概述:
CDN服务平台上有为客户提供访问日志下载的功能,主要是为了满足在给CDN客户提供服务的过程中,要对所有的记录访问日志,按照客户定制的格式化需求以小时为粒度(或者其他任意时间粒度)进行排序、压缩、打包,供客户进行下载,以便进行后续的核对和分析的诉求。而且CDN上的访问日志一般都非常大,需要用大数据处理架构来进行处理,本文描述了一种利用hadoop+spark来处理大量CDN日志的方法,当然本方案不局限于CDN日志处理,完全可以应用到其他日志处理的应用需求上面。
本方案是一种对大数据量的日志进行打包处理的优化方法。首先,可以充分利用HDFS+SPARK大数据系统的分布式处理能力,让整个系统尽可能地连续进行工作,来处理实时上传上来的大量应用服务日志,而不至于因为业务规定的打包粒度的要求而等到一个相对较大的时间粒度(譬如1小时或者1天)的开始之后才能对日志进行处理,从而大幅度提升的日志处理的及时性和处理的效率;其次,采用本方案的方法,因为采用了比业务需求规定的更细的粒度对日志文件进行处理,一旦发现某个时间点的日志处理有问题,可以精确定位到那个时间点(1分钟级)的文件,进行细粒度追溯和回滚处理,避免在大粒度上面进行处理,大幅度减少了需要追溯或回滚的数据的处理量,提升了系统的可维护性;最后,利用HDFS+SPARK大数据系统处理平台的弹性架构,能够为整个日志处理系统提供长期的弹性扩容能力,满足未来长期运行的需求。
实现说明:
以下对具体实现方式进行说明。
首先,先描述一下整个日志打包系统的部署架构,如下图:
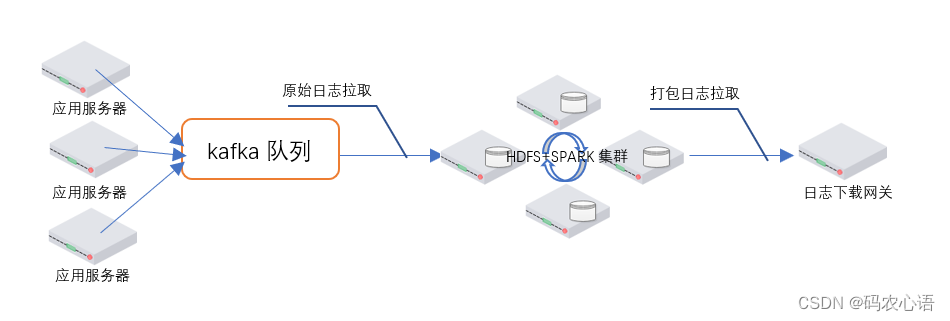
- 图的左侧,多个应用服务器在应用服务系统运行的过程中,在不断的产生各种日志,通过一些实时采集工具将应用服务器的日志发送到异步队列kafka 中(这个环节的内容不是本方案的重点)。
- 图的中间,HDFS+SPARK集群进行分布式运算,来进行日志文件的格式化、排序、压缩、打包操作,最终生成打包好的分片(譬如以1分钟为粒度)日志文件存储到HDFS的指定目录中。
- 图的右侧,日志下载网关为查看和下载日志的用户提供虚拟视图,按照业务所要求的更大的时间粒度(譬如1小时或者1天粒度)提供日志的查看和下载。
下面,对HDFS+SPARK集群进行日志的处理过程进行详细描述:
由于存在众多的应用服务器&#x












——联合)





)
