转眼写spark一年半了,从之前写机器学习组件、做olap到后面做图计算,一直都是用的spark,惭愧的是没太看过里面的源码。这篇文章的目的是总结一下Spark里面比较重要的point,重点部分会稍微看一下源代码,因为spark是跟clickhouse同级别的东西,复杂度也是相当的高,因为时间原因,本文也不会过度地进行展开。
只能说:源码用时方恨少。以前在写spark的时候没看源码实现真的挺遗憾的,现在也没那么多时间让我一点点细看了,之后稳定下来之后希望能有机会吧。
数据抽象
RDD
RDD 是一种抽象,是 Spark 对于分布式数据集的抽象,它用于囊括所有内存中和磁盘中的分布式数据实体。
数据分片(Partitions)是 RDD 抽象的重要属性之一。
在初步认识了 RDD 之后,接下来咱们换个视角,从 RDD 的重要属性出发,去进一步深入理解 RDD。
要想吃透 RDD,我们必须掌握它的 4 大属性:
- partitions:数据分片(由partitioner决定)
- partitioner:分片切割规则
- dependencies:RDD 依赖
- compute:转换函数
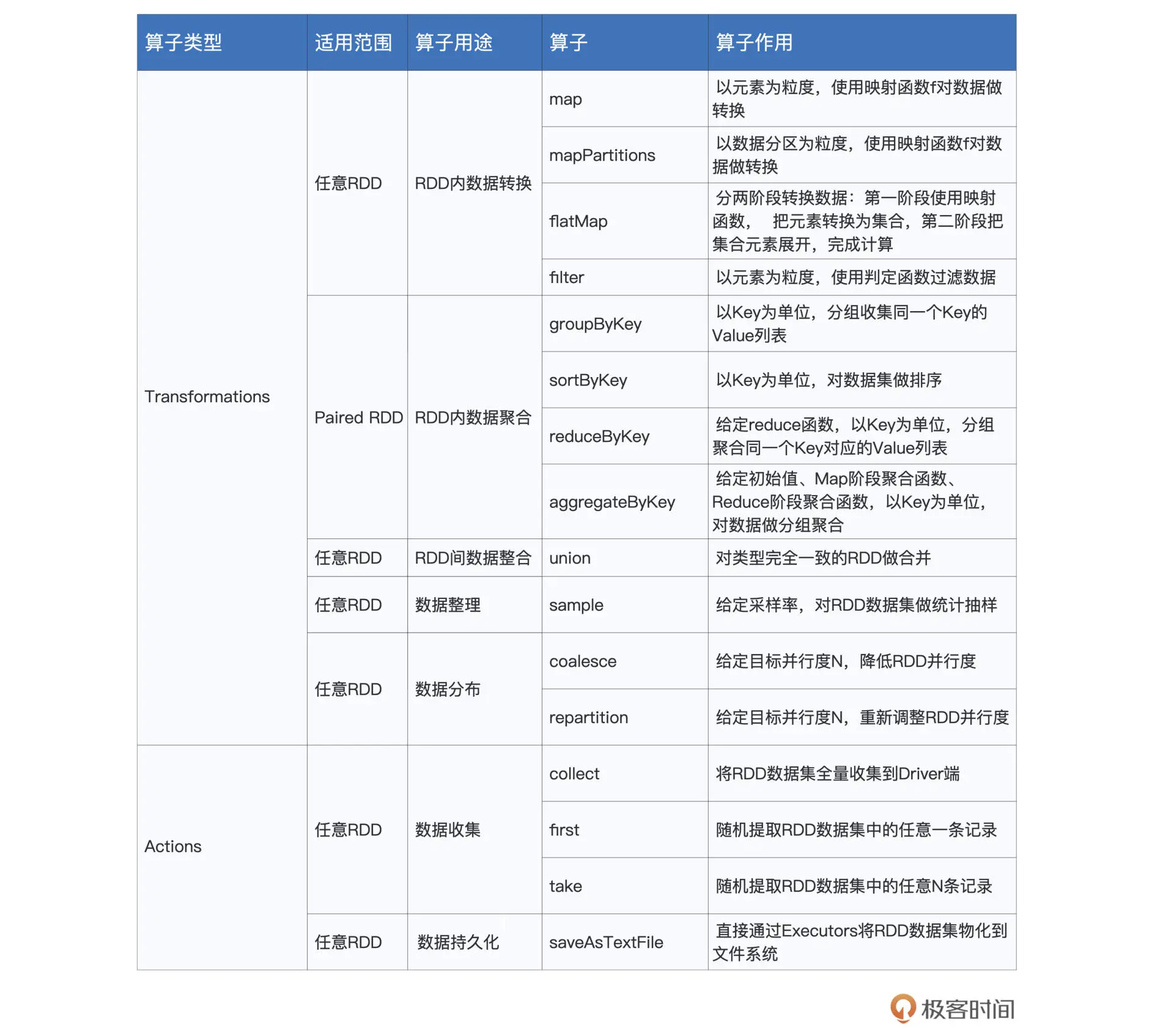
在 RDD 的编程模型中,一共有两种算子,Transformations 类算子和 Actions 类算子。开发者需要使用 Transformations 类算子,定义并描述数据形态的转换过程,然后调用 Actions 类算子,将计算结果收集起来、或是物化到磁盘。
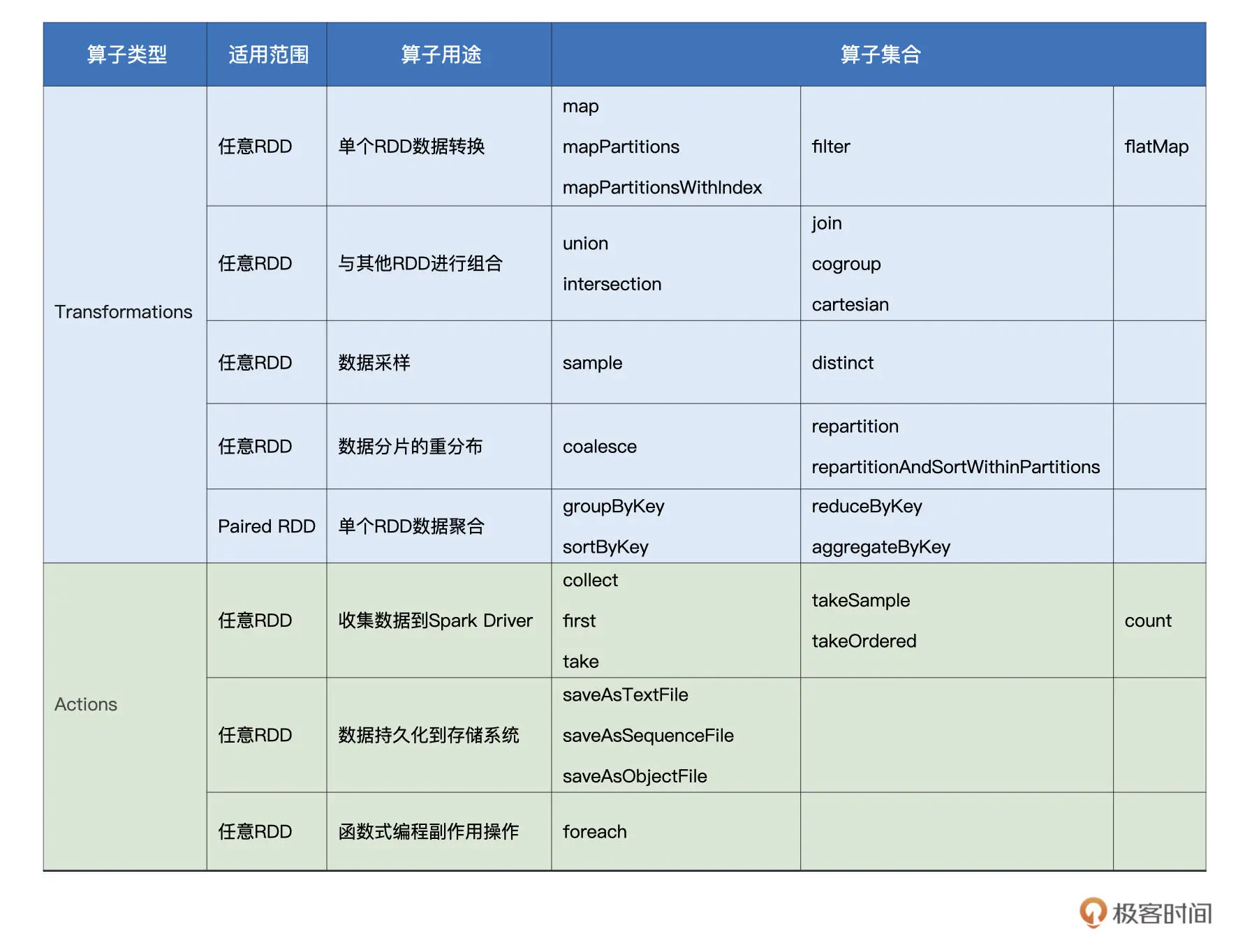
在 Spark 中,创建 RDD 的典型方式有两种:
- 通过 SparkContext.parallelize 在内部数据之上创建 RDD;
- 通过 SparkContext.textFile 等 API 从外部数据创建 RDD。
使用分区变量而非RDD变量
在下面的例子中,RDD每一条都会产生一个MD5对象,这是没必要的。
// 把普通RDD转换为Paired RDDimport java.security.MessageDigestval cleanWordRDD: RDD[String] = _ val kvRDD: RDD[(String, Int)] = cleanWordRDD.map{ word =>// 获取MD5对象实例val md5 = MessageDigest.getInstance("MD5")// 使用MD5计算哈希值val hash = md5.digest(word.getBytes).mkString// 返回哈希值与数字1的Pair(hash, 1)
}
使用mapPartitions可以以数据分区为粒度的数据转换:
// 把普通RDD转换为Paired RDDimport java.security.MessageDigestval cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码val kvRDD: RDD[(String, Int)] = cleanWordRDD.mapPartitions( partition => {// 注意!这里是以数据分区为粒度,获取MD5对象实例val md5 = MessageDigest.getInstance("MD5")val newPartition = partition.map( word => {// 在处理每一条数据记录的时候,可以复用同一个Partition内的MD5对象(md5.digest(word.getBytes()).mkString,1)})newPartition
})
DataFrame
进程模型
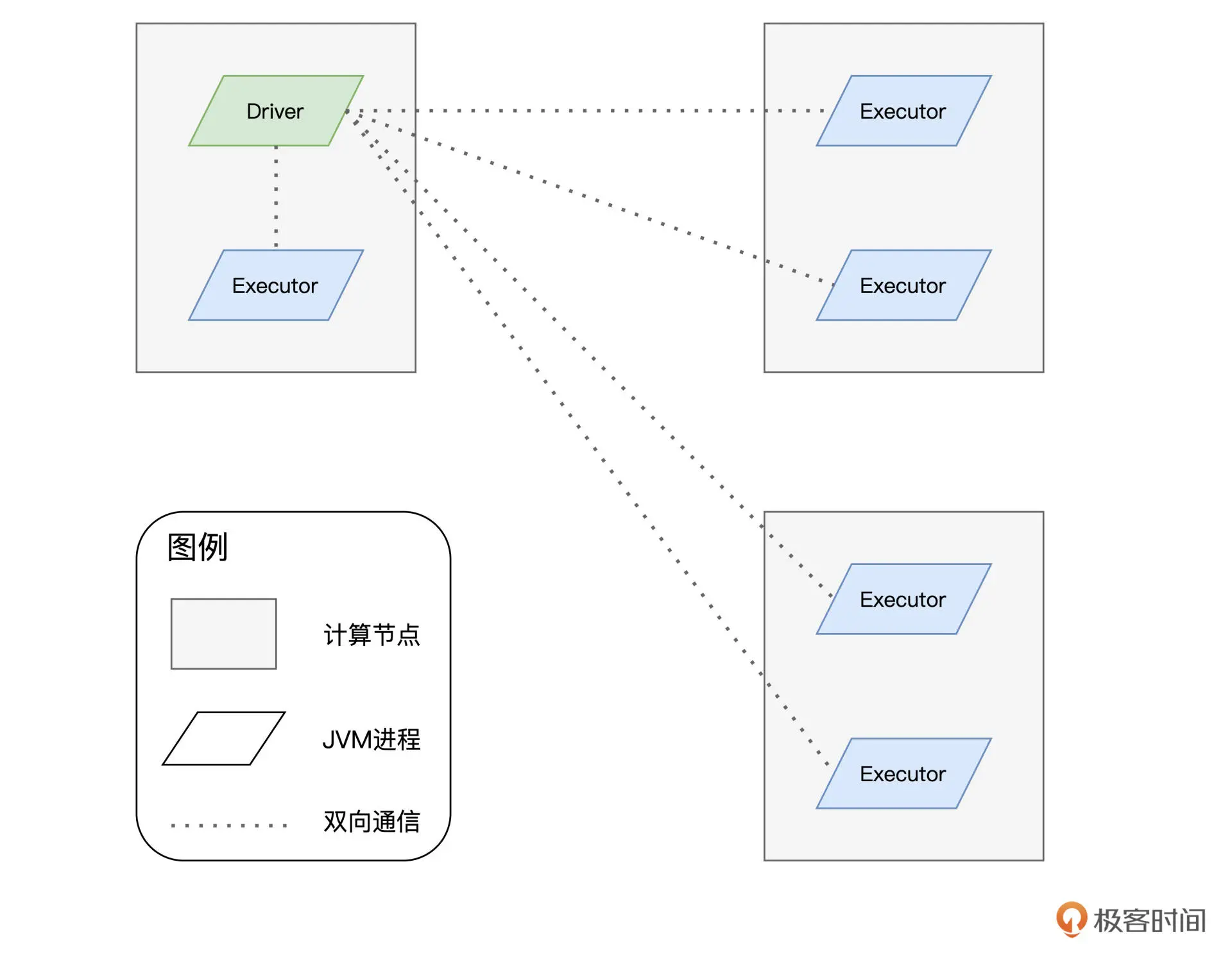
对于一个完整的 RDD,每个 Executors 负责处理这个 RDD 的一个数据分片子集。每当任务执行完毕,Executors 都会及时地与 Driver 进行通信、汇报任务状态。Driver 在获取到 Executors 的执行进度之后,结合计算流图的任务拆解,依次有序地将下一阶段的任务再次分发给 Executors 付诸执行,直至整个计算流图执行完毕。
调度模型
DAGScheduler 的主要职责有三个:
- 根据用户代码构建 DAG;
- 以 Shuffle 为边界切割 Stages;
- 基于 Stages 创建 TaskSets,并将 TaskSets 提交给 TaskScheduler 请求调度。
SchedulerBackend 用一个叫做 ExecutorDataMap 的数据结构,来记录每一个计算节点中 Executors 的资源状态。这里的 ExecutorDataMap 是一种 HashMap,它的 Key 是标记 Executor 的字符串,Value 是一种叫做 ExecutorData 的数据结构。
ExecutorData 用于封装 Executor 的资源状态,如 RPC 地址、主机地址、可用 CPU 核数和满配 CPU 核数等等,它相当于是对 Executor 做的“资源画像”。
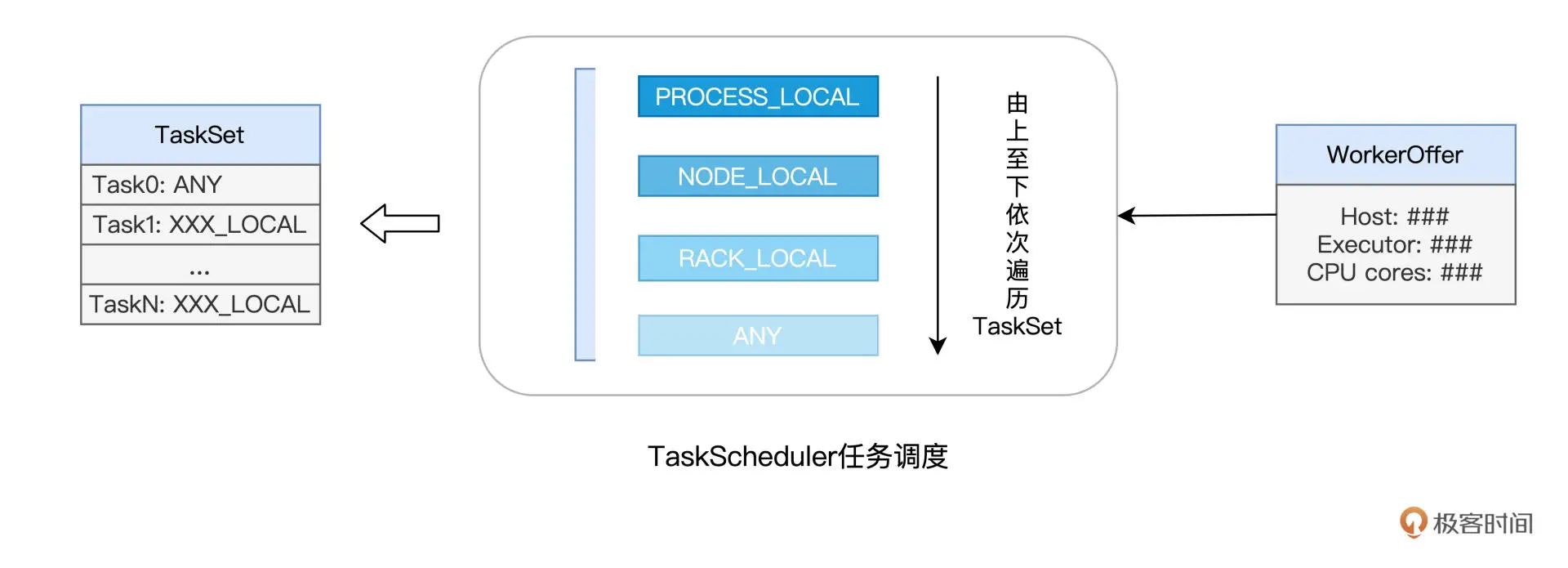
WorkerOffer 封装了 Executor ID、主机地址和 CPU 核数,它用来表示一份可用于调度任务的空闲资源。
对于给定的 WorkerOffer,TaskScheduler 是按照任务的本地倾向性,来遴选出 TaskSet 中适合调度的 Tasks。
像上面这种定向到计算节点粒度的本地性倾向,Spark 中的术语叫做 NODE_LOCAL。除了定向到节点,Task 还可以定向到进程(Executor)、机架、任意地址,它们对应的术语分别是 PROCESS_LOCAL、RACK_LOCAL 和 ANY。
对于倾向 PROCESS_LOCAL 的 Task 来说,它要求对应的数据分区在某个进程(Executor)中存有副本;而对于倾向 RACK_LOCAL 的 Task 来说,它仅要求相应的数据分区存在于同一机架即可。ANY 则等同于无定向,也就是 Task 对于分发的目的地没有倾向性,被调度到哪里都可以。
总结
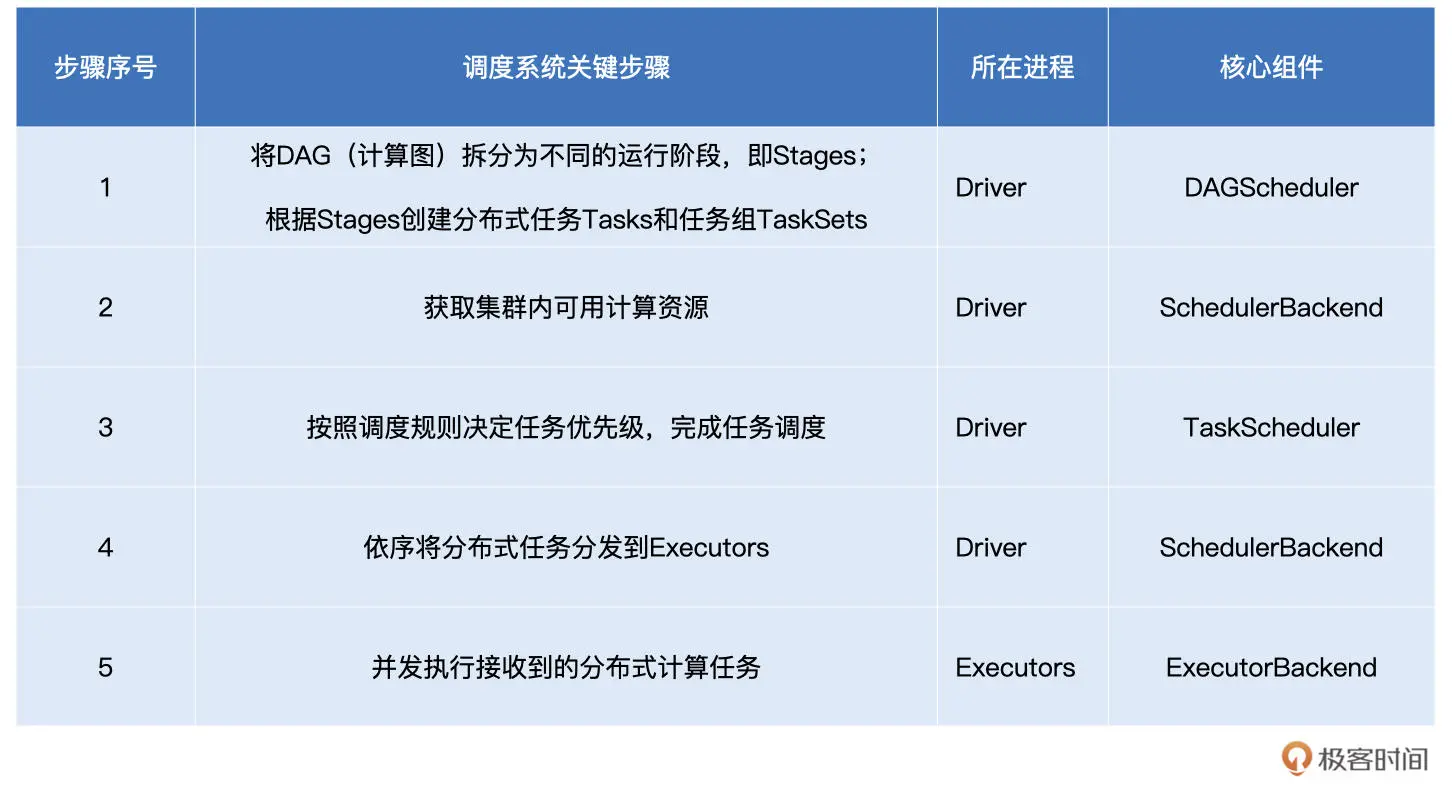
任务调度分为如下 5 个步骤:
- DAGScheduler 以 Shuffle 为边界,将开发者设计的计算图 DAG 拆分为多个执行阶段 Stages,然后为每个 Stage 创建任务集 TaskSet。
- SchedulerBackend 通过与 Executors 中的 ExecutorBackend 的交互来实时地获取集群中可用的计算资源,并将这些信息记录到 ExecutorDataMap 数据结构。
- 与此同时,SchedulerBackend 根据 ExecutorDataMap 中可用资源创建 WorkerOffer,以 WorkerOffer 为粒度提供计算资源。
- 对于给定 WorkerOffer,TaskScheduler 结合 TaskSet 中任务的本地性倾向,按照 PROCESS_LOCAL、NODE_LOCAL、RACK_LOCAL 和 ANY 的顺序,依次对 TaskSet 中的任务进行遍历,优先调度本地性倾向要求苛刻的 Task。
- 被选中的 Task 由 TaskScheduler 传递给 SchedulerBackend,再由 SchedulerBackend 分发到 Executors 中的 ExecutorBackend。Executors 接收到 Task 之后,即调用本地线程池来执行分布式任务。
- 一个job由action算子来触发,每个job又会根据shuffle情况划分出多个stage,每个stage中又会划分出多个task,再根据taskScheduler分配到各个Excecutor。
Shuffle
Shuffle 文件的生成,是以 Map Task 为粒度的,Map 阶段有多少个 Map Task,就会生成多少份 Shuffle 中间文件。
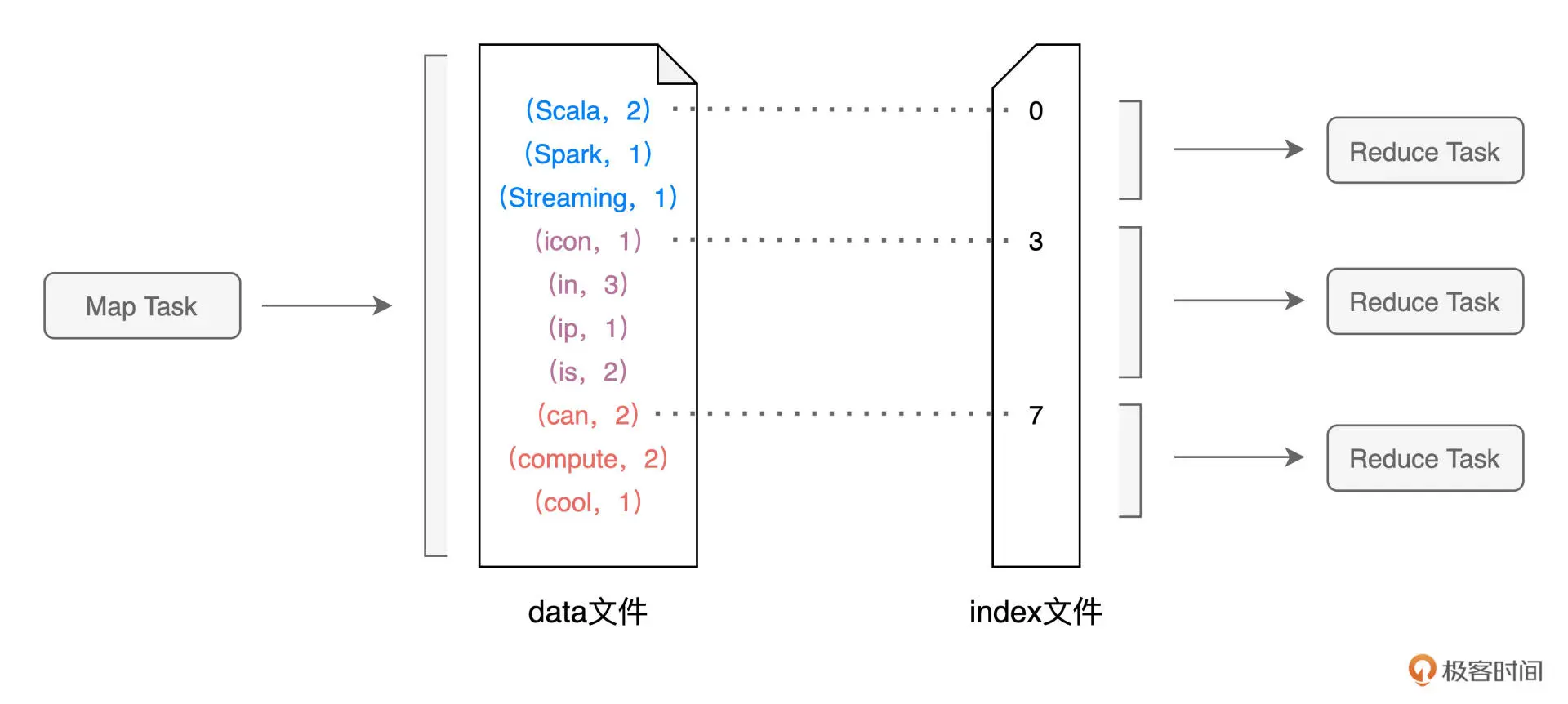
shuffle文件包括两个文件,**一个是记录(Key,Value)键值对的 data 文件,另一个是记录键值对所属 Reduce Task 的 index 文件。(典中典的列式存储)**换句话说,index 文件标记了 data 文件中的哪些记录,应该由下游 Reduce 阶段中的哪些 Task(简称 Reduce Task)消费。
假设 Reduce 阶段有 N 个 Task,这 N 个 Task 对应着 N 个数据分区,那么在 Map 阶段,每条记录应该分发到哪个 Reduce Task,是由下面的公式来决定的。
P = Hash(Record Key) % N
shuffle生成过程
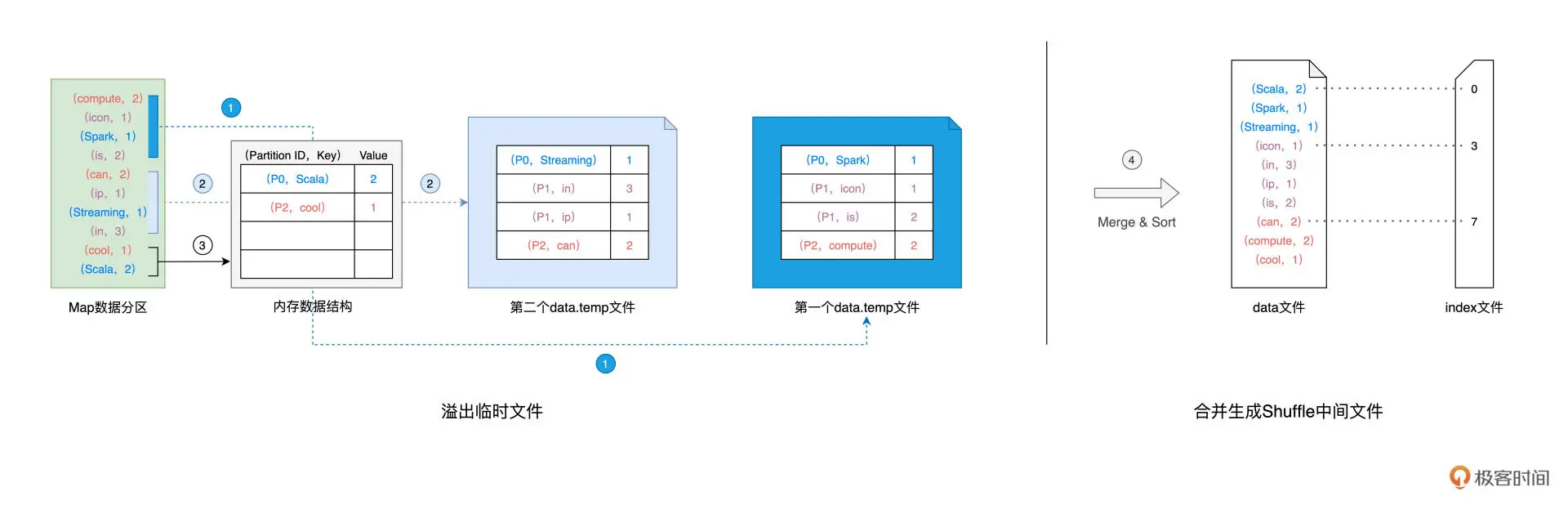
在生成中间文件的过程中,**Spark 会借助一种类似于 Map 的数据结构,来计算、缓存并排序数据分区中的数据记录。**这种 Map 结构的 Key 是(Reduce Task Partition ID,Record Key),而 Value 是原数据记录中的数据值,如图中的“内存数据结构”所示。
对于数据分区中的数据记录,Spark 会根据我们前面提到的公式 1 逐条计算记录所属的目标分区 ID,然后把主键(Reduce Task Partition ID,Record Key)和记录的数据值插入到 Map 数据结构中。当 Map 结构被灌满之后,Spark 根据主键对 Map 中的数据记录做排序,然后把所有内容溢出到磁盘中的临时文件,如图中的步骤 1 所示。
随着 Map 结构被清空,Spark 可以继续读取分区内容并继续向 Map 结构中插入数据,直到 Map 结构再次被灌满而再次溢出,如图中的步骤 2 所示。就这样,如此往复,直到数据分区中所有的数据记录都被处理完毕。
到此为之,磁盘上存有若干个溢出的临时文件,而内存的 Map 结构中留有部分数据,Spark 使用归并排序算法对所有临时文件和 Map 结构剩余数据做合并,分别生成 data 文件、和与之对应的 index 文件,如图中步骤 4 所示。Shuffle 阶段生成中间文件的过程,又叫 Shuffle Write。
数据聚合
groupbykey的全量shuffle开销很大(不做map端聚合,只做reduce端聚合),因此普遍使用 reduceByKey、aggregateByKey 和 combineByKey而不是groupbykey。
- reduceByKey 在落盘与分发之前,会先在 Shuffle 的 Map 阶段做初步的聚合计算。在 Map 阶段,reduceByKey 把 Key 同为 Streaming 的两条数据记录聚合为一条,聚合逻辑就是由函数 f 定义的、取两者之间 Value 较大的数据记录,这个过程我们称之为“Map 端聚合”。相应地,数据经由网络分发之后,在 Reduce 阶段完成的计算,我们称之为“Reduce 端聚合”。reduceByKey 算子的局限性,在于其 Map 阶段与 Reduce 阶段的计算逻辑必须保持一致,这个计算逻辑统一由聚合函数 f 定义。当一种计算场景需要在两个阶段执行不同计算逻辑的时候,reduceByKey 就爱莫能助了。
- aggregateByKey可以自定义map和reduce端聚合,是更加灵活的聚合算子
内存管理和存储系统
Shuffle 中间文件消耗的是节点磁盘,而广播变量主要占用节点的内存空间,RDD Cache 则是“脚踏两条船”,既可以消耗内存,也可以消耗磁盘。
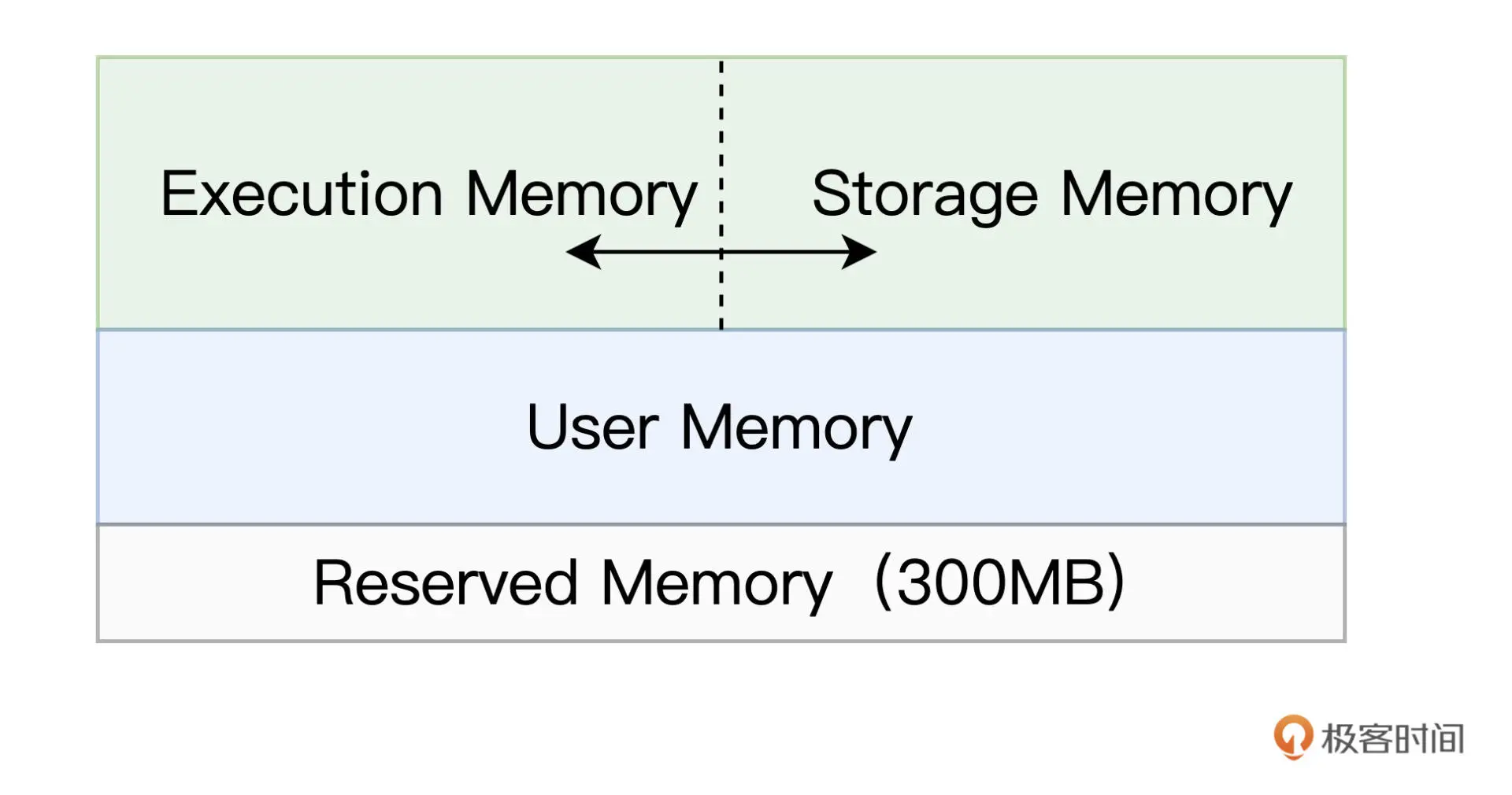
Execution Memory 用来执行分布式任务。分布式任务的计算,主要包括数据的转换、过滤、映射、排序、聚合、归并等环节,而这些计算环节的内存消耗,统统来自于 Execution Memory。
Storage Memory 用于缓存分布式数据集,比如 RDD Cache、广播变量等等。RDD Cache 指的是 RDD 物化到内存中的副本。在一个较长的 DAG 中,如果同一个 RDD 被引用多次,那么把这个 RDD 缓存到内存中,往往会大幅提升作业的执行性能。
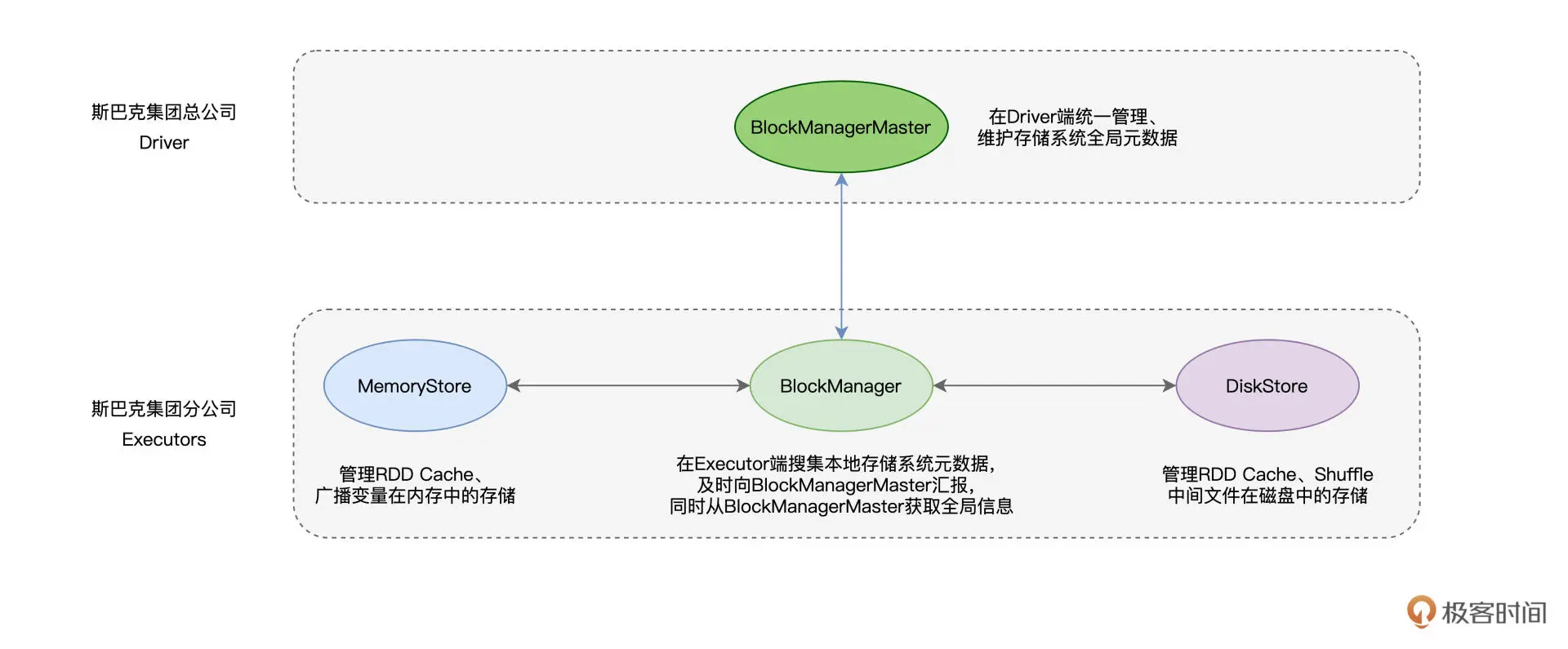
存储系统主要是由BlockManager模块负责:
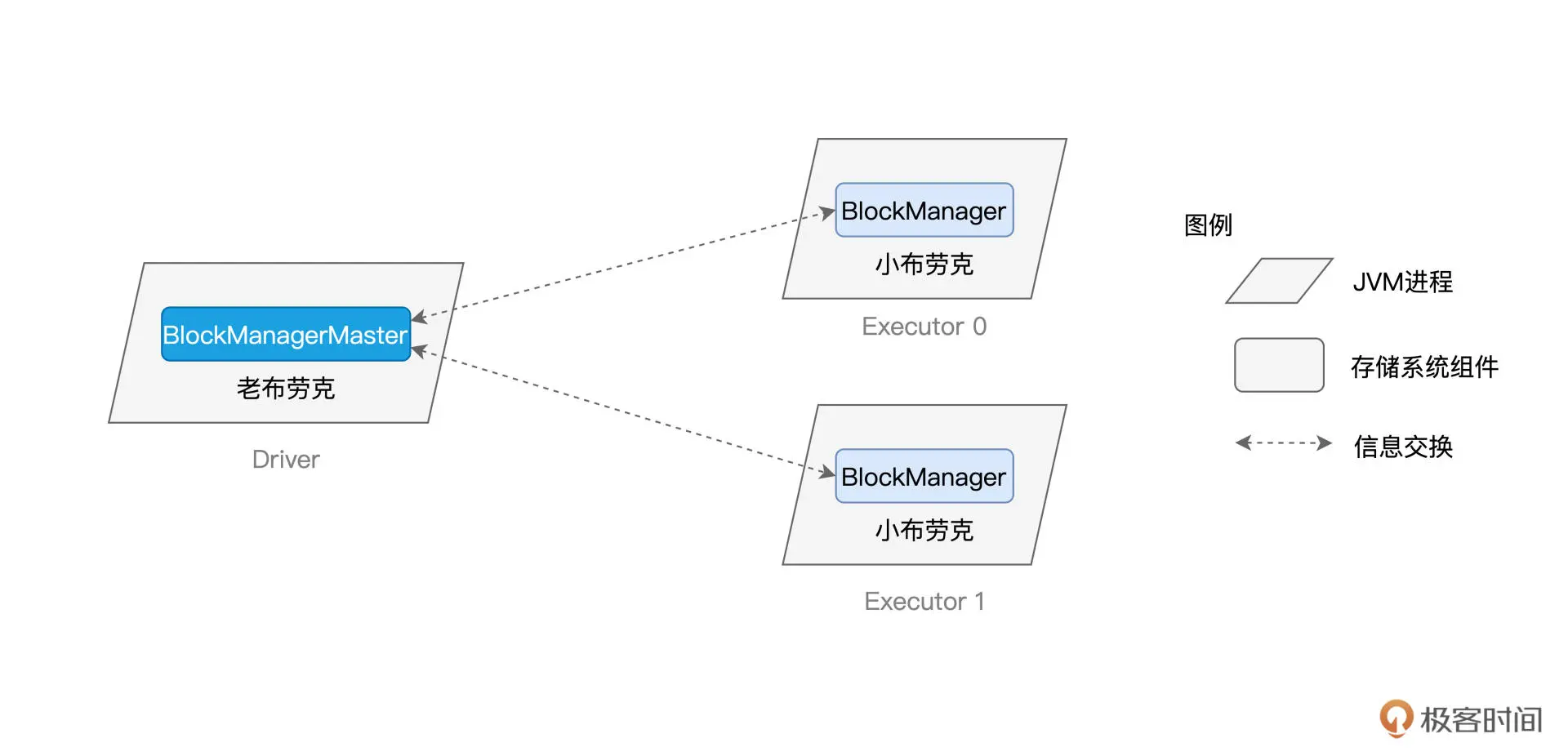
BlockManager 的核心职责,在于管理数据块的元数据(Meta data),这些元数据记录并维护数据块的地址、位置、尺寸以及状态。
Cache
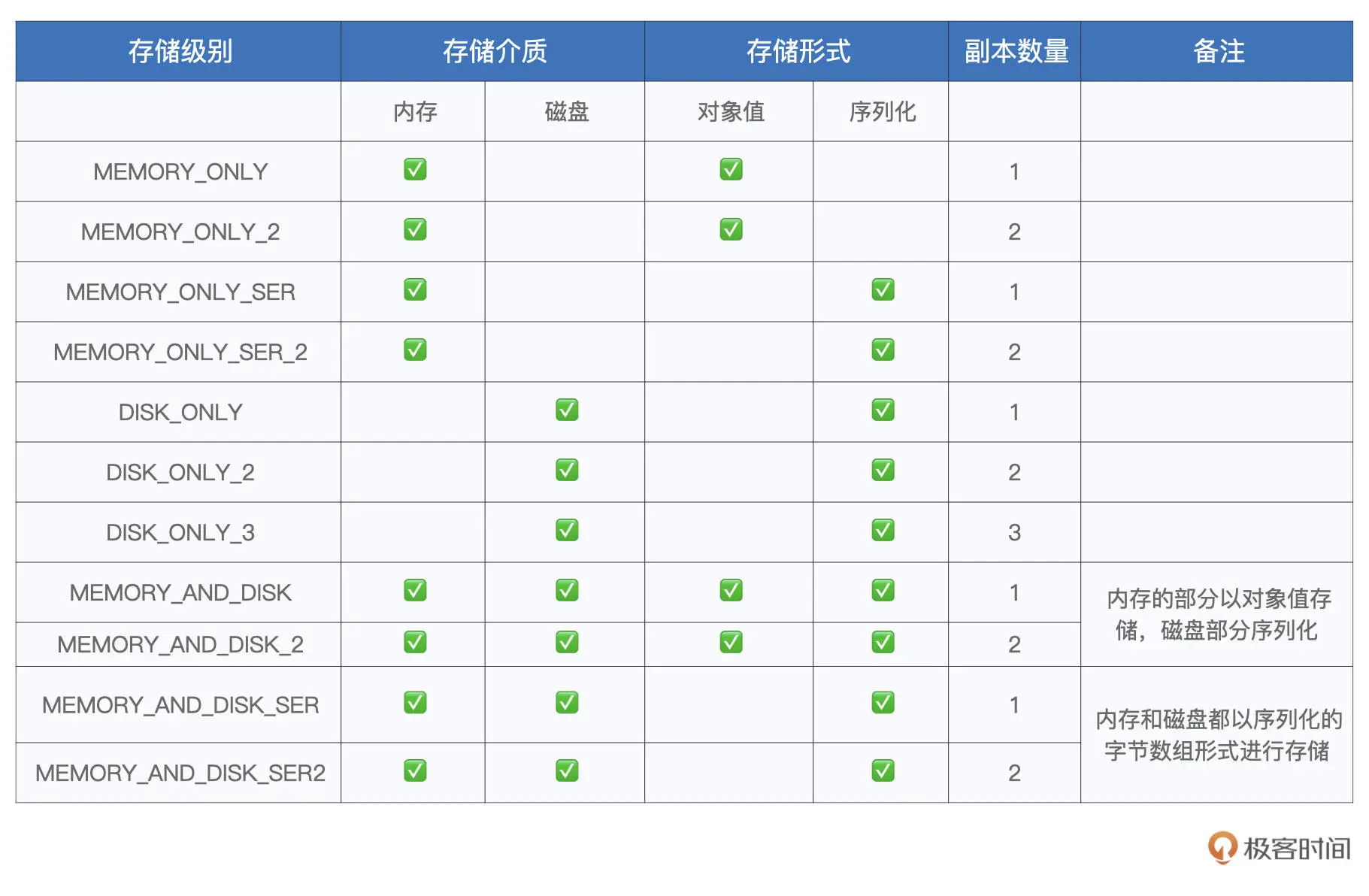
cache 函数实际上会进一步调用 persist(MEMORY_ONLY)来完成计算
数据的准备、重分配和持久化
这部分相关的算子如下:
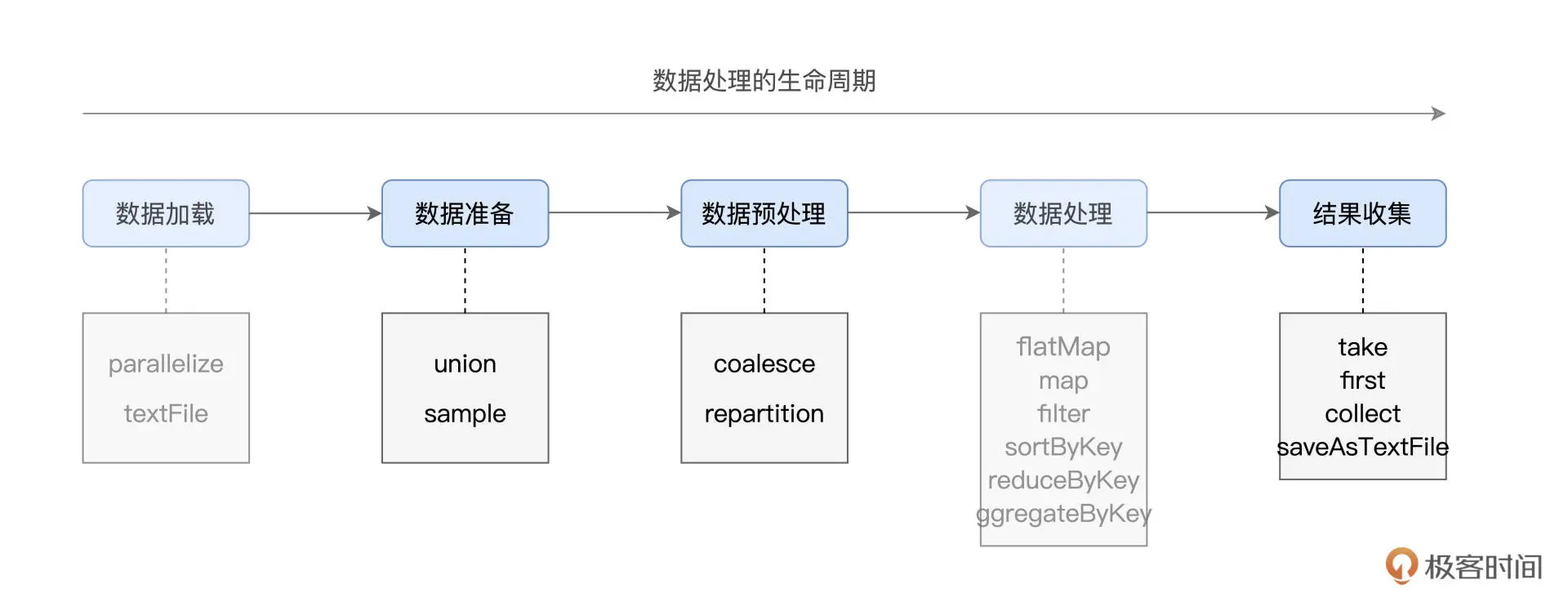
首先,在数据准备阶段,union 与 sample 用于对不同来源的数据进行合并与拆分。
我们从左往右接着看,接下来是数据预处理环节。较为均衡的数据分布,对后面数据处理阶段提升 CPU 利用率更有帮助,可以整体提升执行效率。那这种均衡要怎么实现呢?没错,这时就要 coalesce 与 repartition 登场了,它们的作用就是重新调整 RDD 数据分布。
在数据处理完毕、计算完成之后,我们自然要对计算结果进行收集。Spark 提供了两类结果收集算子,一类是像 take、first、collect 这样,把结果直接收集到 Driver 端;另一类则是直接将计算结果持久化到(分布式)文件系统,比如咱们这一讲会提到的 saveAsTextFile。
- RDD 的 sample 算子用于对 RDD 做随机采样,从而把一个较大的数据集变为一份“小数据”。相较其他算子,sample 的参数比较多,分别是 withReplacement、fraction 和 seed。因此,要在 RDD 之上完成数据采样,你需要使用如下的方式来调用 sample 算子:sample(withReplacement, fraction, seed)。
- 开发者可以使用 repartition 算子随意调整(提升或降低)RDD 的并行度,而 coalesce 算子则只能用于降低 RDD 并行度。repartition和coalesce相比较,repartition由于引入了shuffle机制,对数据进行打散,混洗,重新平均分配,所以repartition操作较重,但是数据分配均匀。而coalesce只是粗力度移动数据,没有平均分配的过程,会导致数据分布不均匀,在计算时出现数据倾斜。
广播变量和累加器
- 广播变量的分发不以task为粒度,而是以Executor为粒度,这样就减少了变量分发的开销
- 累加器用于存储全局变量
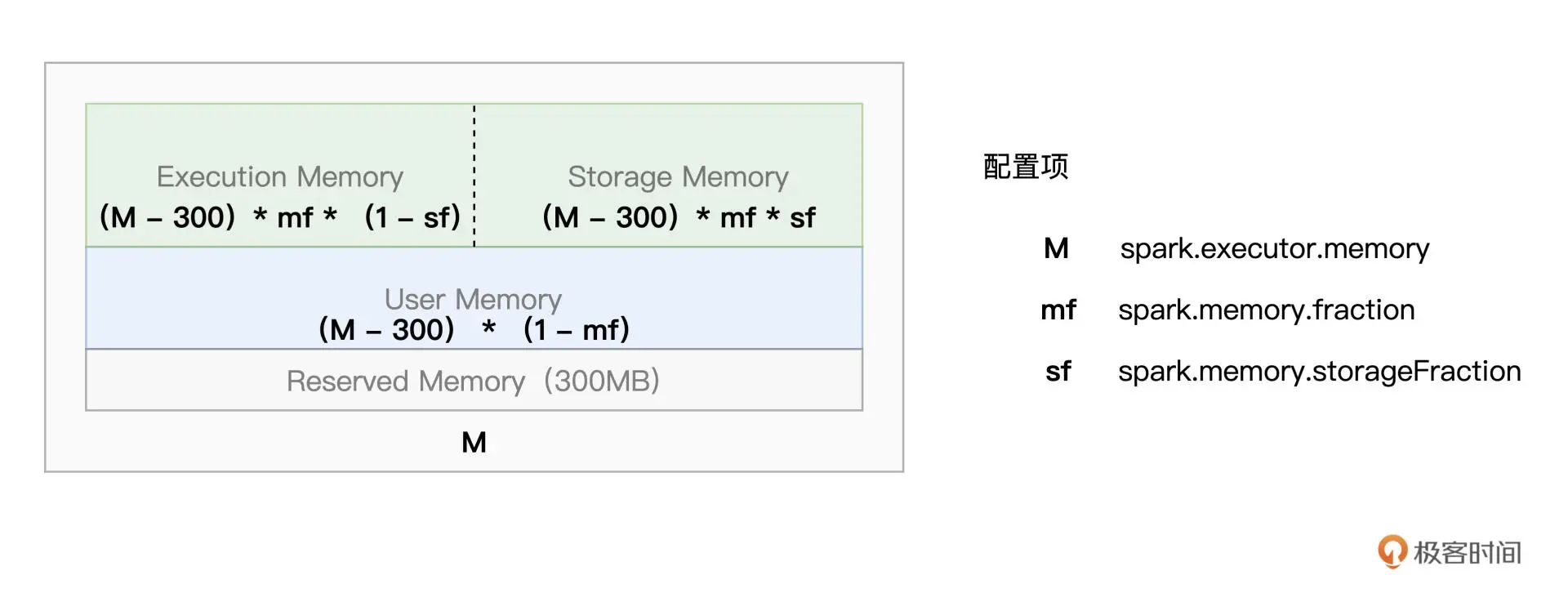
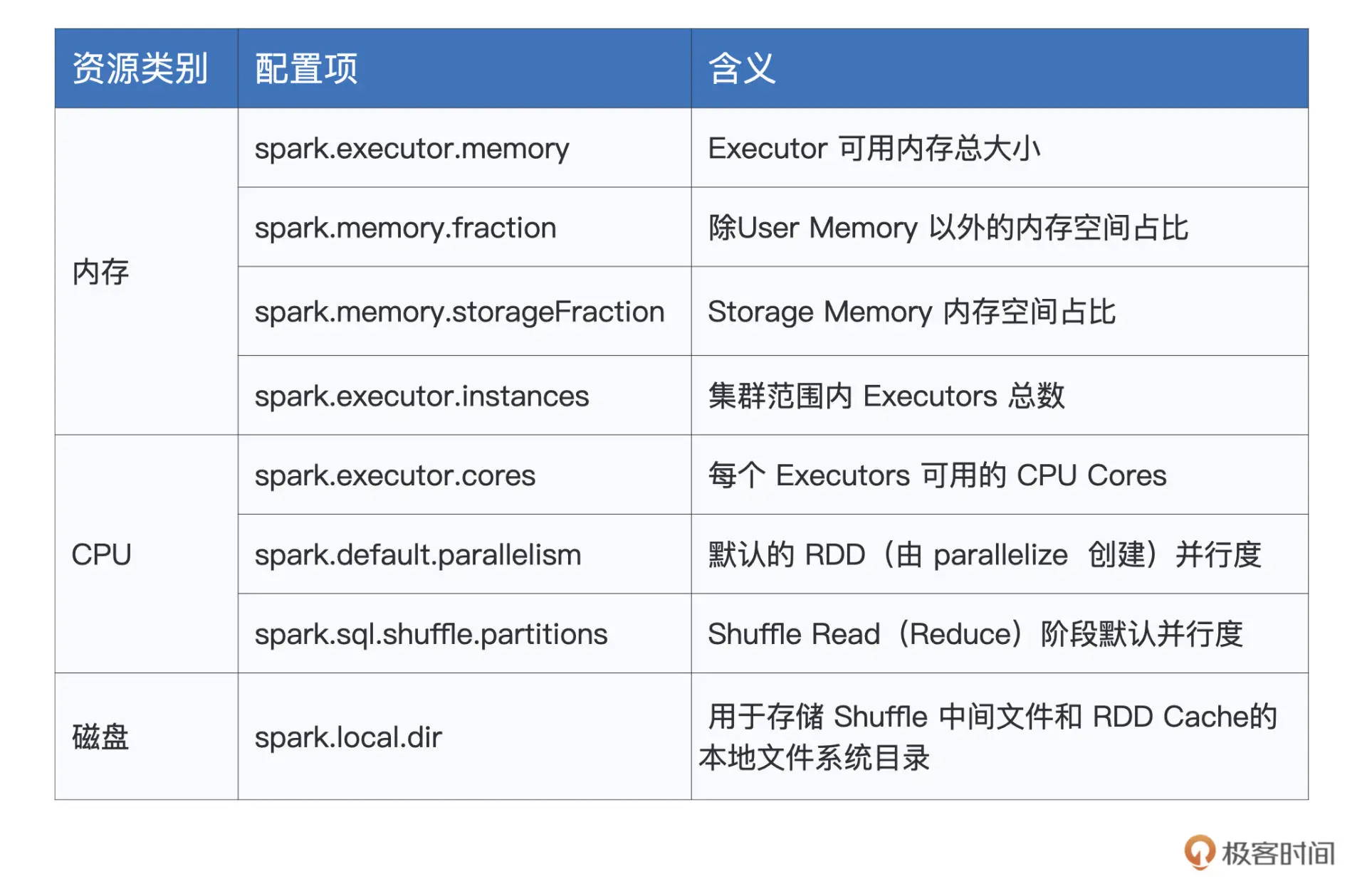
配置项
Catalyst
Catalyst 优化器,它的职责在于创建并优化执行计划,它包含 3 个功能模块,分别是创建语法树并生成执行计划、逻辑阶段优化和物理阶段优化。
在 Catalyst 优化环节,Spark SQL 首先把用户代码转换为 AST 语法树,又叫执行计划,然后分别通过逻辑优化和物理优化来调整执行计划。逻辑阶段的优化,主要通过先验的启发式经验,如谓词下推、列剪枝,对执行计划做优化调整。而物理阶段的优化,更多是利用统计信息,选择最佳的执行机制、或添加必要的计算节点。
Tungsten
Tungsten 用于衔接 Catalyst 执行计划与底层的 Spark Core 执行引擎,它主要负责优化数据结果与可执行代码。
Tungsten 设计并实现了一种叫做 Unsafe Row 的二进制数据结构。Unsafe Row 本质上是字节数组,它以极其紧凑的格式来存储 DataFrame 的每一条数据记录,大幅削减存储开销,从而提升数据的存储与访问效率。