作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
学习必须往深处挖,挖的越深,基础越扎实!
阶段1、深入多线程
阶段2、深入多线程设计模式
阶段3、深入juc源码解析
阶段4、深入jdk其余源码解析
阶段5、深入jvm源码解析
事务的难点在哪?
之前分享过一个观点,设计模式最难的不是代码、也不是设计思想,而是如何准确判断每种设计模式的使用时机。一些人可能对23种设计模式如数家珍、倒背如流,却常常在阴沟里翻船,不知不觉就用了各种if else到处打补丁。
同理,事务本身其实也不难,无论本地事务还是分布式事务,业界都有成熟的解决方案。事务最大的问题也在使用时机:
人们往往不知道此处需要事务
佣金错误案例
日常开发时,我们很容易写出下面的代码:
@Transactional(rollbackFor = Exception.class)
public void execute() {updateUserPoint();updateUserLevel();
}由于用户积分和用户等级需要满足“要么同时成功,要么同时失败”的特性,所以加上了@Transactional保证事务。很多人都十分清楚@Transactional什么情况下会失效,但事务往往总在你意想不到的地方失效。
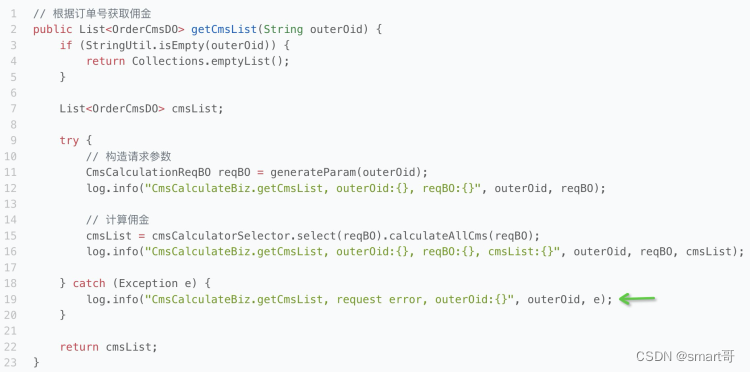
请大家观察下面这段代码,看看有什么问题(代码做了适当简化):
// 根据订单号获取佣金
public List<OrderCmsDO> getCmsList(String outerOid) {if (StringUtil.isEmpty(outerOid)) {return Collections.emptyList();}List<OrderCmsDO> cmsList;try {// 构造请求参数CmsCalculationReqBO reqBO = generateParam(outerOid);log.info("CmsCalculateBiz.getCmsList, outerOid:{}, reqBO:{}", outerOid, reqBO);// 计算佣金cmsList = cmsCalculatorSelector.select(reqBO).calculateAllCms(reqBO);log.info("CmsCalculateBiz.getCmsList, outerOid:{}, reqBO:{}, cmsList:{}", outerOid, reqBO, cmsList);} catch (Exception e) {log.info("CmsCalculateBiz.getCmsList, request error, outerOid:{}", outerOid, e);}return cmsList;
}// 计算佣金(每计算一种类型的cms,就往cmsList中add)
public List<OrderCmsDO> calculateAllCms(CmsCalculationReqBO reqBO) {// ...CmsCalculateContextBO contextBO = generateCmsContextBO(reqBO);/*** 注意:以下执行顺序不能改变!!!!!** 计算V0 分享奖励* 计算V1 自售或者分享奖励* 计算V2 平台补贴* 计算V2 自售补贴* 计算V2 自售或者分享奖励* 计算V2 星火奖励* 计算V3 平台补贴* 计算V3 自售补贴* 计算V3 自售或者分享奖励* 计算V3 星火奖励*/calculateV0Profit(reqBO, contextBO);calculateV1Profit(reqBO, contextBO);calculateV2SubsidyProfit(reqBO, contextBO);calculateV2Profit(reqBO, contextBO);calculateV2Spark(reqBO, contextBO);calculateV3SubsidyProfit(reqBO, contextBO);calculateV3Profit(reqBO, contextBO);calculateV3Spark(reqBO, contextBO);return contextBO.getCmsList();
}大致逻辑是:
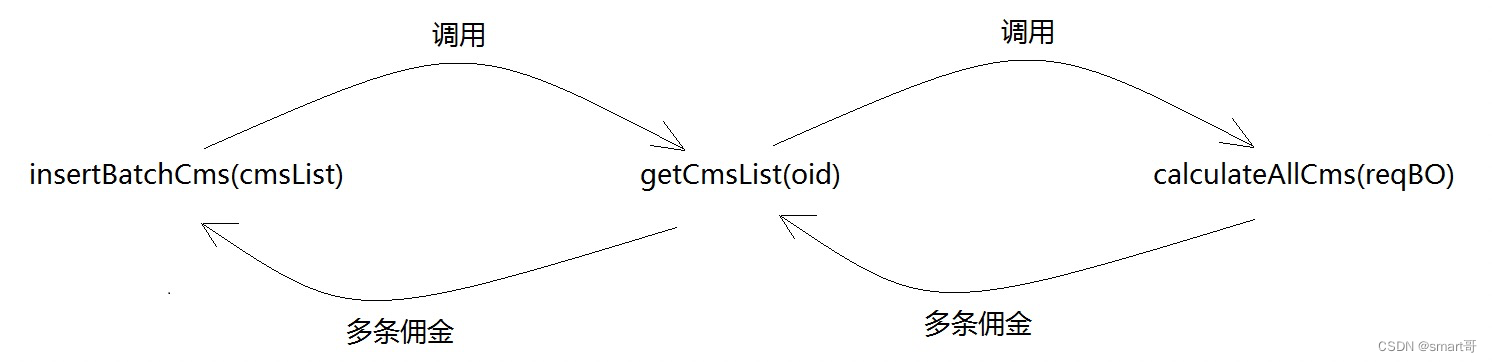
上游方法依赖getCmsList(),然后批量插入用户下单所得佣金,具体佣金计算逻辑在calculateAllCms()。一个用户下单所得佣金比较复杂,最终返回的cmsList类似这种:
[{"bizId": "xxx","cmsAmt": 1,"cmsDesc": "V2平台补贴","outerOid": "xxx","uid": 10086},{"bizId": "xxx","cmsAmt": 15,"cmsDesc": "V2分享奖励","outerOid": "xxx","uid": 10086},{// 本订单其他类型佣金...}
]一个用户,它的佣金假设有A、B、C三种类型,要么同时插入3种佣金,要么都不插入(后期有问题直接重跑即可),最怕的就是那种只插入一半的情况,修复很麻烦(需要删除原有的,甚至还要回滚由佣金引发的一系列操作)。
而上面的代码,就可能导致部分佣金写入的问题:
假设calculateAllCms()中需要计算3类佣金,A、B都没问题,C类佣金计算失败抛异常,那么就会进入上面的catch代码块。然而,此时cmsList中已经有A、B类佣金,代码继续往下走,就会return cmsList,返回了不完整的佣金列表,最终数据库插入的就是不完整的佣金(缺少C类佣金)。
catch里面可以直接返回emptyList,不插入总比插入不完整的好,后面再补就是了。
小结
分布式应用中也很容易因为疏忽导致数据不一致,比如我们往往会引入Manager层,为的是对其他Service的API接口做一层封装:
@Slf4j
@Component
public class MemberServiceManager {@Resourceprivate MemberDirectRecordService memberDirectRecordService;'public MemberDirectRecordTO getDirectRecord(Long uid) {if (Validator.isNotId(uid)) {return null;}try {ServiceResultTO<MemberDirectRecordTO> resultTO =memberDirectRecordService.getDirectRecord(uid);if (Validator.isNullOrEmpty(resultTO) || Validator.isFalse(resultTO.getSuccess())) {return null;}return resultTO.getData();} catch (Exception e) {log.error("getDirectRecord, error, uid:{}", uid, e);}return null;}}上面这种写法,由于异常被吞了,调用者往往很难区分到底是远程调用超时导致null,还是接口查询本身为null。如果调用者的逻辑是:
if(result不为null){ // 本意是不为null进行一些操作do something;
}但如果这个“null”仅仅是因为RPC远程调用失败导致的,而不是对应的数据真的为null,本次操作就会被遗漏,效果和上面的佣金计算是一样的。
这些,其实都是事务范畴,try catch处理不当,容易导致问题被忽略,最终发生数据不一致的问题。

















)

