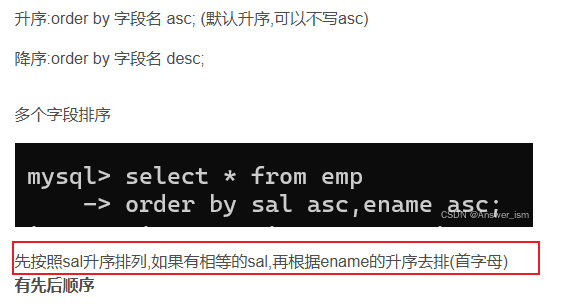
order by排序先后
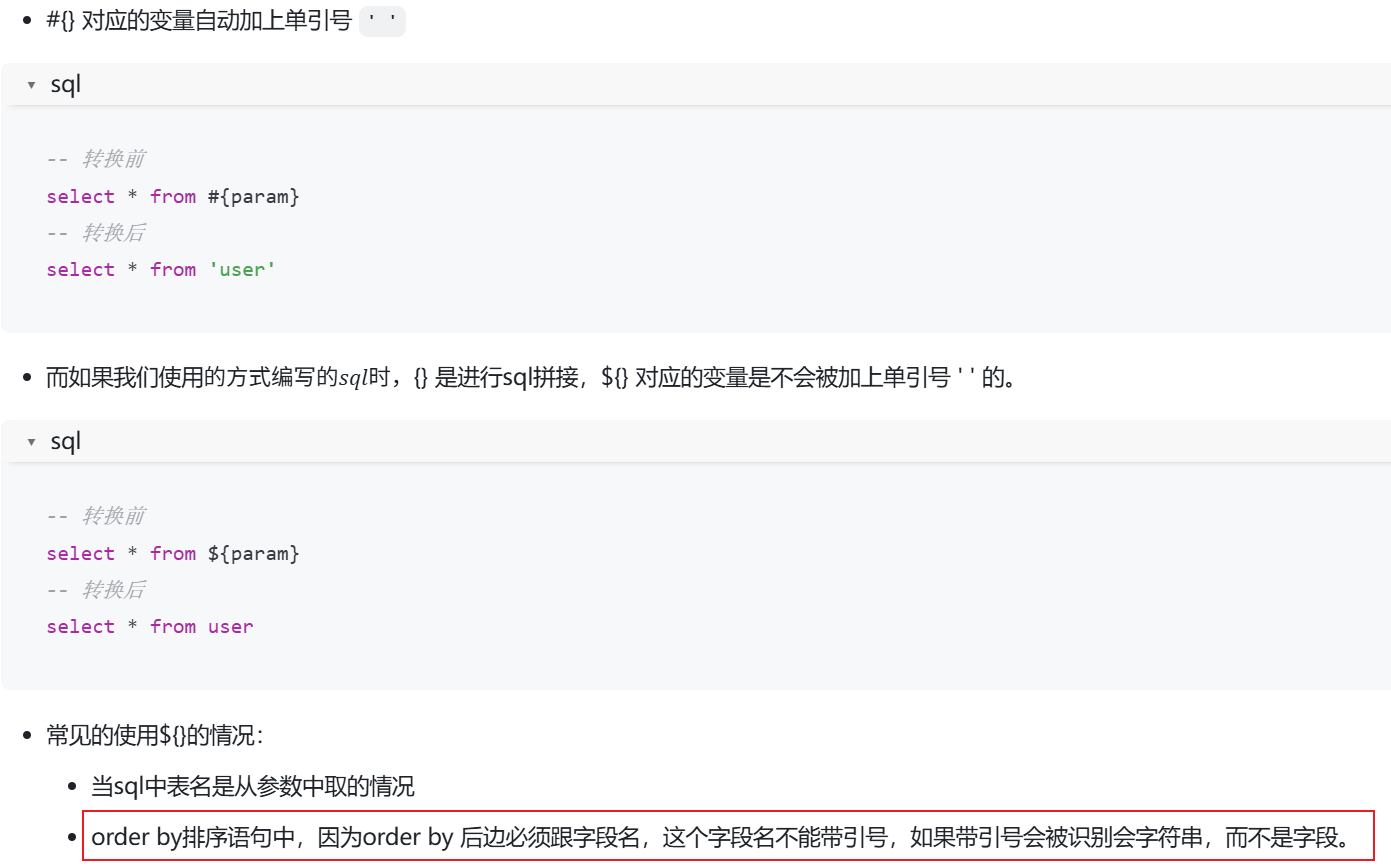
表名列名都需要用${},他们不能带’’
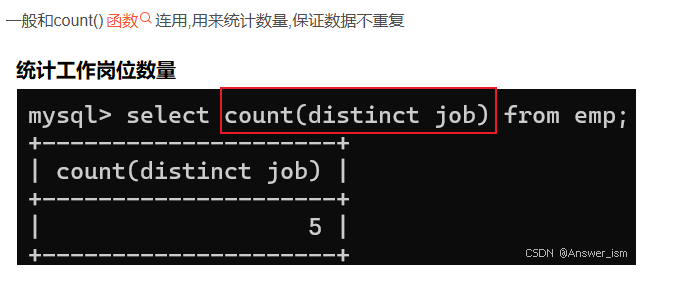
去重+统计数量

null的运算
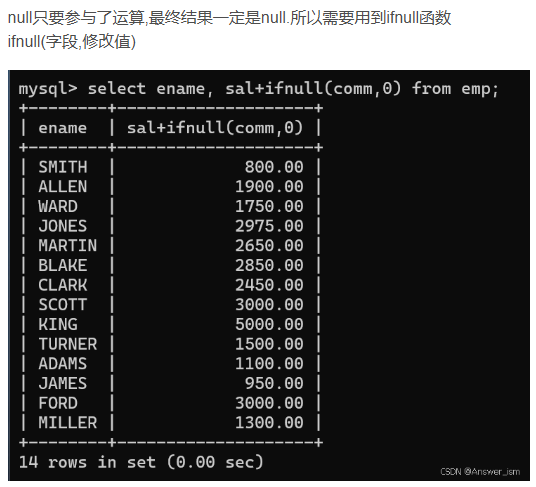
分组函数会自动忽略null,不用对null进行处理
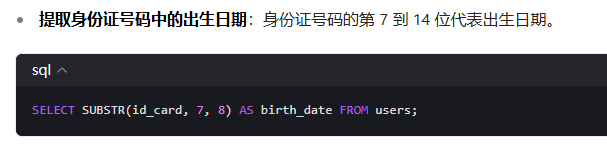
截取子串substr(字段,下标,截取长度)
下标从1开始
trim去重字段空格

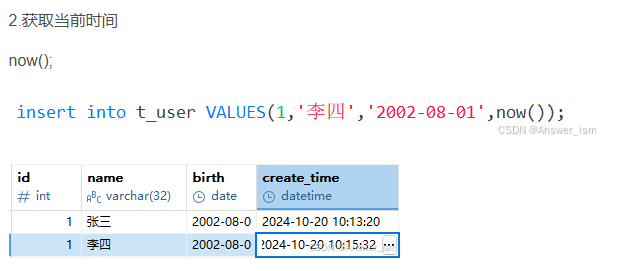
now()
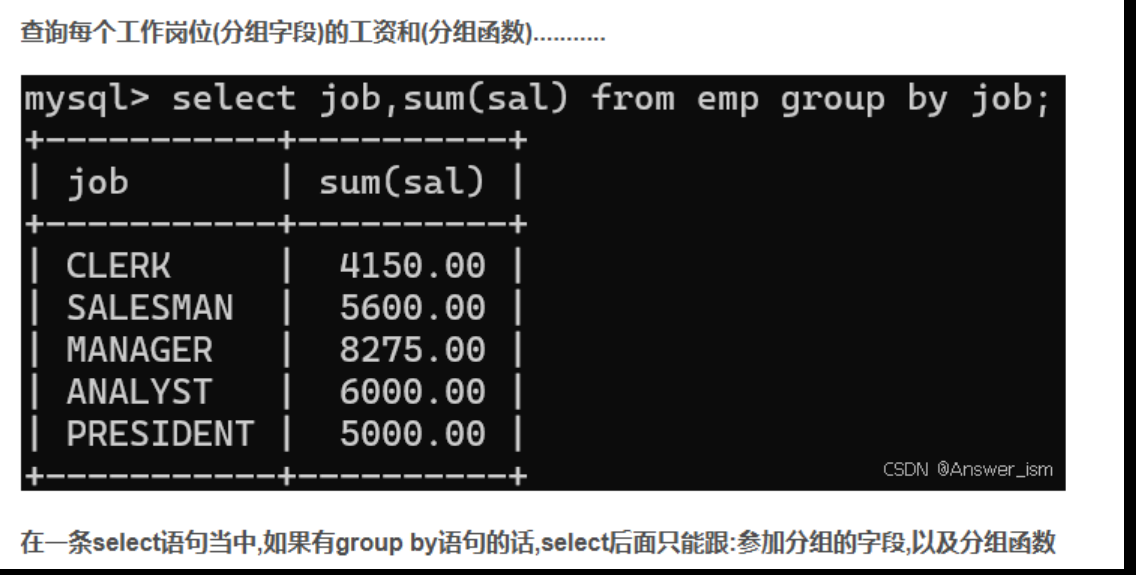
分组函数和分组查询group by


可以联合分组
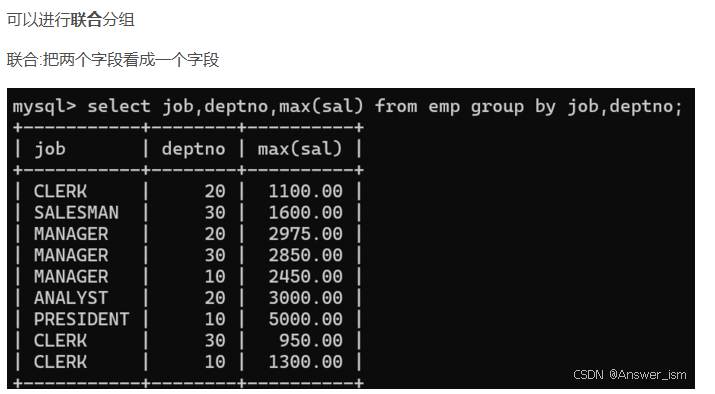
having和where区别和使用
having可以用分组函数,但是必须先group by 分组后再用having过滤
而where不可以用分组函数,必须先过滤后用group by 分组

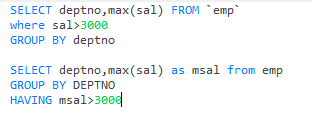
where效率比having高
因为执行顺序,先where后group by 后 having


连接查询
笛卡尔积,直接from 两张表,没有join和on条件(外键),直接n*n行查询,效率慢

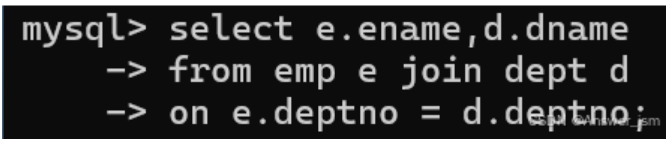
执行顺序先from后select
on条件相等,一般为外键

非等值查询
自连接
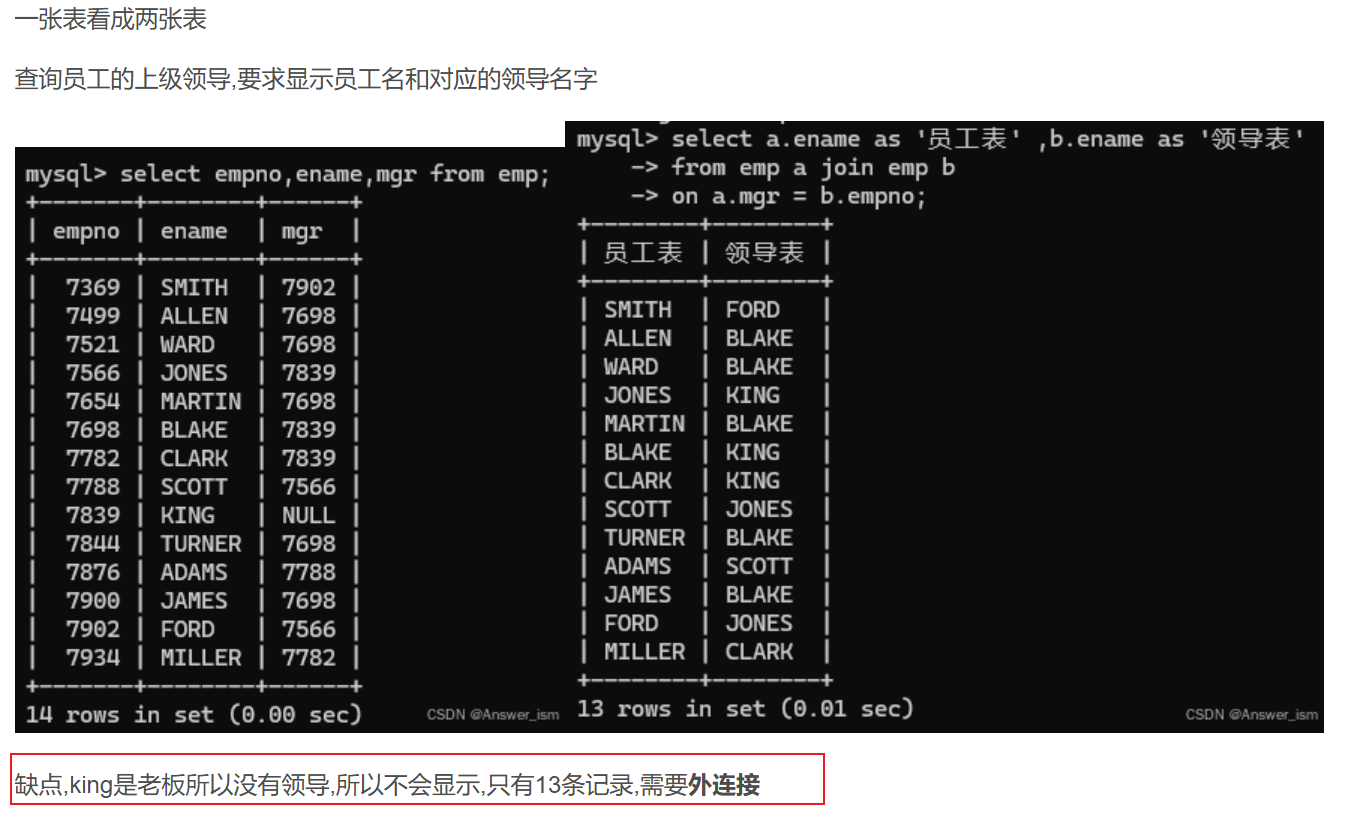
外连接
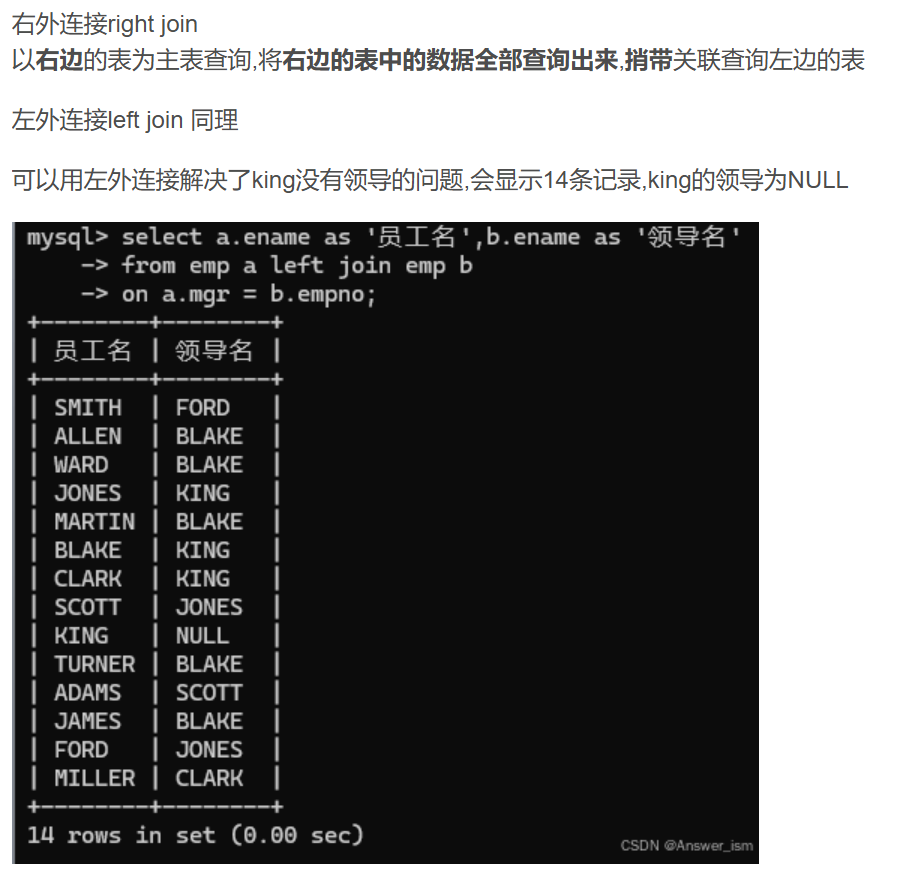
主次关系,需要把员工名全查出来,捎带查领导
多表连接

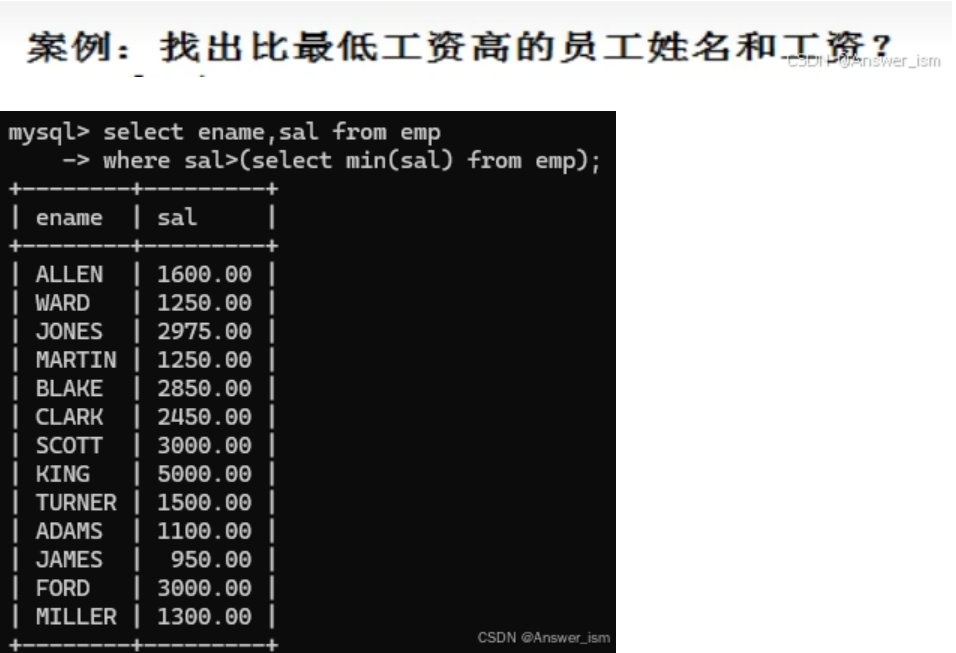
子查询(select嵌套)

where中子查询
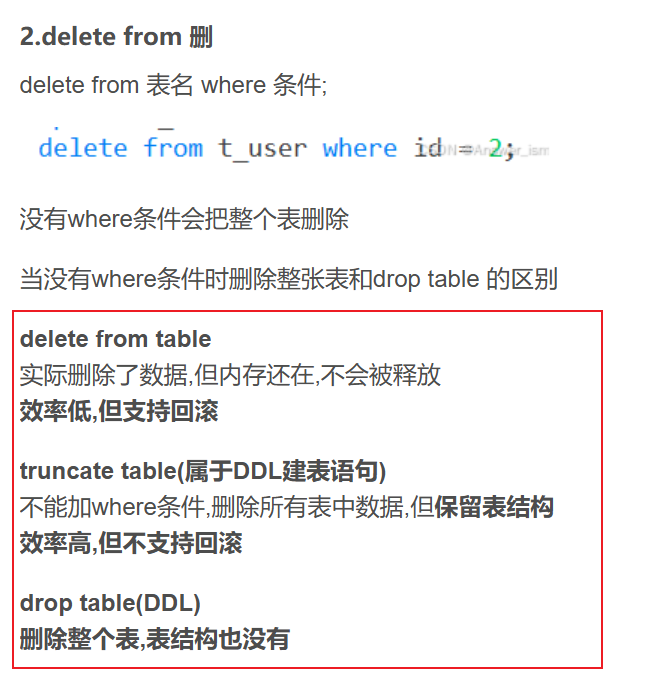
DML增删改语句


事务
事务的本质就是多条DML语句同时成功或者同时失败

每一句DML语句都会储存在日志文件中
提交事务commit或者回滚事务rollback,都会清空日志文件
commit提交到表中(硬盘中),rollback回滚到上次提交,都是结束事务的标志
事务的特性

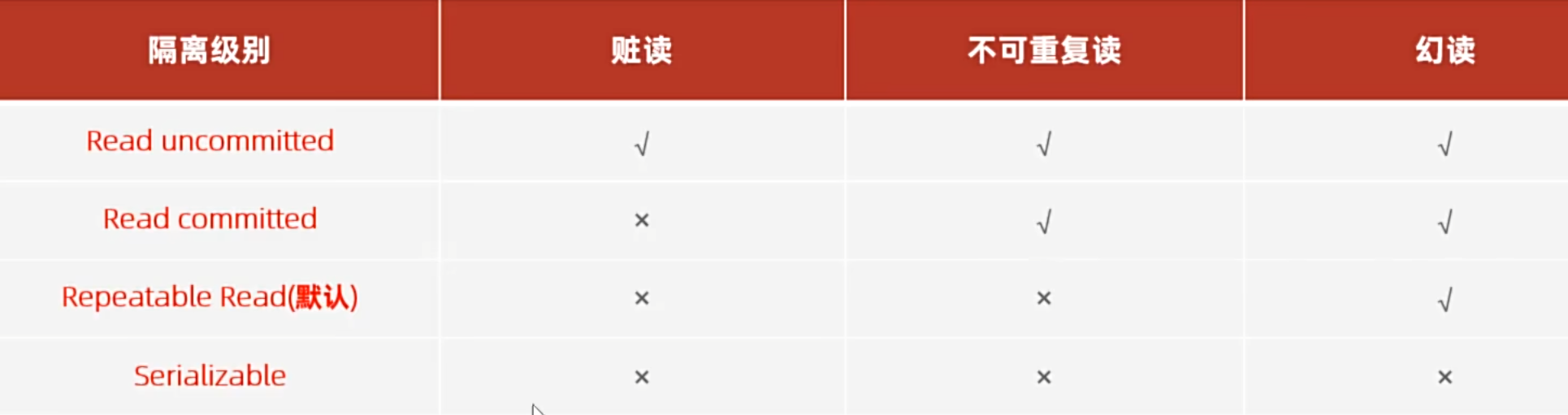
事务的隔离级别

重复:同一事务中,对相同数据进行多次读取
不可重复读

也就是事务先读取a,被别的事务修改了,再读取同一条记录,得到的结果不一样,所以不可重复读

每次读到的数据都一样,可重复读会给读取的数据加锁,其他事务无法修改这个数据
幻读就是第一次读取a,发现不存在,于是insert 这个a,发现insert失败,这时候就是另一个事务已经insert了这个a
但是第二次读取a,发现还是不存在,依旧insert失败,好像出现了幻觉

单线程不能并发
三范式

第二范式
修改前(联合主键,部分依赖)

修改后,三张表,关系表两个外键
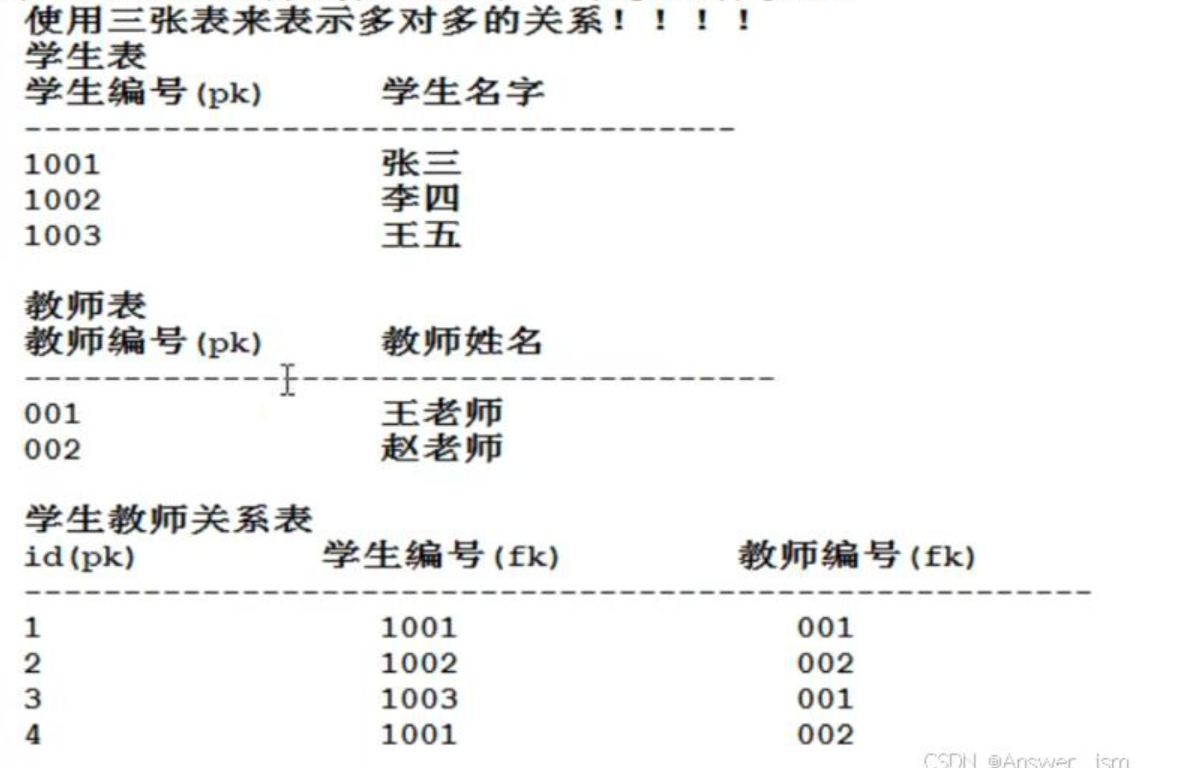
不能产生复合主键,部分依赖就是某个字段只依赖其中一个主键,和另一个主键没关系
多对多关系,需要设计三张表A表,B表,关系表
多对多,三张表,关系表两外键
第三范式
修改前(班级依赖01,01依赖1001)产生传递依赖
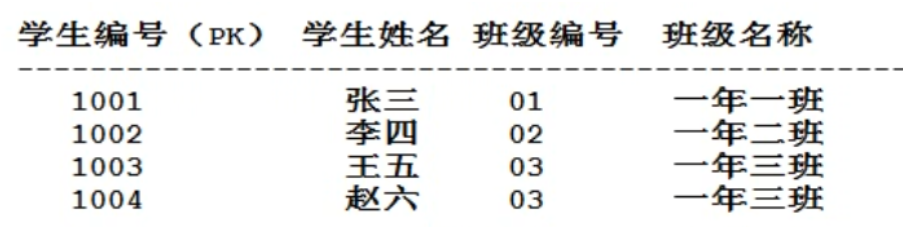
修改后(多的表加外键)
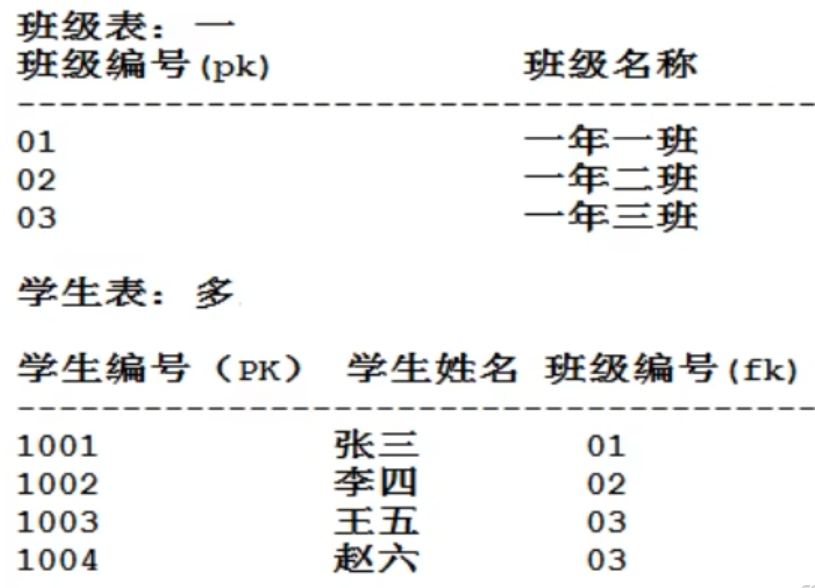
一对多,两张表,多的表加外键
大部分情况下,公司都不会遵循设计三范式
为了满足客户需求,速度要快的情况下,哥们不需要节省空间,有的是空间,不怕数据冗余
可以写在一张表内,就不会出现笛卡尔积现象
因为表与表连接次数越多,效率越慢
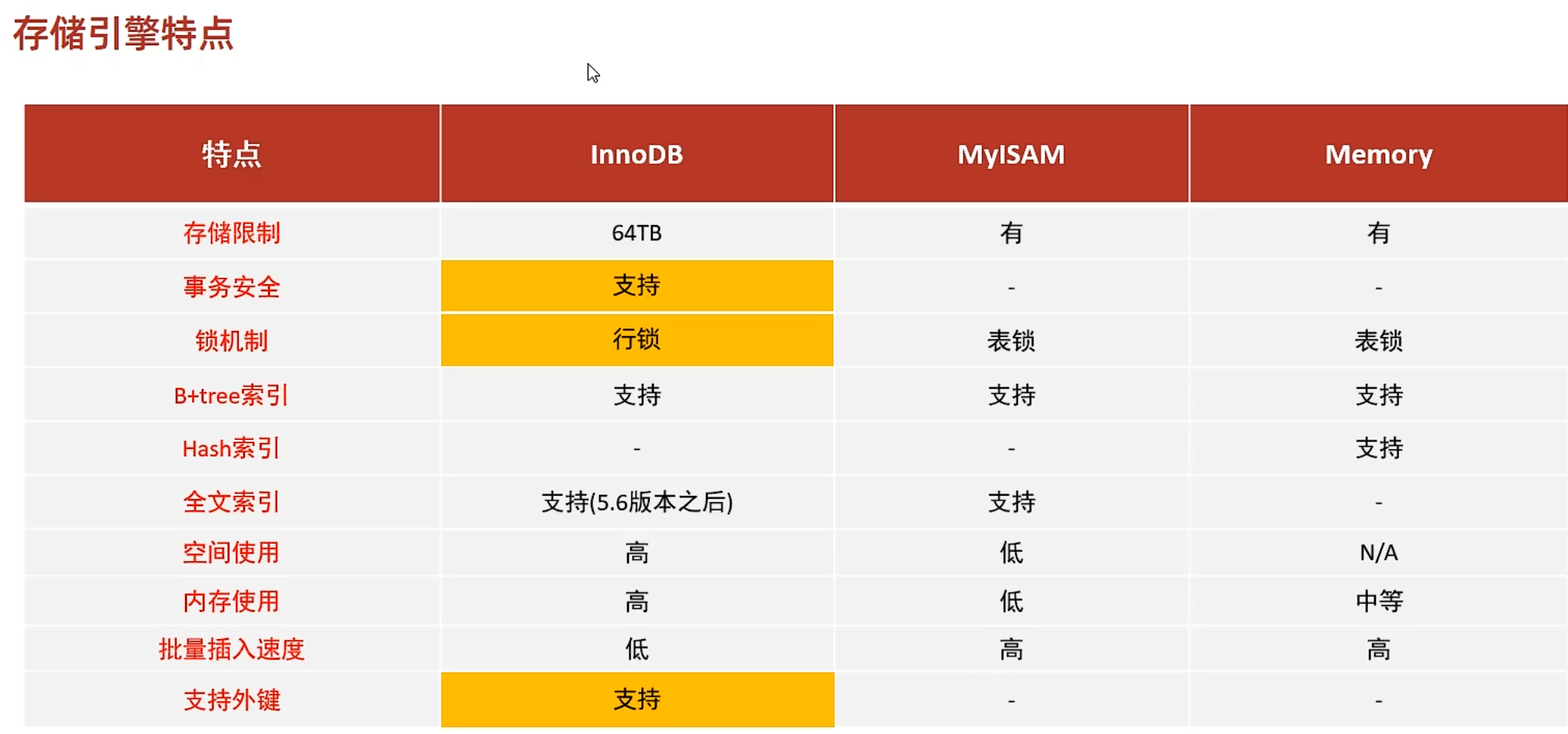
存储引擎
是以表为单位的,同一个数据库不同表可以有多种不同的存储引擎
mysql体系结构
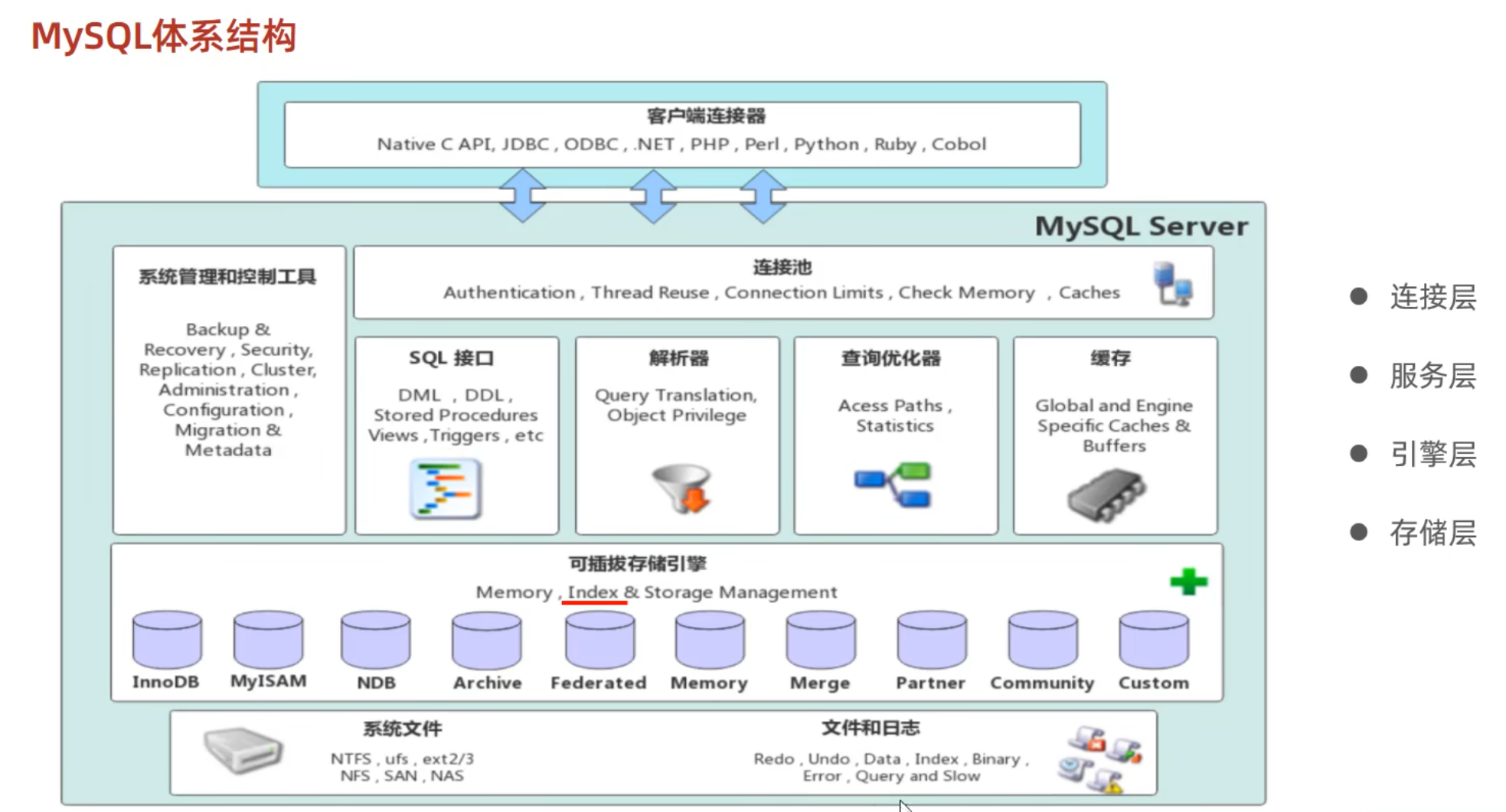
索引在引擎层
InnoDB存储引擎
支持事务,行级锁,外键

表结构,数据,索引全部都在表空间文件.ibd中
8.0之后表结构从.frm----->.sdi
逻辑存储结构
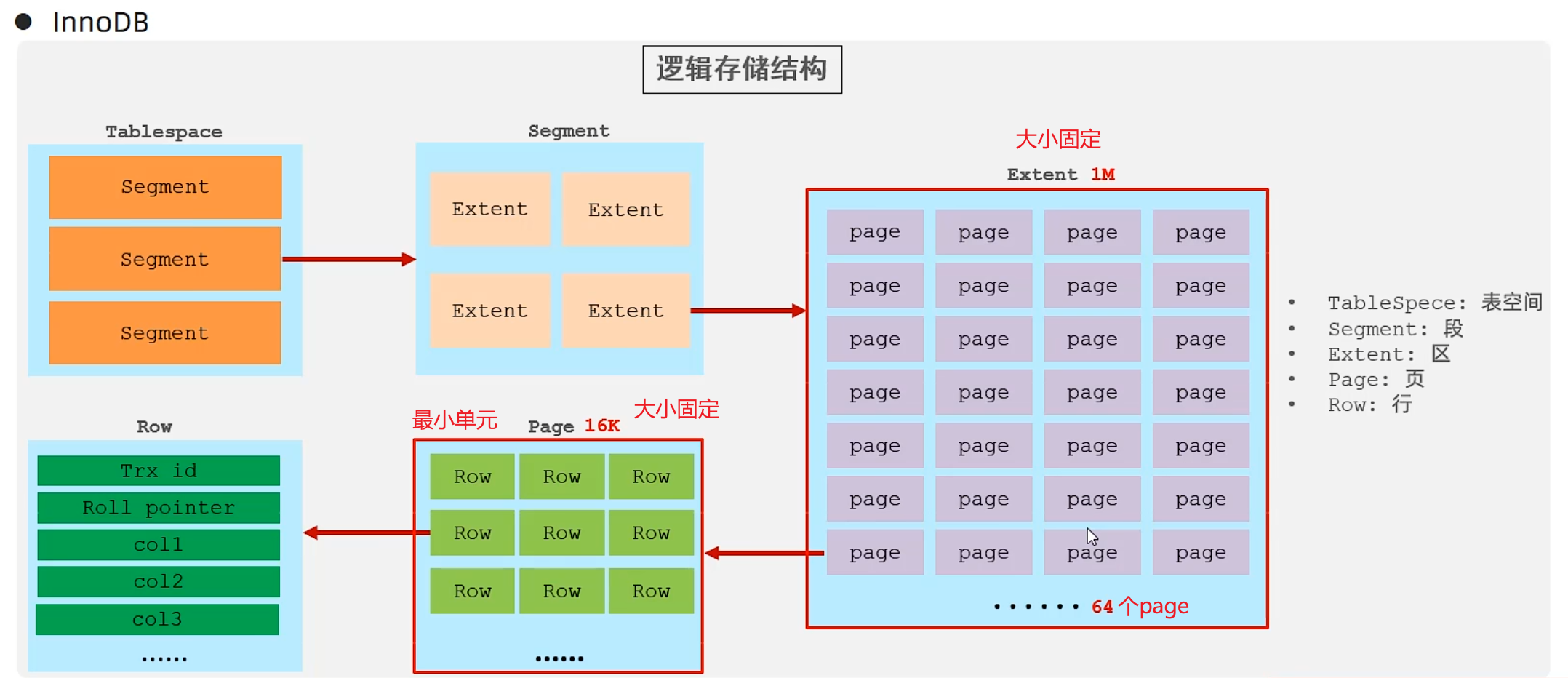
MyISAM(MongoDB)

Memory(Redis)

只有一个.sdi表结构数据在硬盘中,数据和索引都在内存中

索引
是一种优化后的B+ Tree数据结构
SQL优化都是根据索引来优化

索引在引擎层实现


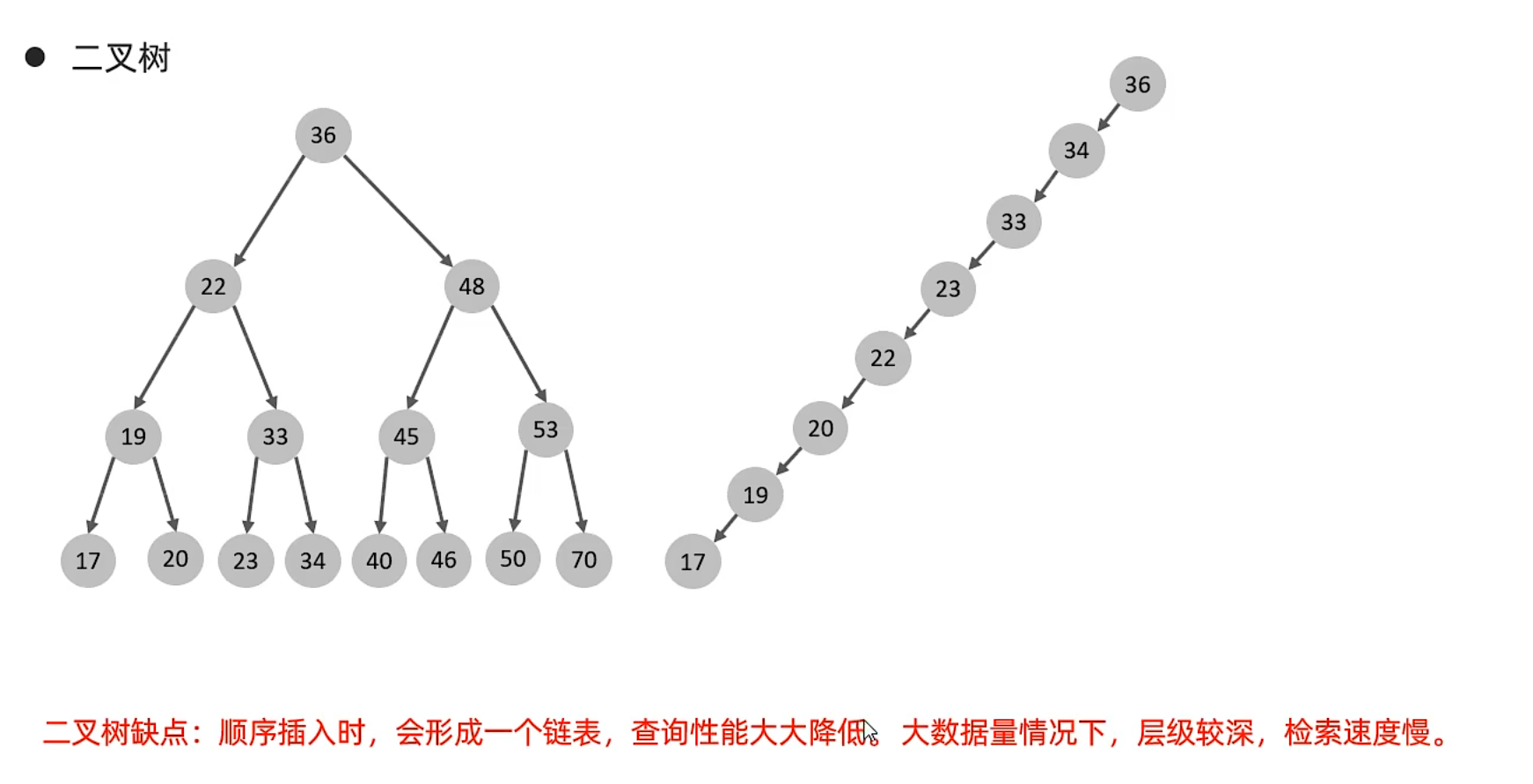
B树
二叉树
缺点:1.顺序插入形成单向链表
2.一个节点只能有两个子节点,数据量大时,层级较深,检索速度慢
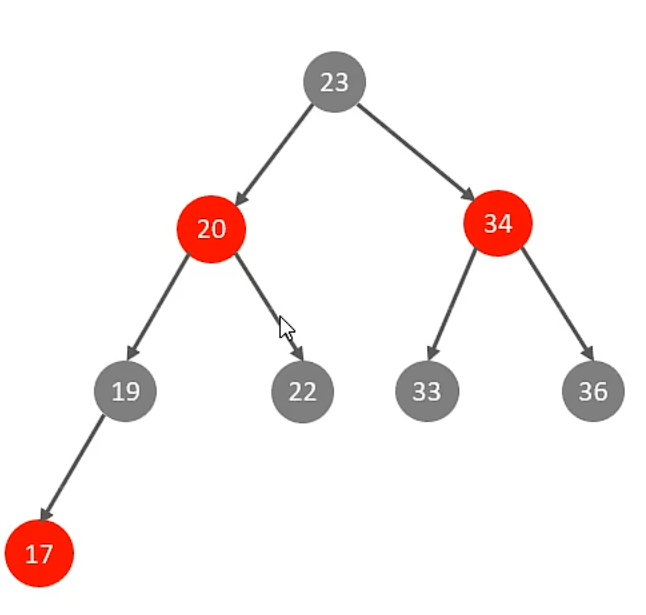
对于第一个问题,可以使用红黑树,自平衡,但是第二个问题不能解决
B树(多路平衡查找树)(一个节点下可以有多个子节点,解决第二个问题),同样也是自平衡的
度数:树的度数指的是一个节点的子节点个数
数据挂在key下面
B树插入规则
以5阶B树为例,最多四个key
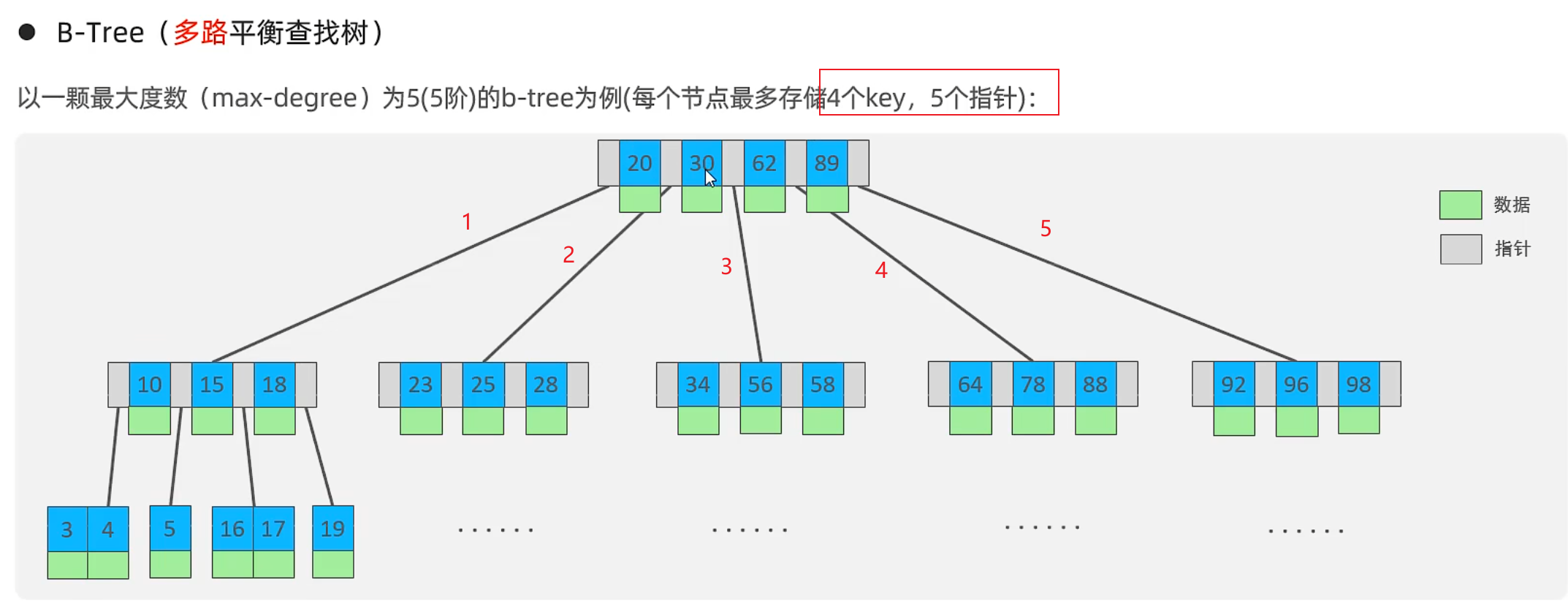
 插入1200
插入1200
插入后中间的数向上分裂(这里是345)
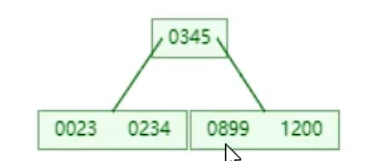
B+树
所有的元素都会出现在叶子节点中,上面的非叶子节点起到索引的作用,叶子节点是存放数据的
形成单向链表
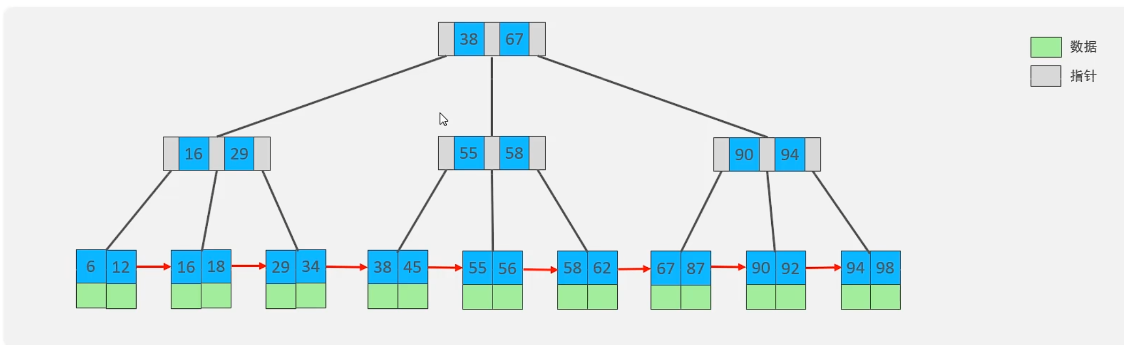
B+树插入规则
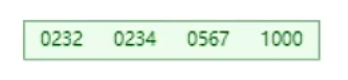 插入890
插入890
同样,567向上分裂,但是叶子节点也会有567,出现指针,形成单向链表
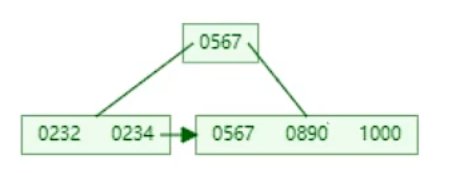

Mysql索引对B+树做了优化
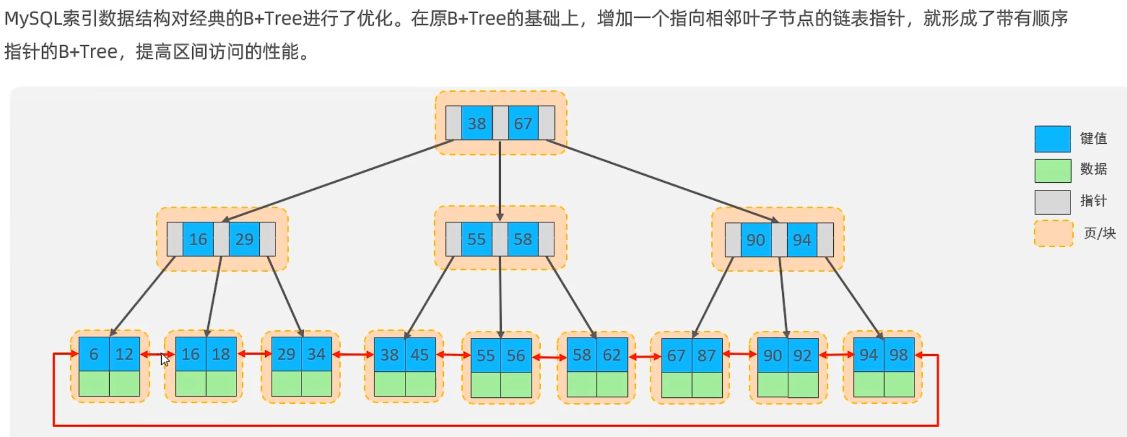
叶子节点是双向链表,每一个节点都是存储在页中的
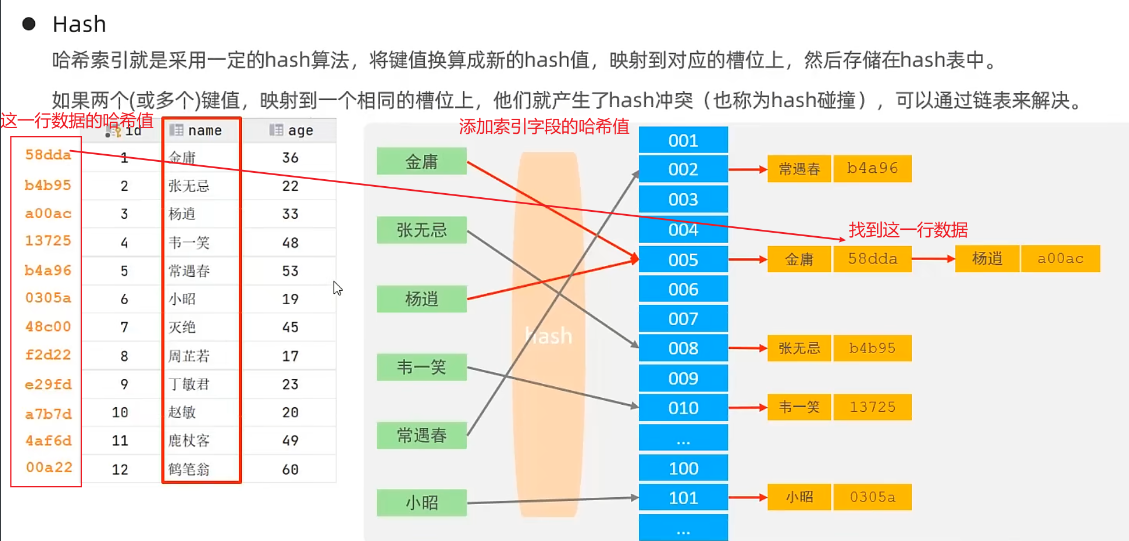
Hash索引数据结构
查询效率高(不发生哈希冲突的情况)
不支持范围查询和排序

为什么InnoDB存储引擎使用B+树索引结构
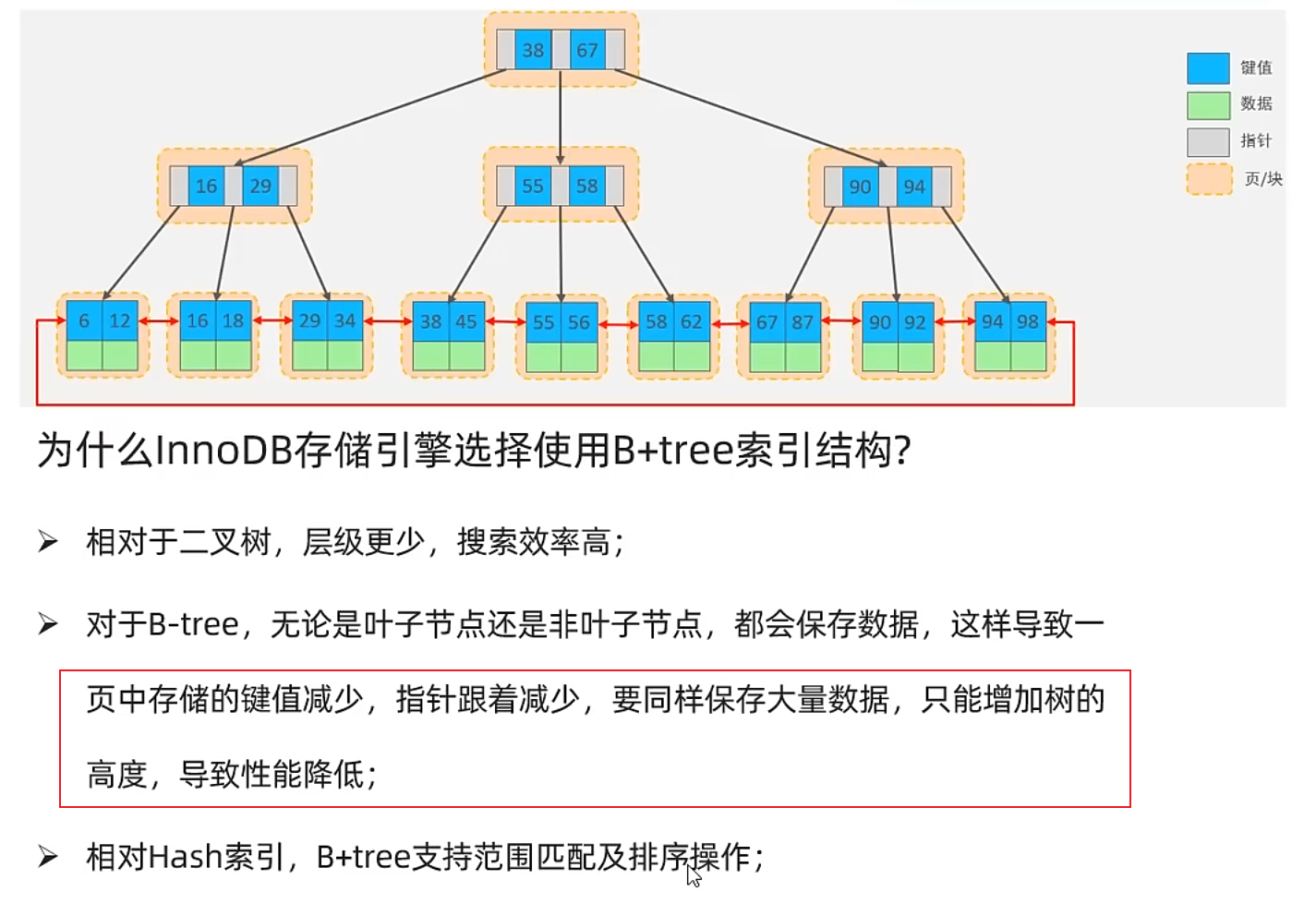
对于B树和B+树来说,每个节点都是存储在页page中,而page的大小是固定为16k的,所以对于B树来说,page中存储数据的话,会抢占key和指针的空间
key和指针减少,层级就会增多,导致性能降低
索引分类
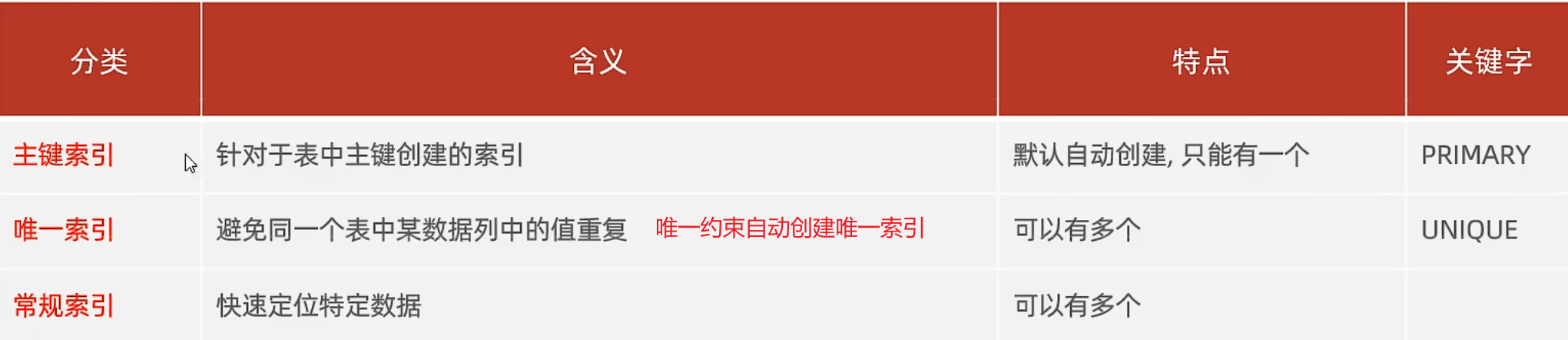
单列索引,联合索引都是常规索引
常规索引属于二级索引

聚簇索引,叶子节点保存了整行数据
非聚簇索引,叶子节点保存的是对应的主键id,如果有常规索引,也会保存常规索引字段数据

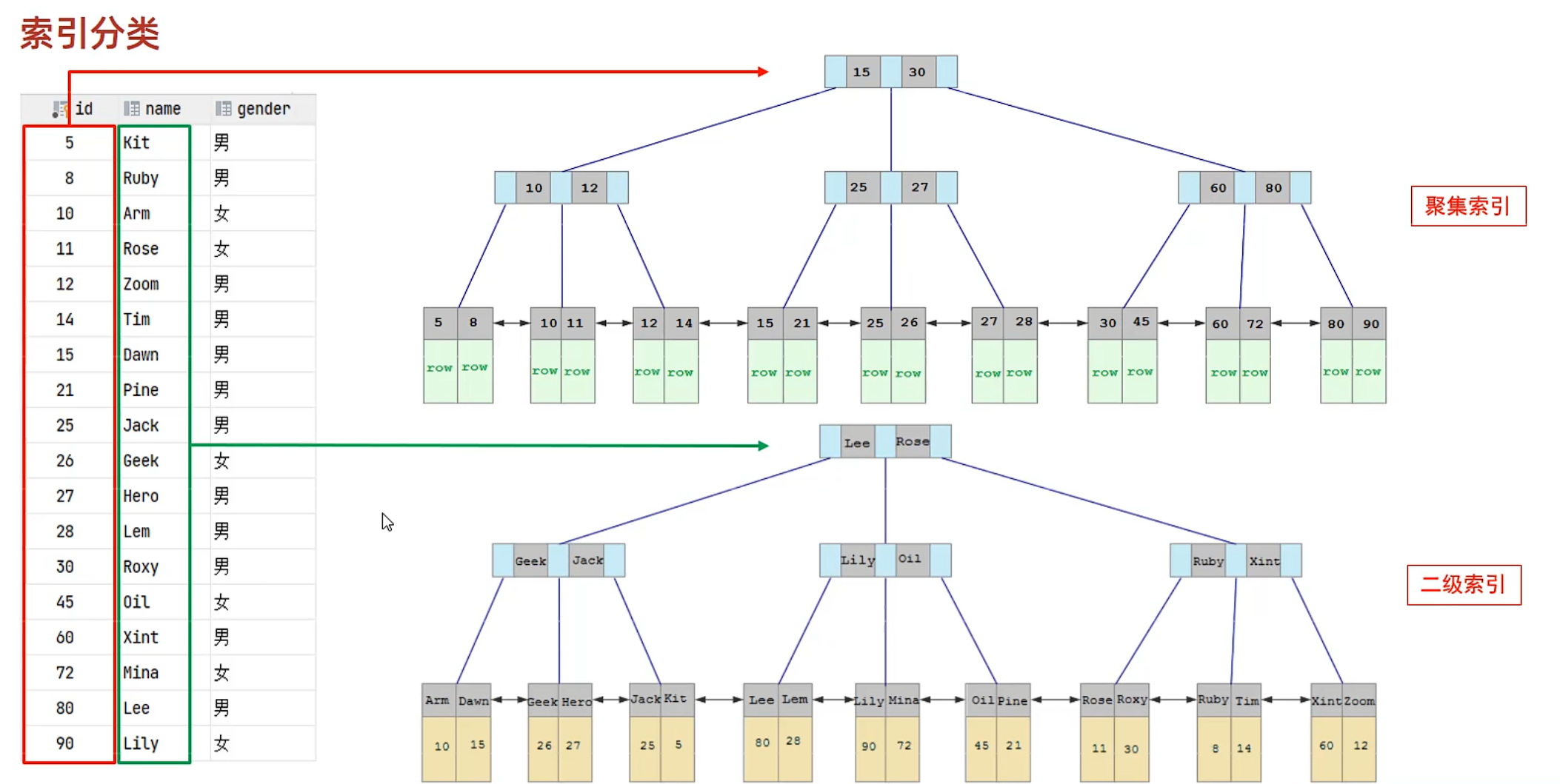
回表
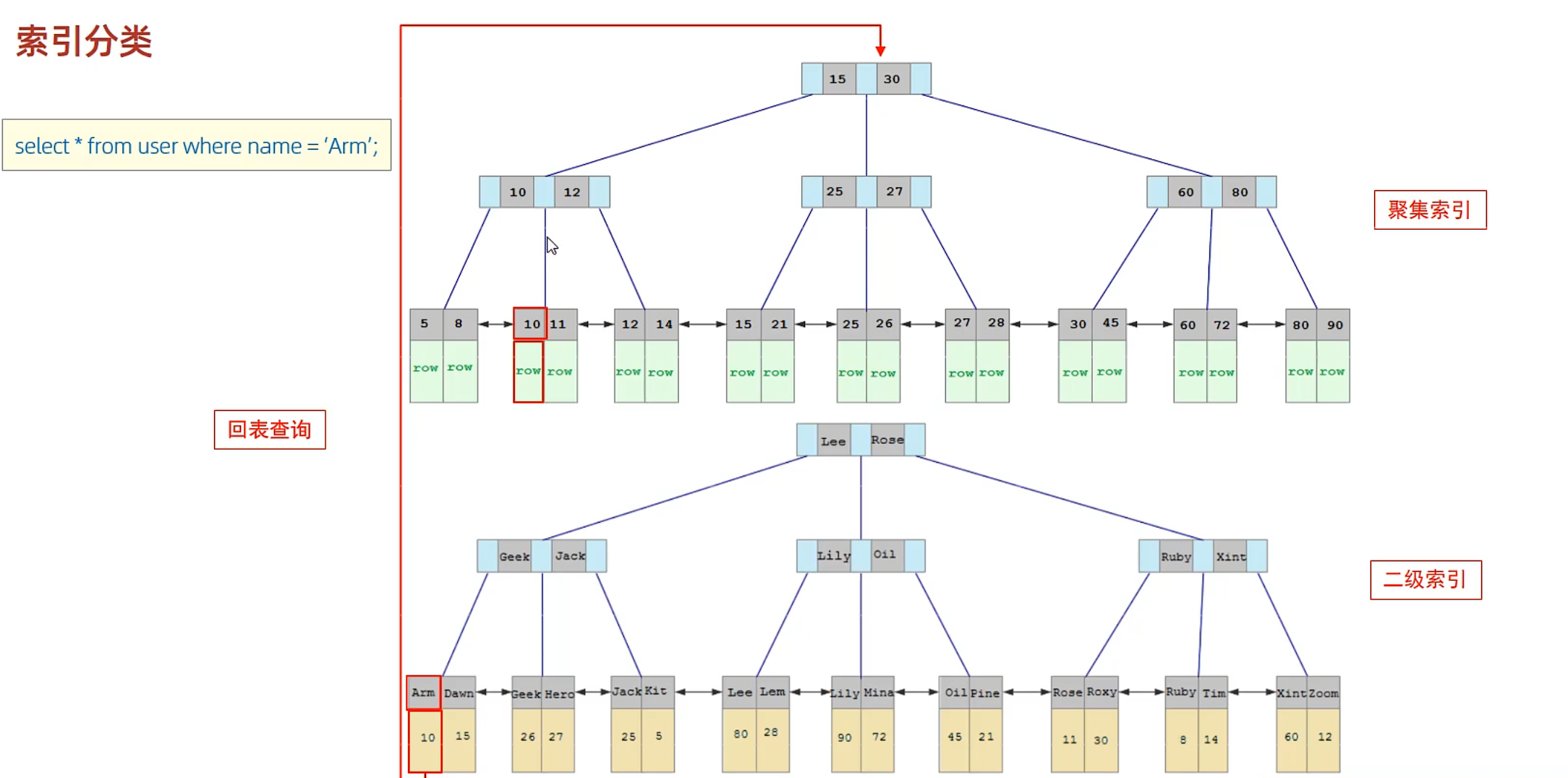
先查arm 索引找到主键id,然后根据主键id再找到对应的一整行数据
性能调优
主要对于索引来优化查询语句
com后七个_
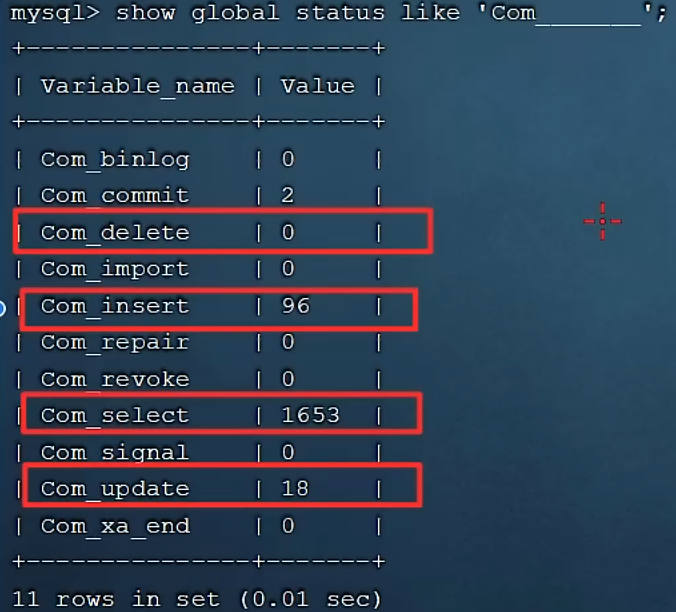
看当前数据库是插入,更新,删除,谁为主
如果发现查询占主导,就需要进行sql优化
慢查询日志
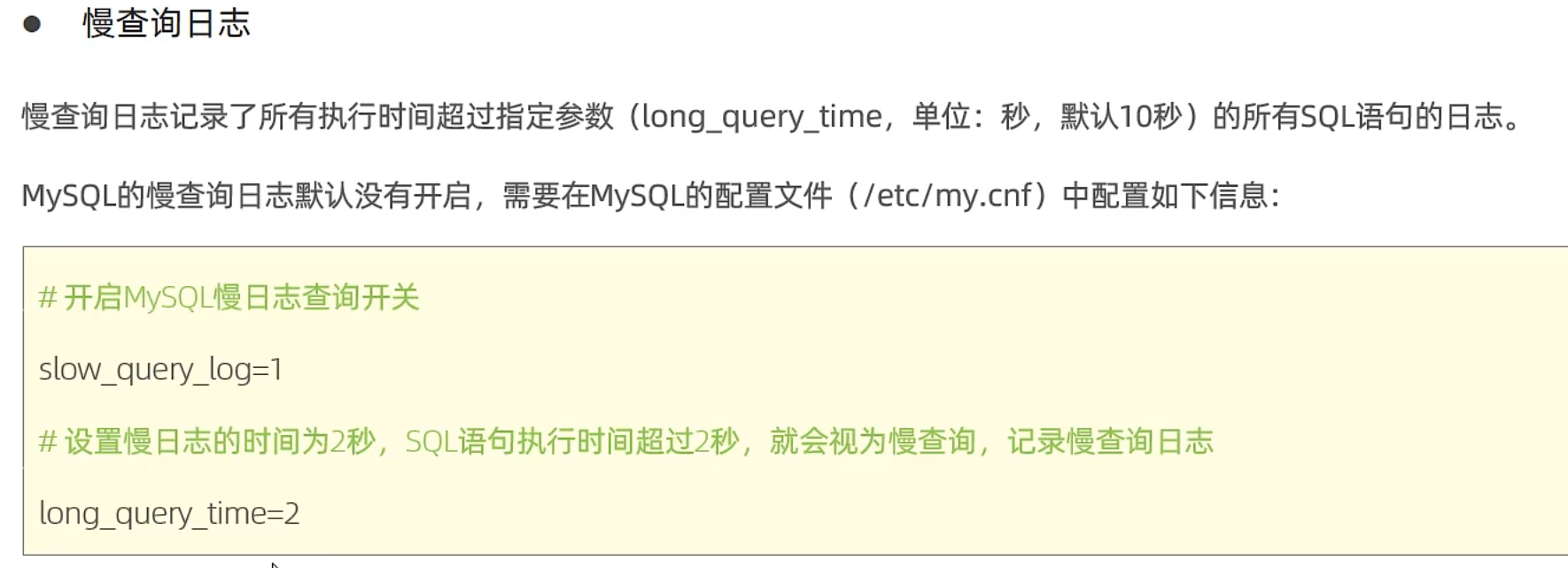
以上都是根据sql语句的执行时间来判断sql的性能,我们不能只看执行时间
explain 执行计划


多表查询
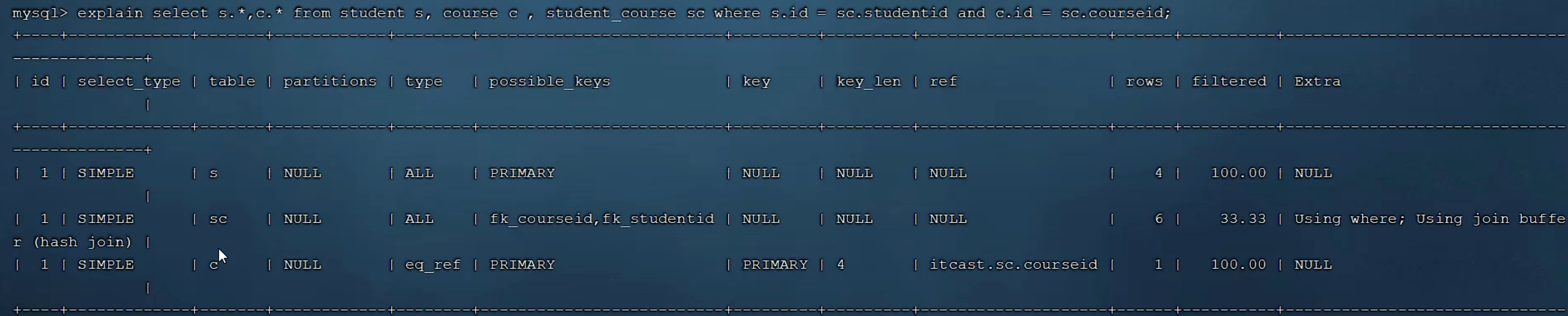
id相同,表结构执行顺序从上往下,先执行student,再执行连接表,最后执行course表
子查询(select嵌套)

id不同,值越大越先执行,先执行最内层的表,一层层执行出去

select_type意义不大,只说明当前sql的查询类型

type

对于正常业务来说,const就是最好的了,NULL是不查表,system是查询系统表
where对主键和唯一索引查询一般是const和eq_ref,对于非唯一性索引一般是ref
index虽然用了索引,但也是对索引进行全表扫描,all是全表扫描
possible_key

显示可能用到的索引
key

实际用到的索引



返回条数和实际扫描条数占比,越大越好
索引的使用
最左前缀法则(联合索引)

针对于联合索引,查询时从索引最左侧列(必须存在)开始,不跳过索引中间的列,如果跳过某一列,这一列后面的索引将会失效
创建联合索引

profession,age,status,按顺序联合,profession是最左字段


表示status这个字段索引长度是5

表示age索引长度是2

全表扫描,索引失效,因为没有最左字段

缺少中间字段,所以之后的索引部分失效,只走了profession的索引
和字段使用顺序无关,只要出现就行
范围查询(联合索引)
针对于联合索引


索引失效情况
1.对索引列进行运算操作(函数substr等)
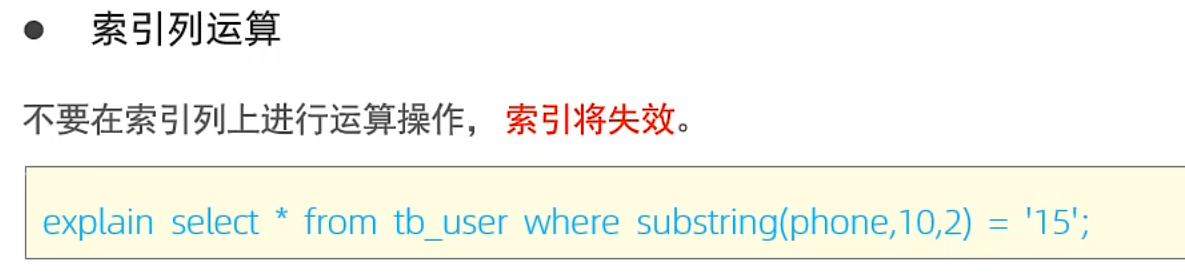
2.字符串字段没有加’’

3.头部模糊匹配,索引失效

4.or前后字段都要有索引才会走索引,不然失效
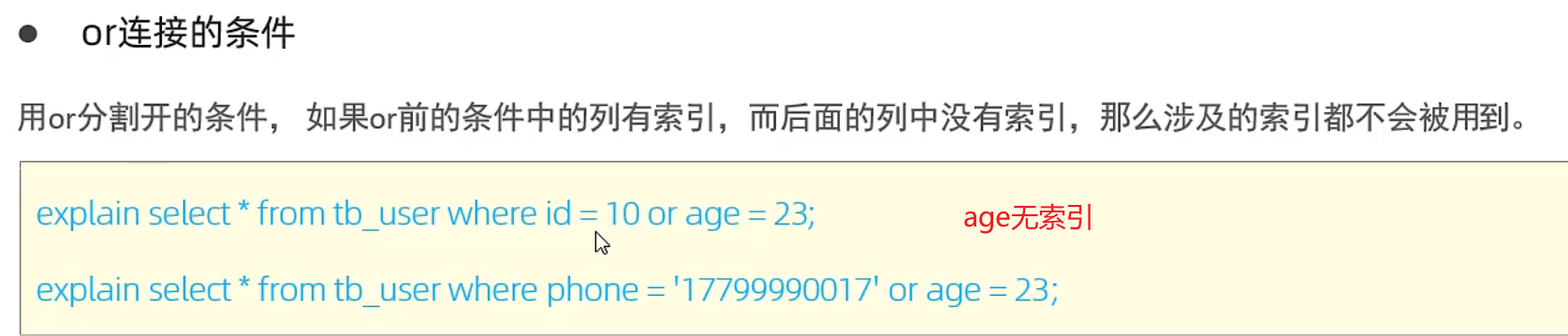

5.数据分布影响
有时候使用索引比全表扫描还慢,就不会使用索引
比如:当我们要一个条件把全表都查出来(或者表的绝大部分都是满足条件的),肯定走全表扫描比走索引快
is null (因为绝大部分都不是null,不满足)一般走索引
is not null(因为绝大部分都不是null,满足)一般不走索引
所以null要看表中数据绝大部分满不满足,如果满足,就不走,如果不满足,就走索引
SQL提示
可以给一个字段添加多个索引,比如联合索引和单列索引
mysql默认会执行联合索引(前提满足最左前缀法则)
可以指定来使用哪个索引


use index 只是一个建议,mysql可能不会用
force index 是必须用
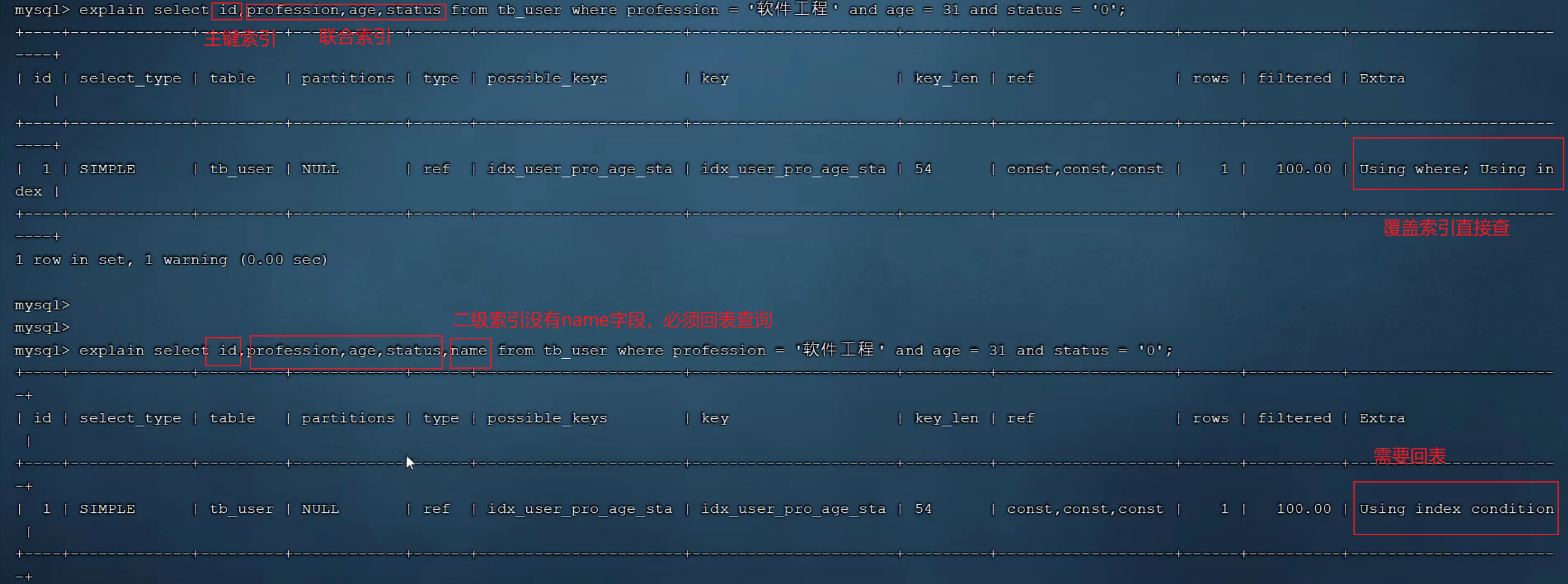
覆盖索引
select返回的字段在索引列中都能找到,而不需要回表查询,这样的索引就是覆盖索引
尽量避免select *

测试
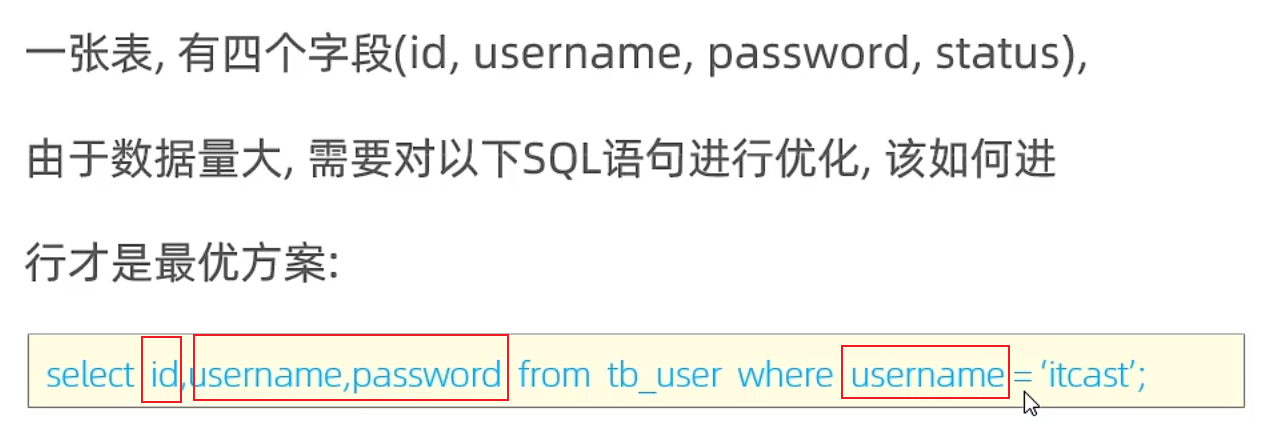
对username和password加联合索引,就不需要回表了
前缀索引

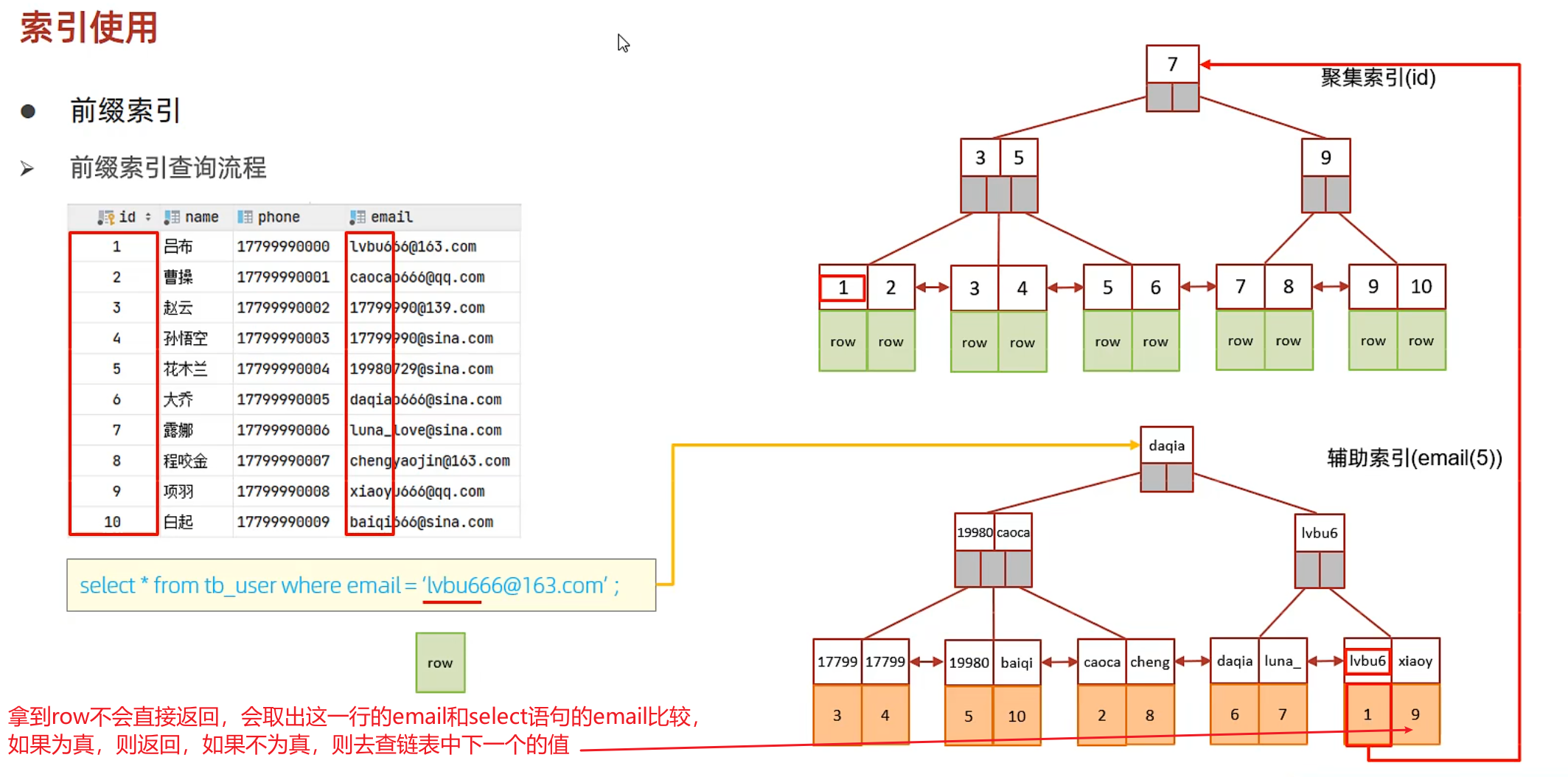
前缀索引中,回表查询拿到row这一行的数据不会直接返回,而是会对比这条数据中前缀索引字段和select语句的字段是否一致,如果一致则返回结果,如果不一致,则顺着二级索引的链表继续查找下一个判断
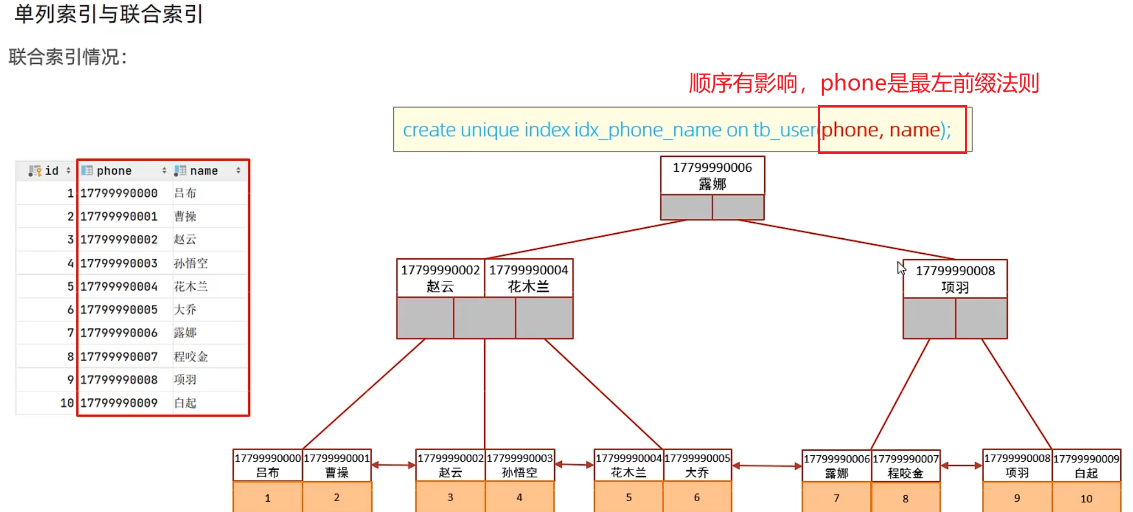
单列和联合索引的选择

一个字段可以有多个索引,比如自己的单列索引再加上和别人的联合索引
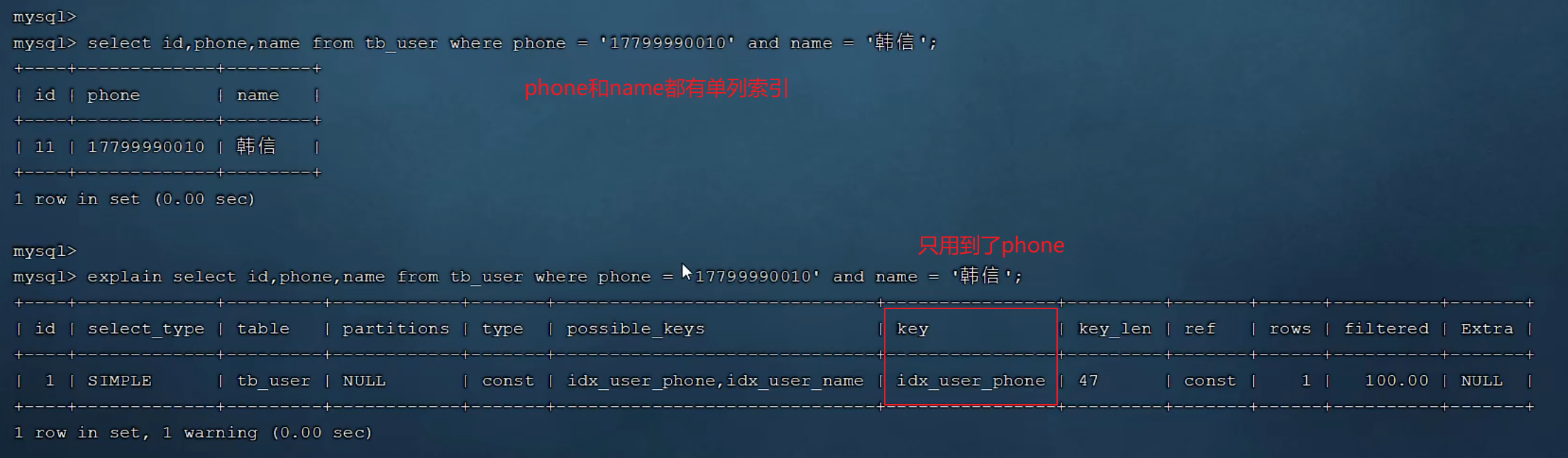
mysql会评估哪个字段的索引效率更高,会选择改索引,也就是phone索引
此时在phone的单列索引中不包含name字段,所以会进行回表查询
我们给phone和name添加上联合索引后,还是使用的phone的单列索引(单列索引干扰),还是会回表

所以我们可以用sql提示(use index)来指定mysql使用联合索引
所以,如果存在多个查询条件,我们一般建立联合索引(覆盖索引,不会回表查询)
联合索引的数据结构
索引设计原则

)


:vivo X200 Ultra影像技术沟通会总结)





)

底层的实现:)





)

)