BridgeTower
- 核心思想
- 子问题1:双塔架构的局限性
- 子问题2:不同层次的语义信息未被充分利用
- 子问题3:模型扩展性和泛化能力
核心思想
论文:https://arxiv.org/pdf/2206.08657.pdf
代码:https://github.com/microsoft/BridgeTower
问题陈述:假设你有一张照片和一个相关的问题,你想通过这张照片来回答这个问题。
传统方法就像是有两个专家,一个懂得看图片,另一个懂得读懂问题,但他们只能在完成各自分析后,通过一个简单的对讲机进行沟通。
这种方式可能导致一些细节和深层次的含义丢失,因为他们没有办法在分析过程中共享和讨论信息。
BridgeTower 提出的解决方案:BridgeTower就像是给这两个专家提供了一座有多层桥梁的大桥,每层桥梁都允许他们在分析的任何阶段共享观点和发现。
这意味着,如果看图片的专家在图片的某个角落发现了一个重要的线索,他可以立即通知读问题的专家,反之亦然。
这样,他们就能更深入、更全面地理解整个情况,共同给出更准确的答案。
子问题1:双塔架构的局限性
- 子解法1:引入桥接层(Bridge Layers)
- 之所以用桥接层,是因为在传统的双塔架构中,视觉和文本信息的整合通常仅发生在最后一层,这限制了模型利用预训练单模态编码器中各层丰富语义的能力。
- 桥接层能够在每一层跨模态编码器中建立起视觉和文本编码器顶层之间的直接联系,从而实现自下而上的有效对齐和融合。
- 例子:如果视觉编码器在图片中识别出一个“狗”的图像特征,而文本编码器分析的句子是“小狗正在跑”,桥接层可以帮助跨模态编码器更有效地将这两种信息结合起来,以更好地回答关于图片的问题。
两塔架构的分类与BridgeTower架构:
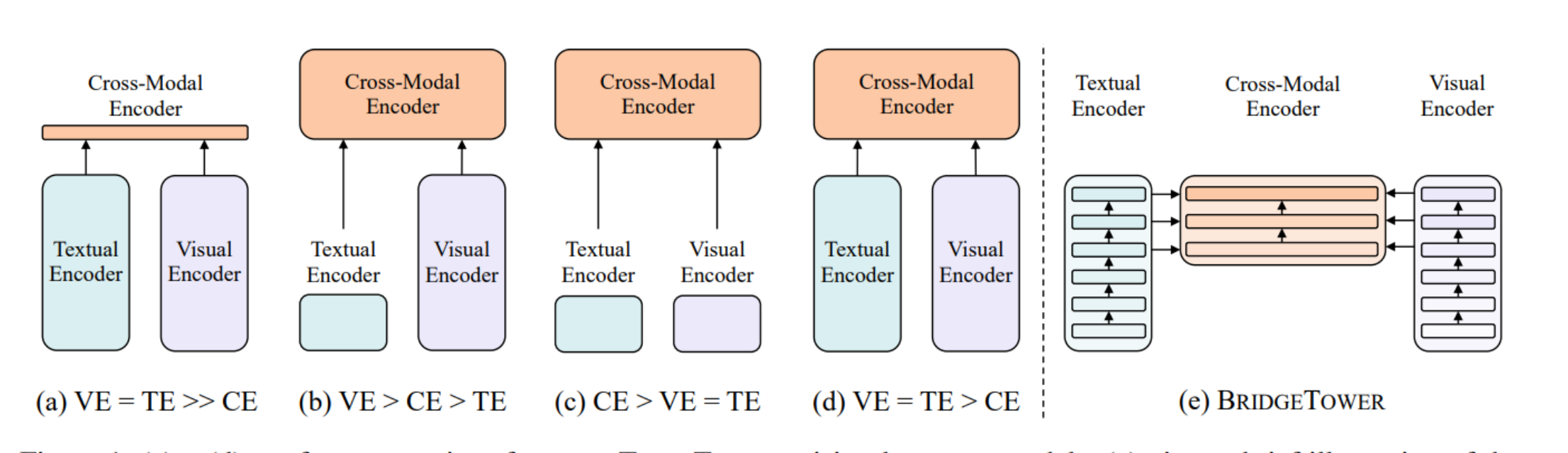
当前两塔VL模型的四种类别,以及BridgeTower架构的概念设计:
- (a) VE = TE >> CE: 表示视觉编码器(VE)和文本编码器(TE)具有相同或相似的参数或计算成本,远大于跨模态编码器(CE)。
- (b) VE > CE > TE: 表示视觉编码器的计算成本大于跨模态编码器,后者又大于文本编码器。
- © CE > VE = TE: 表示跨模态编码器的计算成本最高,视觉和文本编码器相同且低于CE。
- (d) VE = TE > CE: 表示视觉和文本编码器的计算成本相同且高于跨模态编码器。
- (e) BRIDGETOWER: 这是BridgeTower的架构,其中包含了视觉编码器、文本编码器和跨模态编码器。
- 与之前的模型不同,BridgeTower在每一层跨模态编码器中都引入了桥接层,将视觉和文本编码器的顶层与跨模态编码器的每一层相连接。
BridgeTower由一个12层的文本编码器、一个12层的视觉编码器以及6层的跨模态编码器组成,其中每一层的跨模态编码器都通过桥接层与文本和视觉编码器的顶层相连,以促进不同层次的语义信息融合。
子问题2:不同层次的语义信息未被充分利用
- 子解法2:多层特征利用(Multi-Layer Feature Utilization)
- 之所以采用多层特征利用,是因为不同的编码器层次编码了不同类型和层次的信息。
- 低层次可能更关注细节特征,如边缘和纹理,而高层次则包含更抽象的语义信息。
- 通过在桥接层中整合这些多层次的信息,可以让模型在理解复杂视觉-语言交互时有更全面的信息基础。
- 例子:考虑到一个复杂的图文匹配任务,如果仅仅使用高层的抽象信息可能难以捕捉到图片中的细节,如图片背景中的特定物体,而这些细节可能对匹配任务至关重要。
- 利用多层特征可以使模型在高层的语义理解和低层的细节观察之间找到平衡。
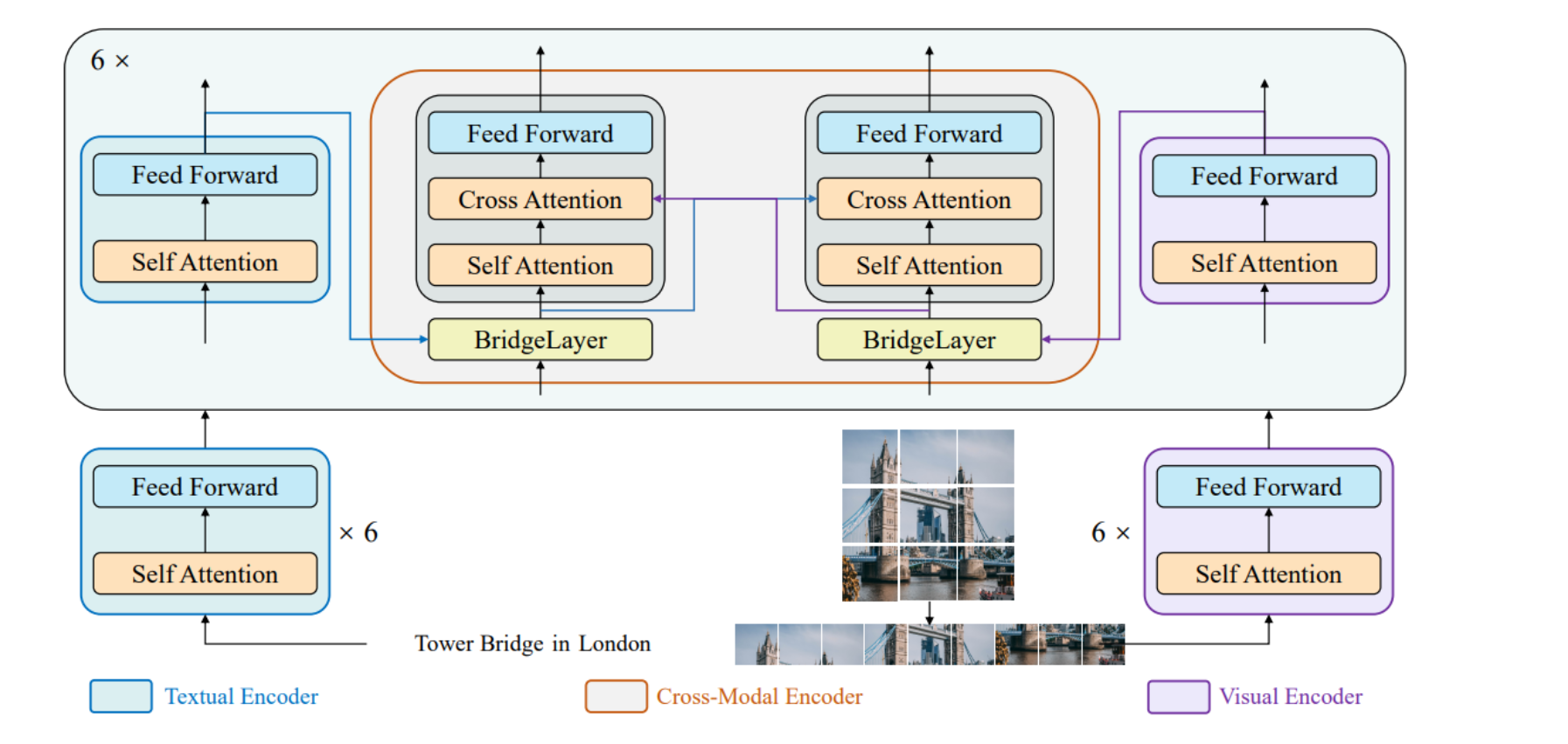
上图 BridgeTower模型的内部结构,展示了如何通过桥接层连接不同编码器的层。
- 文本编码器(Textual Encoder): 由6个自注意力和前馈网络组成的层堆叠而成,处理文本信息。
- 视觉编码器(Visual Encoder): 结构与文本编码器相似,但处理视觉信息。
- 跨模态编码器(Cross-Modal Encoder): 包含6层,每层都使用自注意力、交叉注意力和前馈网络。每层都通过一个桥接层与视觉和文本编码器的相应层相连接。
- 桥接层(BridgeLayer): 这是BridgeTower的核心创新,允许从视觉和文本编码器流向跨模态编码器的信息在不同层间流动,使得不同层的信息能够在跨模态编码器中进行融合。
总的来说,这两幅图展示了BridgeTower如何通过在传统的两塔VL模型中引入桥接层来提高模型性能,特别是如何促进视觉和文本信息在多个层次上的对齐和融合。
这种结构设计旨在解决先前模型中存在的信息利用不足的问题,并允许模型更全面地学习和理解跨模态内容。
子问题3:模型扩展性和泛化能力
- 子解法3:模型扩展和细化训练(Model Scaling and Fine-tuning)
- 之所以进行模型扩展和细化训练,是因为虽然BRIDGETOWER在初始的4M图像预训练集上表现出色,但要在更广泛的应用场景中保持高性能,需要模型具有良好的扩展性和泛化能力。
- 通过扩大模型规模和在特定下游任务上进行细化训练,可以进一步提升模型的准确性和适应性。
- 例子:当BRIDGETOWER模型从基础版扩展到大型版时,其在视觉问题回答任务上的准确率从78.73%提高到了81.15%,显示了通过增加模型复杂度和针对性训练可以有效提升性能。
通过这种方式,BRIDGETOWER项目不仅解决了双塔架构的核心问题,还通过具体的子解法充分利用了不同层次的语义信息,并确保了模型在不同规模和任务上的高性能和适应性。




Nginx、RPC、JWT)

)


)









