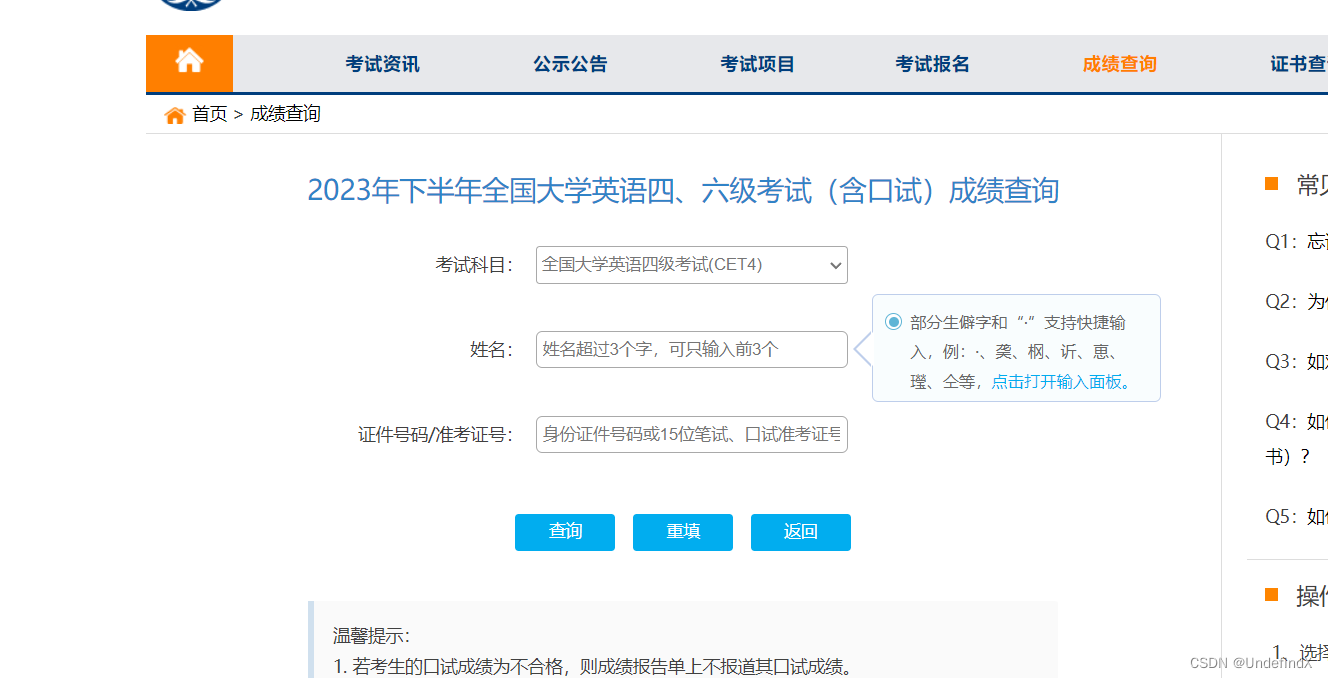
在六级成绩刚发布时,只需要通过学生姓名和身份证号便可以查询到成绩
据此,我们可以利用selenium框架对学生的成绩进行爬取
首先我们要建立一个excel表格,里面放三列(多几列也无所谓),第一列列名取为学生姓名,第二列取为公民身份号码,这两列需要放入已有数据,第三列取为6级成绩,列中不需要放入数据,供后期存入用。
环境搭建: pip install selenium即可
from selenium import webdriver
from selenium.common import TimeoutException
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.by import By
import pandas as pd
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
data=pd.read_excel('liuji.xlsx')
data_xm=data['学生姓名'].tolist()
data_no=data['公民身份号码'].tolist()# 声明 Chrome 浏览器并设置选项
options = webdriver.ChromeOptions()
options.add_experimental_option('detach', True)# 创建 Chrome WebDriver,并将选项传递给它
browser = webdriver.Chrome(options=options)
url = 'https://cjcx.neea.edu.cn/html1/folder/21083/9970-1.htm'
browser.get(url)select_element = browser.find_element(by='xpath',value="//select[@id='km']")# 使用 Select 类来操作 select 元素
select = Select(select_element)# 选择第二个选项,根据 value 属性选择
select.select_by_value('2')
time.sleep(2)
score_list=[]
for id in range(len(data_xm)):xm = data_xm[id]no = data_no[id]input1=browser.find_element(by='id', value='xm')input1.clear()input1.send_keys(xm)input2=browser.find_element(by='id', value='no')input2.clear()input2.send_keys(no)#browser.save_screenshot(f'image/{xm}.png')button=browser.find_element(by='xpath',value="//input[@id='submitButton']")button.click()# 等待页面跳转try:WebDriverWait(browser, 2).until(EC.url_changes(browser.current_url))# 执行成功跳转后的操作print(f"成功跳转,当前 URL: {browser.current_url}")except TimeoutException:# 超时处理,继续下一轮循环print("页面跳转超时,继续下一轮循环")continuescore_xpath=browser.find_element(by="xpath",value="//*[@id='achievement-tbody']/tr/td[3]")score=score_xpath.textscore_list.append(score)browser.back()data['6级分数'] = score_list data.to_excel('liuji.xlsx', index=False)这样就可以非常高效地爬取到同学们地成绩了
)











)


)

)

