目录
- 9.1 代价函数
- 9.2 反向传播算法
- 9.3 反向传播算法的直观理解
9.1 代价函数
首先引入一些便于稍后讨论的新标记方法:
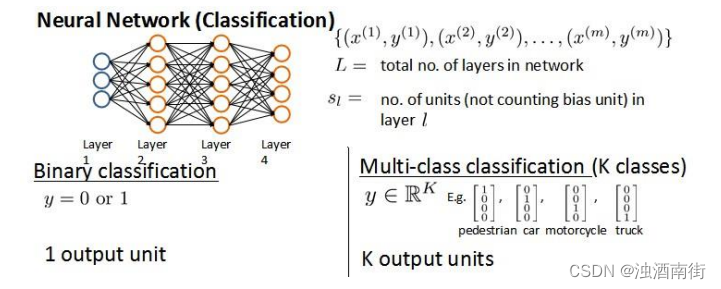
假设神经网络的训练样本有𝑚个,每个包含一组输入𝑥和一组输出信号𝑦,𝐿表示神经网络层数,𝑆𝐼表示每层的 neuron 个数(𝑆𝑙表示输出层神经元个数),𝑆𝐿代表最后一层中处理单元的个数。
将神经网络的分类定义为两种情况:二类分类和多类分类,
二类分类:𝑆𝐿 = 0, 𝑦 = 0 𝑜𝑟 1 表示哪一类;
𝐾类分类:𝑆𝐿 = 𝑘, 𝑦𝑖 = 1表示分到第 i 类;(𝑘 > 2)
我们回顾逻辑回归问题中我们的代价函数为:
J ( θ ) = − 1 m [ ∑ j = 1 n y ( i ) l o g h θ ( x ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 J(θ) = -\frac{1}{m}[ \sum_{j=1}^n {y^{(i)}logh_θ (x^{(i)}) + (1-y^{(i)})log(1-h_θ (x^{(i)}))}] +\frac{λ}{2m}\sum_{j=1}^n {θ_j^{2}} J(θ)=−m1[j=1∑ny(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
在逻辑回归中,我们只有一个输出变量,又称标量(scalar),也只有一个因变量𝑦,但是在神经网络中,我们可以有很多输出变量,我们的ℎ𝜃(𝑥)是一个维度为𝐾的向量,并且我们训练集中的因变量也是同样维度的一个向量,因此我们的代价函数会比逻辑回归更加复杂一些,为:
h θ ( x ) ∈ R k , ( h θ ( x ) ) i = i t h o u t p u t h_θ(x)∈ℝ^k,(h_θ(x))_i =i^{th}output hθ(x)∈Rk,(hθ(x))i=ithoutput
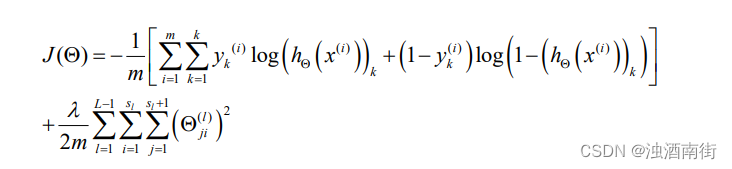
这个看起来复杂很多的代价函数背后的思想还是一样的,我们希望通过代价函数来观察算法预测的结果与真实情况的误差有多大,唯一不同的是,对于每一行特征,我们都会给出𝐾个预测,基本上我们可以利用循环,对每一行特征都预测𝐾个不同结果,然后在利用循环在𝐾个预测中选择可能性最高的一个,将其与𝑦中的实际数据进行比较。
正则化的那一项只是排除了每一层 θ 0 θ_0 θ0后,每一层的𝜃 矩阵的和。最里层的循环𝑗循环所有的行(由𝑠𝑙 +1 层的激活单元数决定),循环𝑖则循环所有的列,由该层(𝑠𝑙层)的激活单元数所决定。即:ℎ𝜃(𝑥)与真实值之间的距离为每个样本-每个类输出的加和,对参数进行regularization 的 bias 项处理所有参数的平方和。
9.2 反向传播算法
之前我们在计算神经网络预测结果的时候我们采用了一种正向传播方法,我们从第一层开始正向一层一层进行计算,直到最后一层的ℎ𝜃(𝑥)。
现在,为了计算代价函数的偏导数 ∂ ∂ θ i j ( l ) J ( θ ) \frac{ ∂}{∂θ_{ij}^{(l)}}J(θ) ∂θij(l)∂J(θ)
我们需要采用一种反向传播算法,也就是首先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层。 以一个例子来说明反向传播算法。
假设我们的训练集只有一个实例( x ( 1 ) x^{(1)} x(1), y ( 1 ) y^{(1)} y(1)),我们的神经网络是一个四层的神经网络,其中K = 4, S L S_L SL = 4,L= 4:
前向传播算法:

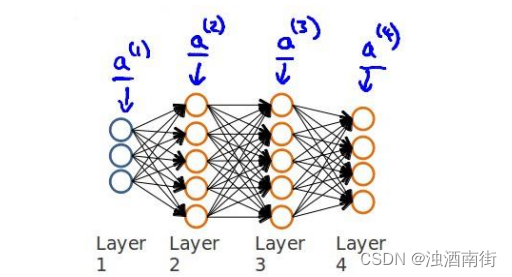
我们从最后一层的误差开始计算,误差是激活单元的预测( a k ( 4 ) a_k^{(4)} ak(4))与实际值( y k y^k yk)之间的误差,(𝑘 = 1: 𝑘)。
我们用𝛿来表示误差,则: δ ( 4 ) = a ( 4 ) − y δ(4) = a(4) − y δ(4)=a(4)−y;
我们利用这个误差值来计算前一层的误差: δ ( 3 ) = ( θ ( 3 ) ) T δ ( 4 ) ∗ g ′ ( z ( 3 ) ) δ(3) = (θ^{(3)})^Tδ(4)∗ g'(z^{(3)}) δ(3)=(θ(3))Tδ(4)∗g′(z(3)),其中 g’(z^{(3)})是 s形函数的导数, g ′ ( z ( 3 ) ) = a ( 3 ) ∗ ( 1 − a ( 3 ) ) g'(z^{(3)}) = a^{(3)}∗ (1-a^{(3)}) g′(z(3))=a(3)∗(1−a(3))。而 ( θ ( 3 ) ) T δ ( 4 ) (θ^{(3)})^Tδ(4) (θ(3))Tδ(4)则是权重导致的误差的和。
下一步是继续计算第二层的误差: δ ( 2 ) = ( θ ( 2 ) ) T δ ( 3 ) ∗ g ′ ( z ( 2 ) ) δ(2) = (θ^{(2)})^Tδ(3)∗ g'(z^{(2)}) δ(2)=(θ(2))Tδ(3)∗g′(z(2))
因为第一层是输入变量,不存在误差。我们有了所有的误差的表达式后,便可以计算代价函数的偏导数了,假设𝜆 = 0,即我们不做任何正则化处理时有:
∂ ∂ θ i j ( l ) J ( θ ) = a j ( l ) δ i ( l + 1 ) \frac{ ∂}{∂θ_{ij}^{(l)}}J(θ) = a_j^{(l)}δ_i^{(l+1)} ∂θij(l)∂J(θ)=aj(l)δi(l+1)
重要的是清楚地知道上面式子中上下标的含义:
𝑙 代表目前所计算的是第几层。
𝑗 代表目前计算层中的激活单元的下标,也将是下一层的第𝑗个输入变量的下标。
𝑖 代表下一层中误差单元的下标,是受到权重矩阵中第𝑖行影响的下一层中的误差单元的下标。
如果我们考虑正则化处理,并且我们的训练集是一个特征矩阵而非向量。在上面的特殊情况中,我们需要计算每一层的误差单元来计算代价函数的偏导数。在更为一般的情况中,我们同样需要计算每一层的误差单元,但是我们需要为整个训练集计算误差单元,此时的误差单元也是一个矩阵,我们用 △ i j ( l ) △ij^{(l)} △ij(l)来表示这个误差矩阵。第 𝑙 层的第 𝑖 个激活单元受到第 𝑗个参数影响而导致的误差。
我们的算法表示为:

即首先用正向传播方法计算出每一层的激活单元,利用训练集的结果与神经网络预测的结果求出最后一层的误差,然后利用该误差运用反向传播法计算出直至第二层的所有误差。
在求出了𝛥𝑖𝑗(𝑙)之后,我们便可以计算代价函数的偏导数了,计算方法如下:
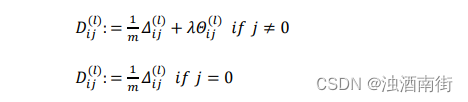
在 Octave 中,如果我们要使用 fminuc 这样的优化算法来求解求出权重矩阵,我们需要将矩阵首先展开成为向量,在利用算法求出最优解后再重新转换回矩阵。
假设我们有三个权重矩阵,Theta1,Theta2 和 Theta3,尺寸分别为 1011,1011 和1*11, 下面的代码可以实现这样的转换:

9.3 反向传播算法的直观理解
在上一段视频中,我们介绍了反向传播算法,对很多人来说,当第一次看到这种算法时,第一印象通常是,这个算法需要那么多繁杂的步骤,简直是太复杂了,实在不知道这些步骤,到底应该如何合在一起使用。就好像一个黑箱,里面充满了复杂的步骤。如果你对反向传播
算法也有这种感受的话,这其实是正常的,相比于线性回归算法和逻辑回归算法而言,从数学的角度上讲,反向传播算法似乎并不简洁,对于反向传播这种算法,其实我已经使用了很多年了,但即便如此,即使是现在,我也经常感觉自己对反向传播算法的理解并不是十分深入,对于反向传播算法究竟是如何执行的,并没有一个很直观的理解。做过编程练习的同学应该可以感受到这些练习或多或少能帮助你,将这些复杂的步骤梳理了一遍,巩固了反向传播算法具体是如何实现的,这样你才能自己掌握这种算法。
在这段视频中,我想更加深入地讨论一下反向传播算法的这些复杂的步骤,并且希望给你一个更加全面直观的感受,理解这些步骤究竟是在做什么,也希望通过这段视频,你能理解,它至少还是一个合理的算法。但可能你即使看了这段视频,你还是觉得反向传播依然很复杂,依然像一个黑箱,太多复杂的步骤,依然感到有点神奇,这也是没关系的。即使是我接触反向传播这么多年了,有时候仍然觉得这是一个难以理解的算法,但还是希望这段视频能有些许帮助,为了更好地理解反向传播算法,我们再来仔细研究一下前向传播的原理:
前向传播算法:
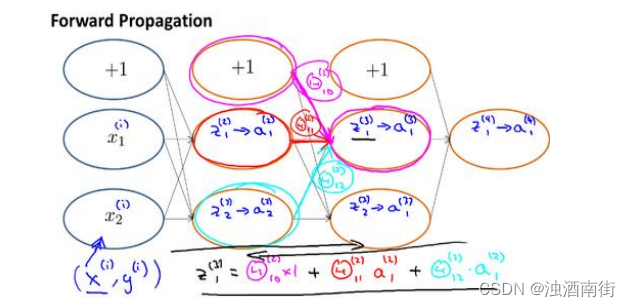
反向传播算法做的是:







)
springboot集成kafka(1)介绍)




信息泄漏原理以及修复方法)


——SPA和积译码算法的简化)

)

