最近完成了1个爬虫项目,记录一下自己的心得。
项目功能简介
根据用户输入商品名称、类别名称,使用Selenium, BS4等技术每天定时抓取亚马逊商品数据,使用Pandas进行数据清洗后保存在MySql数据库中.
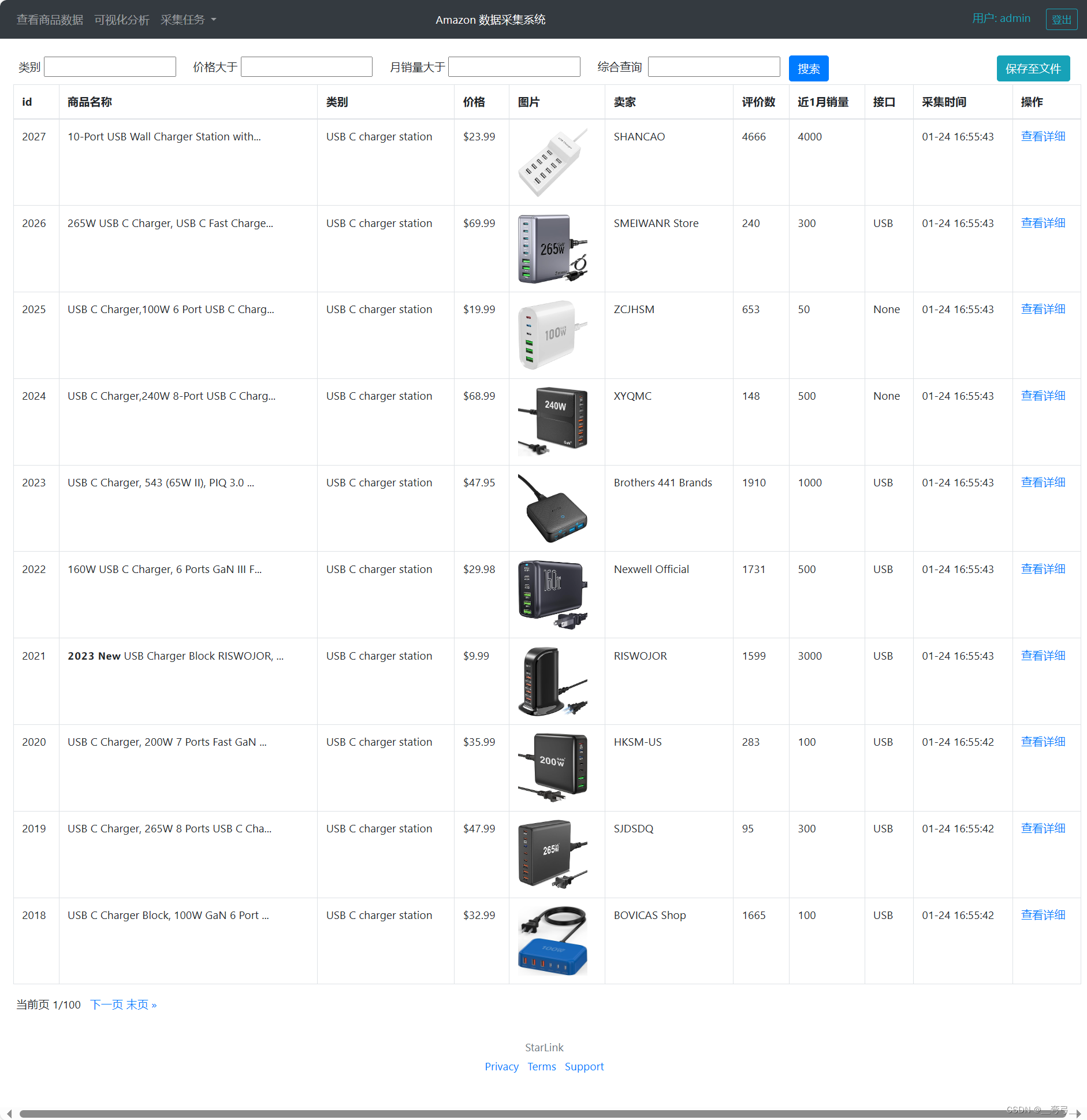
使用Django提供用户端功能,显示商品数据,以可视化的方式分析数据,以及数据抓取任务管理等。
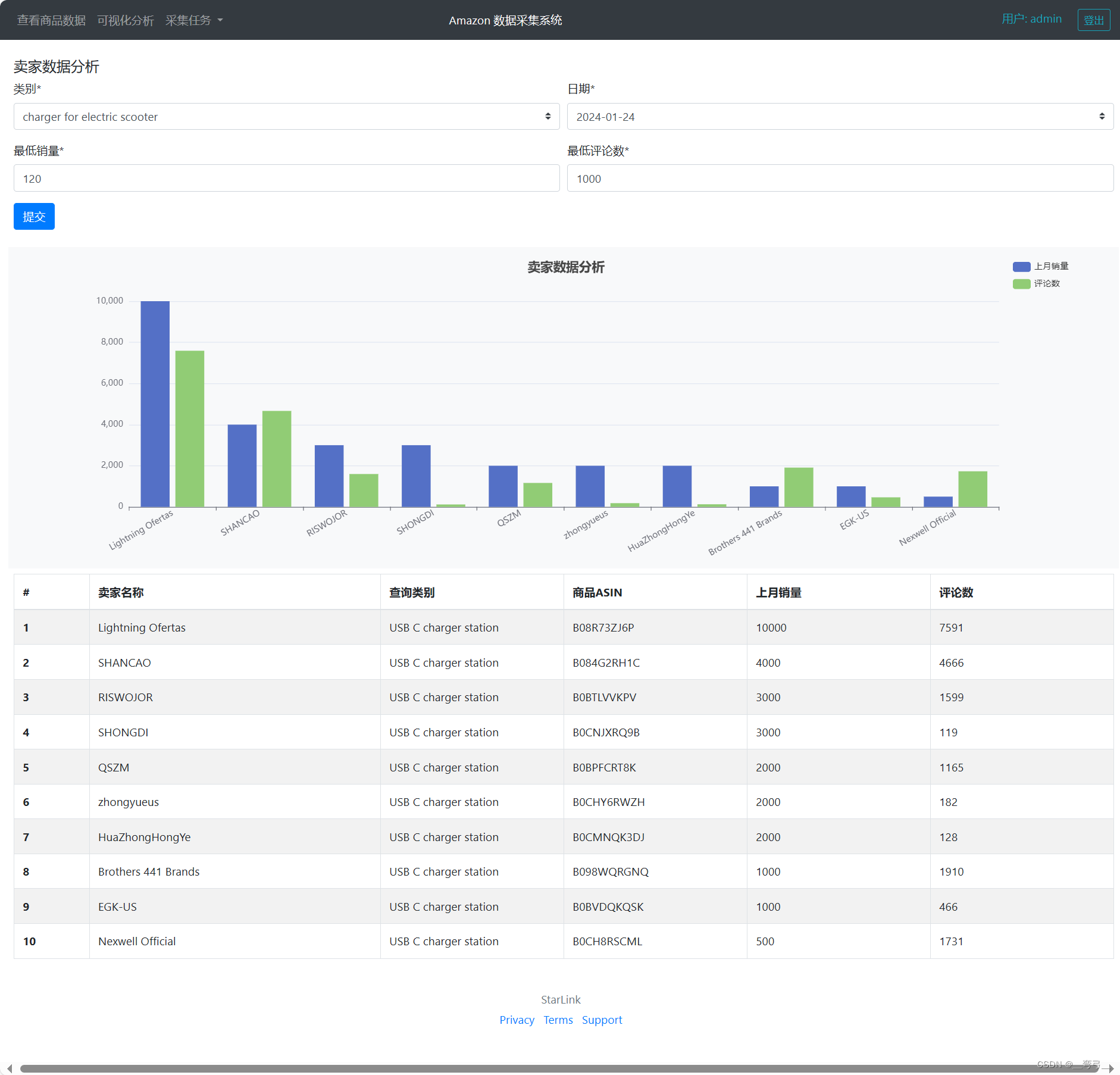
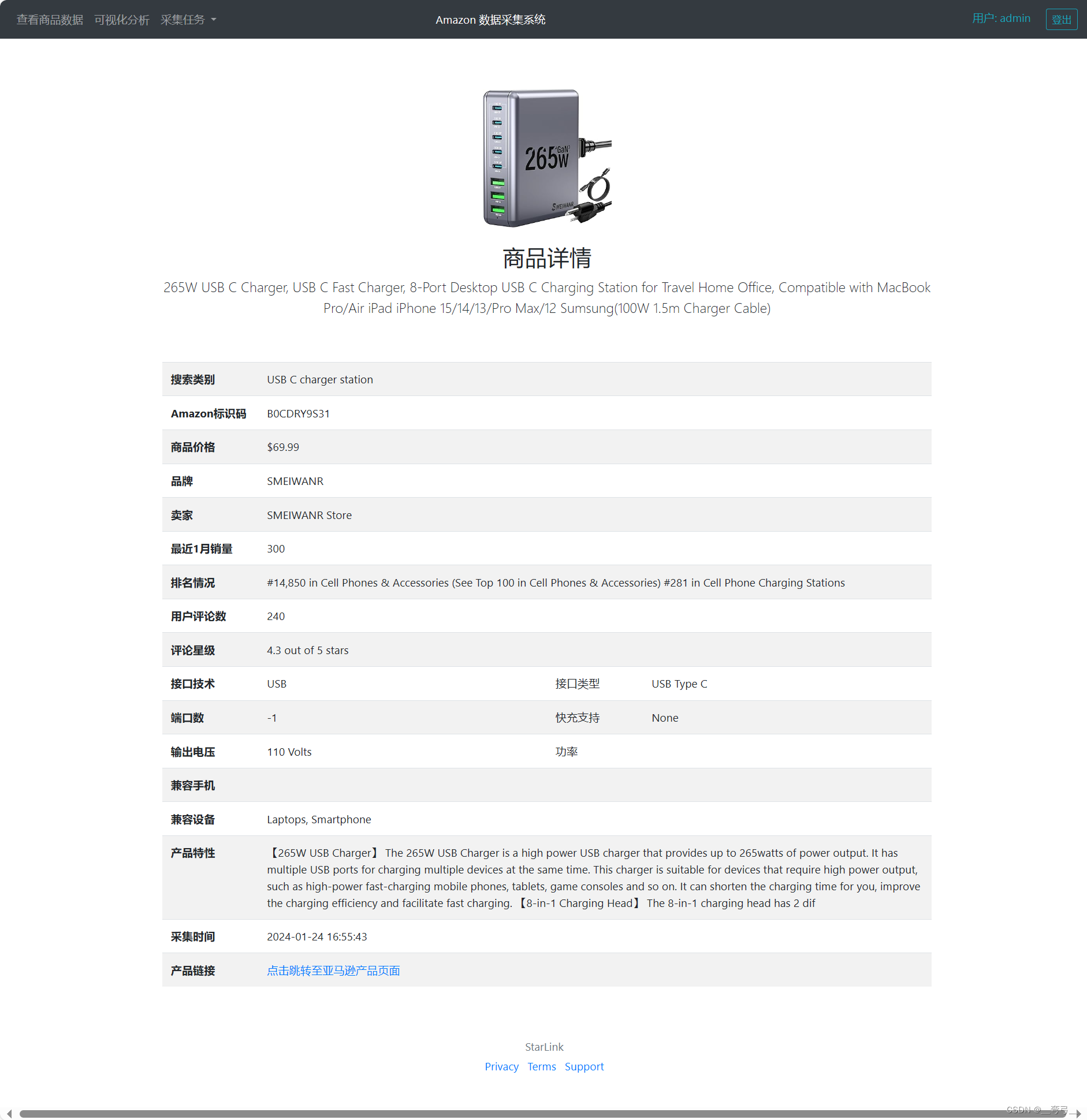
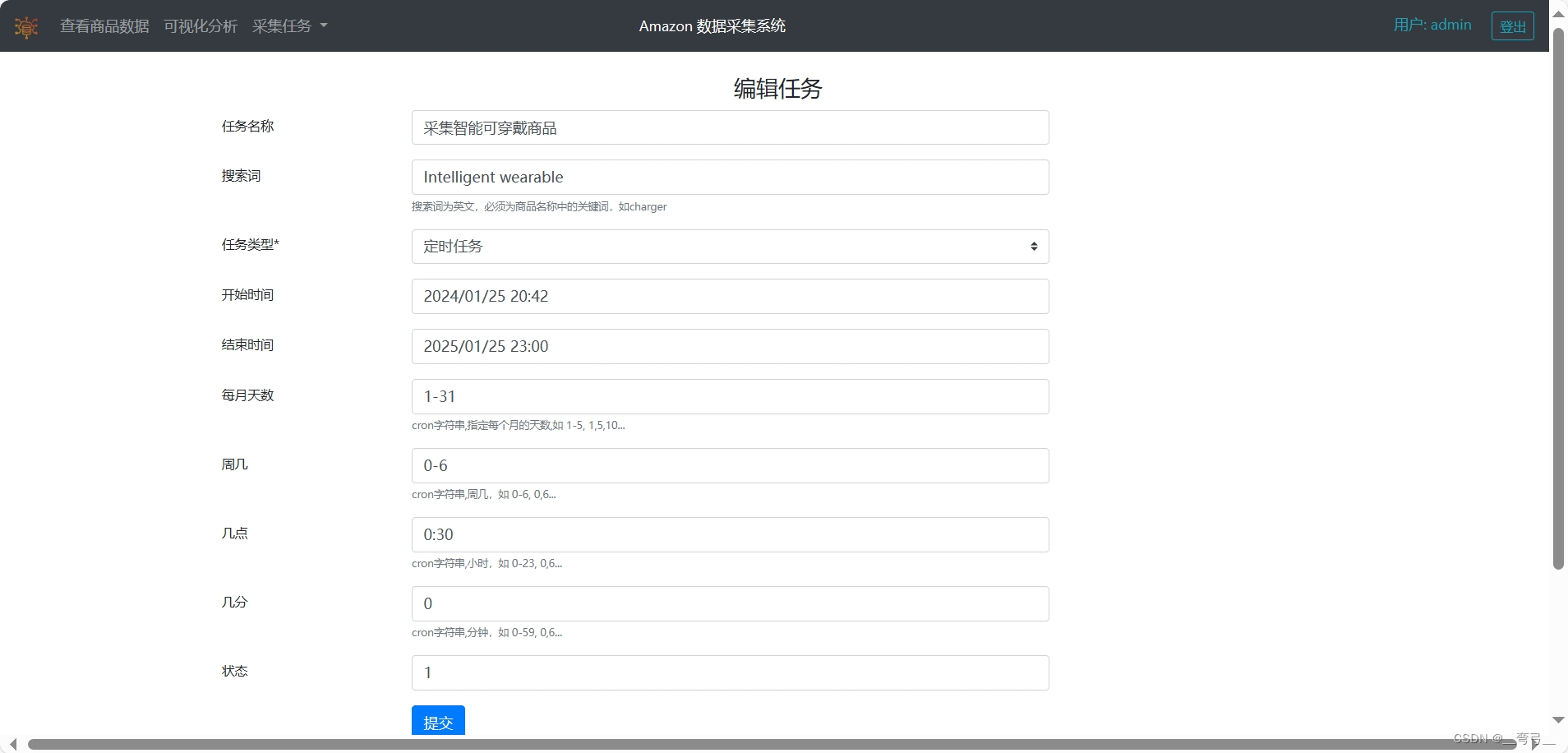
项目技术难点:
1)亚马逊Anti-scrape 措施较多,主要是各类验证码,解决起来也不算复杂。但页面元素分析,javascript分析的工作量占据了大部分时间。
2)性能优化,执行任务采用多进程运行,每个进程中再使用异步方式同时发起多个请求,下载图片、保存数据库均为异步执行,以保证较高性能。
3)由于大部分页面需要通过selenium完成操作,无法采用scrapy框架,所以自己编写任务管理器,提供1次性任务、间隔任务、定时任务的管理、执行、监控等,以及通过回调函数来清洗数据。
4)Django模板中添加 Echarts Javascript 脚本进行图表绘制。由于时间短,未使用Vue方式,不过Django 模板 + Bootstrap 也基本满足了需求。
5)保持项目的扩展性:通过爬虫任务管理器满足用户的各类搜索需求。数据库分为原始数据以及清洗数据,中间的cleaning类可以随时扩展,
6)通用绘图接口功能: 由于绘图是通过模板中的javascript脚本完成,计划另写1套通用接口,将数据、绘图类型以参数方式传入,再向django 模板插入echarts绘图脚本,
合作说明
亚马孙的商品页面依据类别、用户所在地、收货地等不同而有所不同,但毕竟是大公司产品,其页面组织是规范的,因此本项目也很容易扩展。 如有对亚马逊数据分析的合作需求,留私信留言。

全程指南)















窗)
)
错误【已解决】)
