自从 Wan 2.1 发布以来,AI 视频生成领域似乎进入了一个发展瓶颈期,但这也让人隐隐感到:“DeepSeek 时刻”即将到来!就在前几天,浙江大学与月之暗面联合推出了一款全新的文本到视频(T2V)生成模型——**LanDiff** 。这款模型通过融合语言模型和扩散模型的优势,为高质量视频生成带来了突破性进展。接下来,我们一起来深入了解这款引人注目的技术成果。
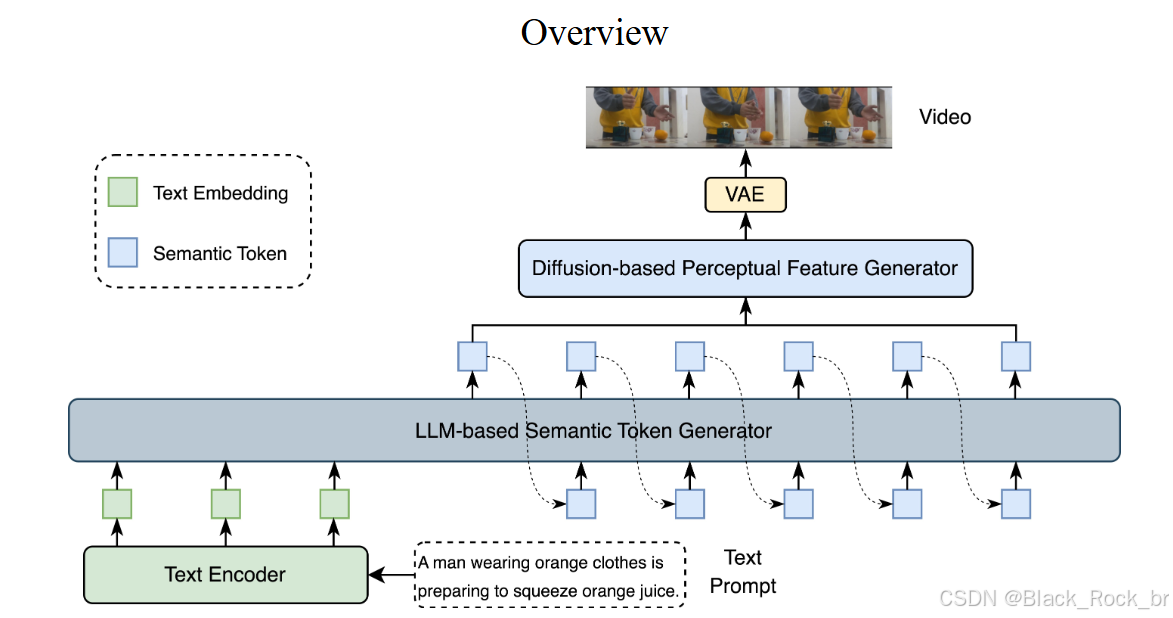
LanDiff 被誉为视频生成领域的“混血儿”,它巧妙地将擅长语义理解的语言模型与专注于图像质量的扩散模型结合在一起 。具体来说,LanDiff 首先利用语义分词器将视频内容压缩成简洁的“故事大纲”,这一步类似于搭建骨架;随后,扩散模型在此基础上逐步细化,将大纲转化为细节丰富、视觉效果出色的完整视频 。这种“先搭框架再精雕细琢”的设计,不仅确保了生成内容高度契合文本描述,还显著提升了视频的视觉质量。
在性能表现上,LanDiff 同样令人惊艳。根据 VBench 基准测试结果显示,LanDiff 以 **85.43 的高分**成功登顶,远超其他开源模型的表现 。尤其值得一提的是,LanDiff 在长视频生成任务中展现出了强大的能力,能够稳定输出连贯且高质量的内容,充分证明了其在复杂场景下的适应性和鲁棒性 。这一创新无疑为视频生成领域注入了新的活力,也为未来的应用拓展提供了更多可能性。
核心特色 | Method
LanDiff是一种混合架构,它通过粗到精的生成范式,结合了语言模型和扩散模型的优点,其架构图如下。模型的核心架构主要分为以下三个部分:视频语义分词器、基于LLM的语义Token生成器和基于扩散模型的感知特征生成器。
视频语义Tokenizer | Video Semantic Tokenizer
“压缩与理解的双重魔法”:LanDiff 中的视频语义 Tokenizer
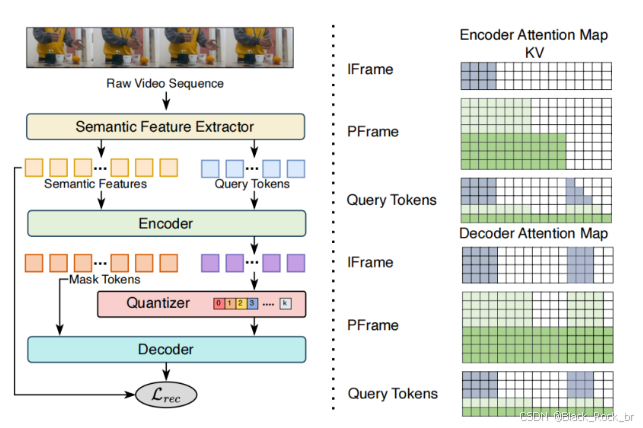
在 LanDiff 模型中,视频语义 Tokenizer 被誉为整个架构的“压缩大师”,其核心任务是将复杂的视频信息压缩成简洁的语义表达,同时保留视频的核心语义和细节。这种能力不仅减轻了后续语言模型和扩散模型的负担,还显著提升了生成效率和质量 。
---
查询分词:聚焦关键信息
Tokenizer 的一大创新在于**查询分词(Query Tokens)**,这是一种随机初始化的标记机制,用于与视频的语义特征交互,提取出最能代表视频内容的关键信息。这些查询 tokens 就像“信息雷达”,能够在庞大的视频数据中精准锁定重要语义点,从而实现高效的语义压缩与理解 。
---
视频语义表示:选择更优的特征提取方式
LanDiff 并未直接使用自编码器学习的特征,而是选择了预训练的**自监督学习特征(SSL)** 作为视频表示,并采用 Theia 模型进行视觉特征提取。这种设计的原因在于,SSL 特征能够更好地保留视频的高层次语义信息,而 Theia 模型经过多个视觉任务模型(如 CLIP、SAM、DINOv2、ViT 和 Depth-Anything)的提炼,确保了编码后的特征具有丰富的语义内涵 。
---
Tokenizer 的具体实现
在技术实现上,LanDiff 的 Tokenizer 采用了基于 Transformer 的结构,并结合查询嵌入来聚合视觉特征,从而实现极高的压缩率。具体流程如下:
1. 语义特征提取
首先,使用 Theia 模型提取视频的语义特征,并将其扁平化处理,以便后续操作 。
2. 查询 tokens 的引入
然后,引入一组随机初始化的查询 tokens,并将它们与提取的语义特征拼接在一起。这些查询 tokens 在语义特征中扮演了“信息提取器”的角色。
3. Transformer 编码
使用 Transformer 编码器对拼接后的特征进行编码,最终仅保留查询 tokens 的编码结果,作为后续处理的基础。
4. 向量量化
接下来,通过训练 VQ-VAE 模型对查询 tokens 的编码特征进行向量量化,得到离散的语义 tokens。这一过程以最小化视频语义特征的重建损失为目标,并采用 EMA(指数移动平均)的方式更新模型参数。
5. 解码阶段
在解码阶段,量化后的特征被用作条件输入,并在其前添加一系列 mask tokens,形成解码器的输入序列 。
视频帧分组策略:高效压缩与建模
LanDiff 的视频帧分组策略灵感来源于 MP4 视频编码算法,通过将视频帧分为**关键帧(I-Frame)** 和**非关键帧(P-Frame)**,大幅减少了计算量和数据量:
1. 分组与建模
将 N 帧视频划分为 N/T 组,每组包含 T 帧。每一组独立建模,确保处理效率。
2. 关键帧与非关键帧的差异化处理
- 关键帧(I-Frame):完整编码每组的第一帧,赋予大量查询 tokens,以实现高质量重建。
- 非关键帧(P-Frame):仅捕捉时间上的变化,参考先前的关键帧进行编码,并分配少量查询 tokens,迫使模型专注于帧间差异。
3. 掩码机制
在编码过程中,对特征序列应用帧级别的因果掩码,确保每个 token 只能关注相应帧及之前的帧特征 。
4. 解码中的上下文依赖
在解码阶段,每个帧对应的 mask token 不仅可以看到自身的查询 tokens,还可以参考先前帧的特征和查询 tokens,从而实现上下文依赖的高效解码。
压缩率与质量的双赢
LanDiff 的视频语义 Tokenizer 在压缩率和生成质量之间实现了完美的平衡。对于一段分辨率为 480x720 的一秒视频,LanDiff 平均仅需生成约 200 个 tokens,而常见的 MagViT2 tokenizer 则需要生成约 10,000 个 tokens 。这意味着 LanDiff 的序列长度仅为 MagViT2 的 1/50,显著降低了计算复杂度和资源消耗。与此同时,LanDiff 在语义保留和视频重建质量方面依然表现出色,真正实现了高效压缩与高质量输出的双赢 。
用于语义Token生成的语言模型
语言模型与高效分词器的结合:通过训练高效的分词器,利用语言模型进行自回归生成语义化的分词,从而实现从文本到视频的生成过程。
多模态特征提取:借助预训练的T5-XXL模型提取文本特征,并利用视频语义Tokenizer(在前一节中介绍)将视频转换为离散的分词序列,实现文本与视频的跨模态融合。
可控生成条件:引入帧条件和运动分数条件等控制条件,增强对生成视频的控制能力,以满足不同场景的需求。
模型结构与训练:采用LLaMA模型结构,从头开始训练,并使用交叉熵损失函数,确保模型的生成性能和稳定性。
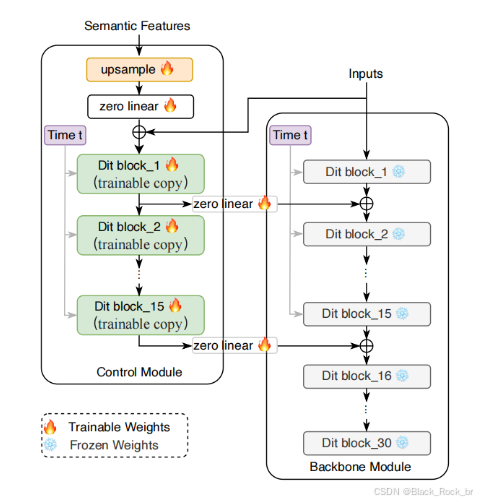
用于生成感知特征的扩散模型
目标:将上一章节中生成的语义tokens转换为VAE潜在向量,作为视频detokenizer,负责将语义tokens转换成视频。
架构:
- 采用类似于MMDiT的架构。
- 使用视频tokenizer解码器将语义tokens解码为语义特征 \(\hat{F}\)。
- 以语义特征 \(\hat{F}\) 作为条件,指导扩散模型生成视频。
- 引入类似于ControlNet风格的控制模块,基于语义特征指导模型生成感知特征。在训练期间,主模型的参数保持不变,控制模块复制主模型前半部分层的参数,并在经过一个用零初始化的线性层后添加到主模型的输出。
- 为了使语义特征在空间维度上与目标VAE特征匹配,额外添加了一个上采样模块。
训练:


Chunk-wise流式策略:

模型参数:
- 整个视频detokenizer的总参数为3B,其中可训练的控制模块参数数量为1B。
- 以CogVideoX-2B模型作为视频detokenizer的基础模型。
为了不重复之前的表述,我将对这段内容进行重新组织和润色,同时保留原文的核心观点和信息,以下是改写后的内容:
我们暂且不深入探讨更多的实验细节与评测数据,但可以肯定的是,该模型的表现无疑是处于行业顶尖水平(SOTA)。至于模型是否开源,目前尚未有明确消息。不过,LanDiff的成功无疑凸显了混合架构在突破单一方法固有局限性方面的巨大潜力,为依据文本描述生成连贯、语义忠实且视觉效果卓越的视频开辟了新的道路。当下,从单模态生成迈向多模态生成,从Janus到dLLM,越来越多的研究致力于实现语言模型与扩散模型的融合。基于此,我们有充分的理由相信,文本到视频生成技术的融合与成功,必将为创意表达与内容创作注入新的活力,带来前所未有的机遇。
开源地址:LanDiff


)

底层的实现:)





)

)
)


)

绑定导入表)
