随着假期的临近,我期待着变得舒适,拿起一本新书,享受轻松的时光。
但是使用搜索栏在线发现图书并不像看起来那么容易......大多数零售搜索引擎仅依赖于关键字搜索,当我们确切地知道我们正在寻找什么书名时,这很好,但当我们确切地知道我们正在寻找什么标题时,它就变得更具挑战性。 我们对主题只有一个模糊的概念。
因此,在这篇简短的文章中,我决定探索如何利用 Elasticsearch 对语义搜索的支持来帮助那些想要查找有关圣诞节的书籍的人……而无需使用 “圣诞节 (Christmas)”一词。
对于我们的示例,我们将使用包含书籍摘要的数据集。 接下来,您需要启动一个 Elasticsearch 集群并运行已下载的 ELSER 模型 2、
首先,我们配置一个摄取管道来为每本书概要生成稀疏向量。在本次展示中,我将采用最新的 Elastic Stack 8.11 来进行展示。
安装
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:

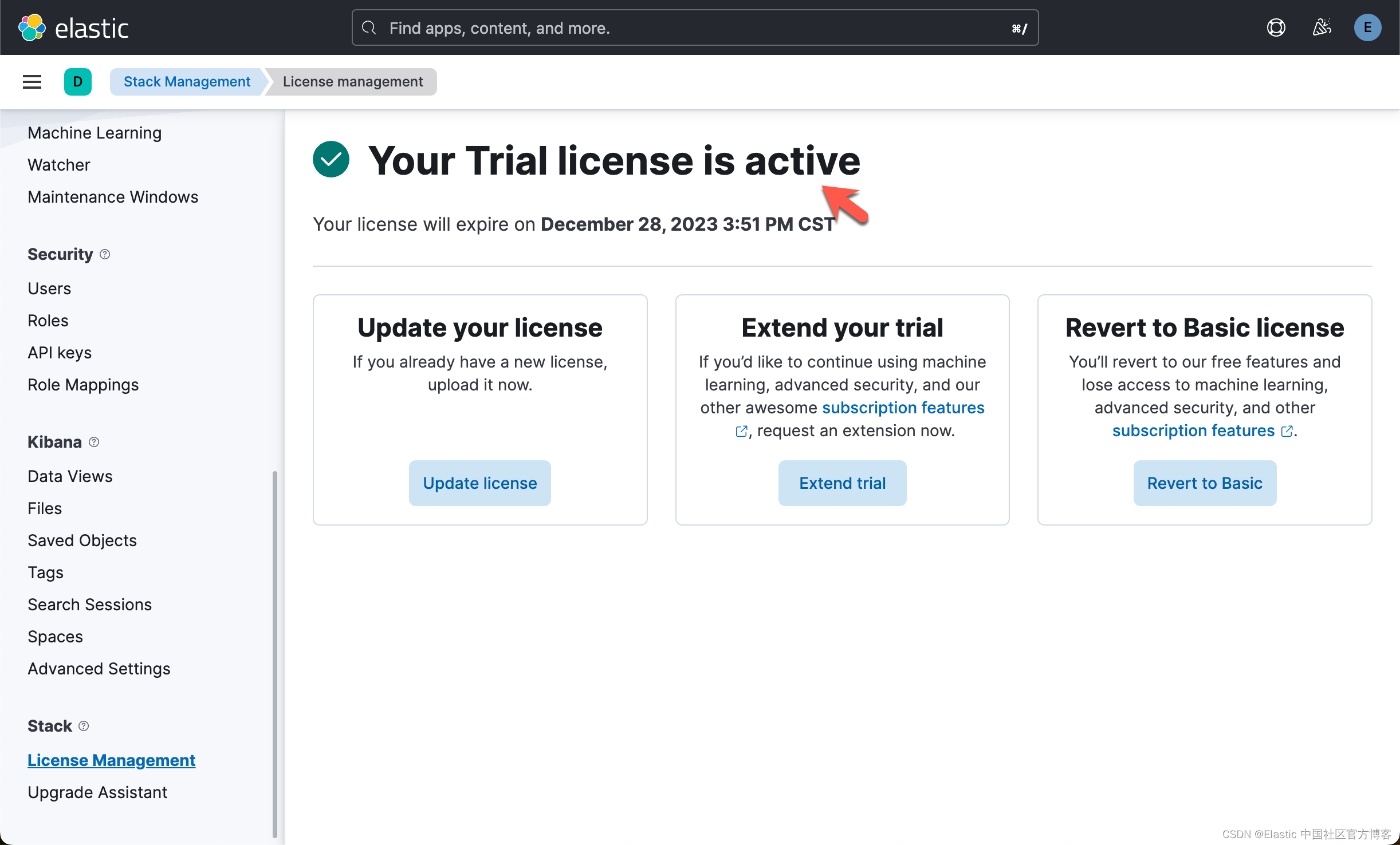
为了能够上传向量模型,我们必须订阅白金版或试用。

安装 ELSER 模型
如果你还没有安装好 ELSER 模型,请参考文章 “Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR” 来进行安装。在这里就不再累述了。请注意安装好的 ELSER 模型的 ID 为 .elser_model_2 而不是之前那篇文章中的 .elser_model_1。

下载数据集
我们在地址 https://raw.githubusercontent.com/elastic/elasticsearch-labs/main/datasets/book_summaries_1000_chunked.json 下载好数据集并保存于当前的项目目录下。
拷贝 Elasticsearch 证书
我们把 Elasticsearch 的证书拷贝到当前的目录下:
$ pwd
/Users/liuxg/python/elser
$ cp ~/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt .
$ ls
Chatbot with LangChain conversational chain and OpenAI.ipynb
ElasticKnnSearch.ipynb
ElasticVectorSearch.ipynb
ElasticsearchStore.ipynb
Mental Health FAQ.ipynb
Multilingual semantic search.ipynb
NLP text search using hugging face transformer model.ipynb
Question Answering with Langchain and OpenAI.ipynb
RAG-langchain-elasticsearch.ipynb
Semantic search - ELSER.ipynb
Semantic search quick start.ipynb
a.ipynb
book_summaries_1000_chunked.json
books.json
data.json
http_ca.crt
lib
sample_data.json
vector_search_implementation_guide_api.ipynb
workplace-docs.json如上所示,我们的 Elasticsearch 的证书是 http_ca.crt。我们的数据集是 book_summaries_1000_chunked.json。
创建环境变量
在运行之前,我们必须使用如下的命令来安装相应的 elasticsearch 包:
pip3 install elasticsearch==8.11在启动 jupyter notebook 之前,我们必须运行如下的命令来创建所需要的环境变量:
export ES_USER="elastic"
export ES_PASSWORD="o6G_pvRL=8P*7on+o6XH"
export ES_ENDPOINT="localhost"
我们创建一个新的 find_books_about_christmas_without_searching_for_christmas.ipynb。
运行应用
创建客户端连接
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
es = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)print(es.info())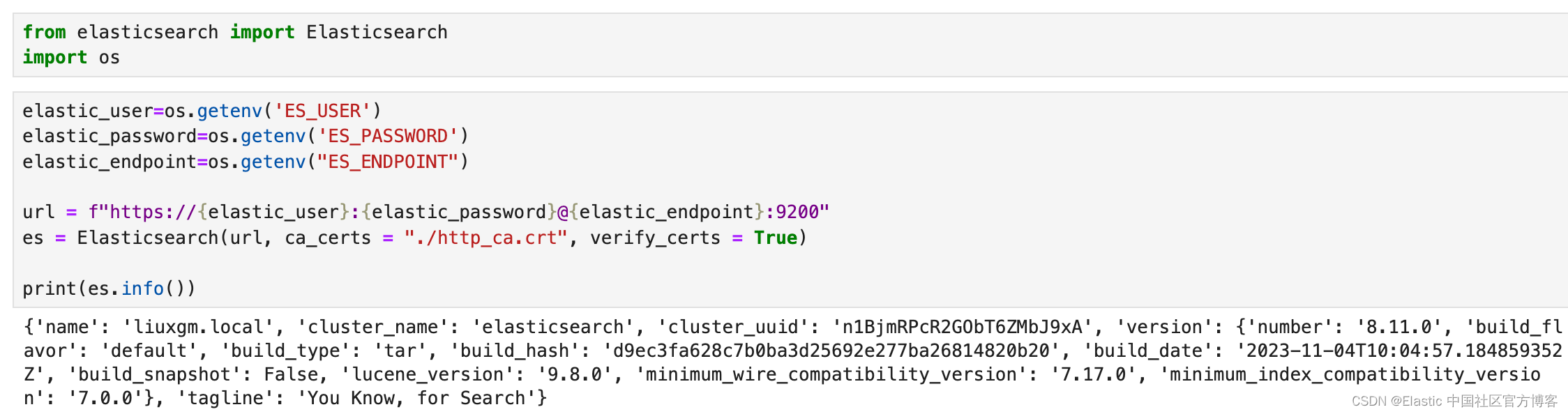
如上所示,我们的 Elasticsearch 客户端连接是成功的。
创建 ingest pipeline
PIPELINE_ID="vectorize_books_elser"es.ingest.put_pipeline(id=PIPELINE_ID, processors=[{"foreach": {"field": "synopsis_passages","processor": {"inference": {"field_map": {"_ingest._value.text": "text_field"},"model_id": ".elser_model_2","target_field": "_ingest._value.vector","on_failure": [{"append": {"field": "_source._ingest.inference_errors","value": [{"message": "Processor 'inference' in pipeline 'ml-inference-title-vector' failed with message '{{ _ingest.on_failure_message }}'","pipeline": "ml-inference-title-vector","timestamp": "{{{ _ingest.timestamp }}}"}]}}]}}}
}])如果大家对上面的 processor 的设计不是很清楚的话,可以详细阅读文章 “ELSER 模型 2”。
创建 mappings 及索引
mappings = {"properties": {"title": {"type": "text"},"published_date": {"type": "text"},"synopsis": {"type": "text"},"synopsis_passages": {"type": "nested","properties": {"vector": {"properties": {"is_truncated": {"type": "boolean"},"model_id": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"predicted_value": {"type": "sparse_vector"}}}}}
}
}
# Create the index (deleting any previously existing index)
es.indices.delete(index="books", ignore_unavailable=True)
es.indices.create(index="books", mappings=mappings)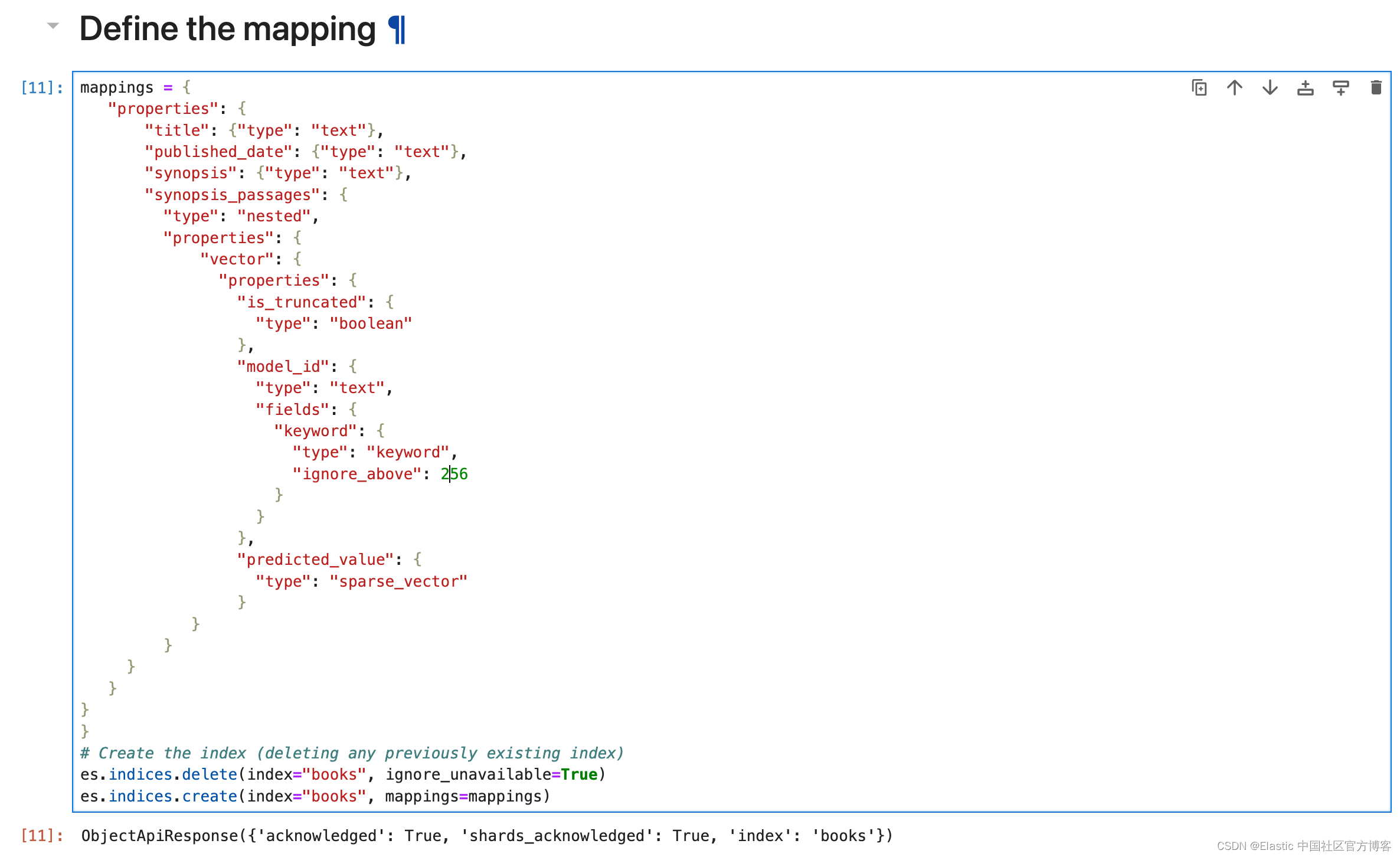
我们可以在 Kibana 中查看到最新的 books 索引:
加载文档到 Elasticsearch
现在我们可以使用 bulk API 来提取我们的文档。 请注意,我们传递了之前创建的管道名称,以使用我们的 ELSER ML 模型来丰富文档。
import jsonwith open('book_summaries_1000_chunked.json') as f:books = json.load(f)print("length of books: %d" %(len(books)))from elasticsearch.helpers import streaming_bulk
count = 0
def generate_actions(books):for book in books:doc = {}doc["_index"] = "books"doc["pipeline"] = "vectorize_books_elser"doc["_source"] = bookyield docfor ok, info in streaming_bulk(client=es, index="books", actions=generate_actions(books),max_retries=3, request_timeout=60*3, chunk_size=10):if not ok:print(f"Unable to index {info['index']['_id']}: {info['index']['error']}")
运行完上面的命令后,我们可以在 Kibana 中进行查看:

我们共有 999 个文档。我们可以在 Kibana 中进行查看直到 999 个文档完全被写入:
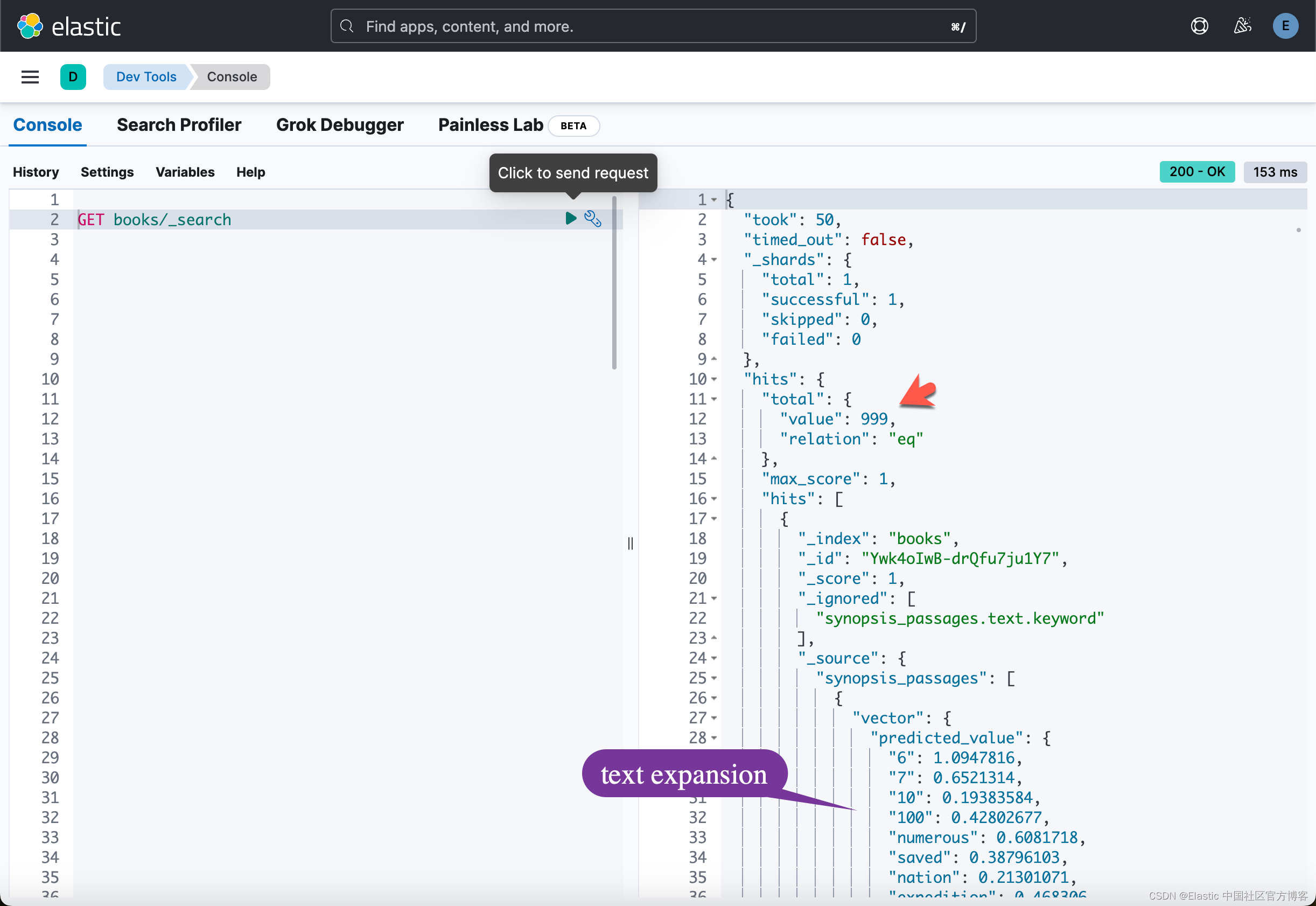
查询文档
我们现在已经准备好进行有趣的部分:测试一些查询以查看我们得到的结果。 这里的一件很棒的事情是,Elasticsearch 支持使用相同索引的关键字搜索和语义搜索,只要数据已正确索引即可,这里就是这种情况。 我们已将概要索引为文本以及稀疏向量数组。
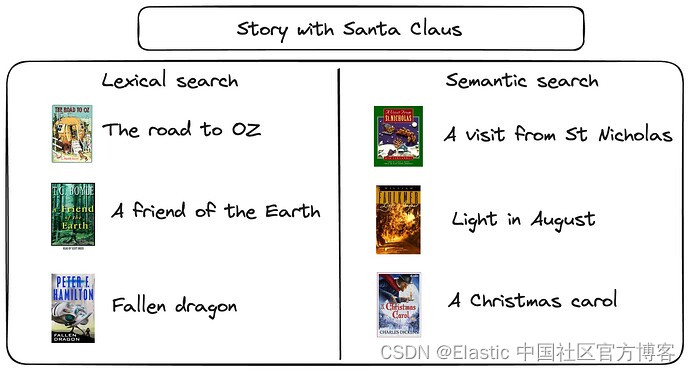
在这里,我们将尝试使用以下查询来查找有关圣诞节的书籍:
“Story with Santa Claus”
“Xmas stories”
“Gift receiving and festive season”使用关键字搜索(BM25)进行搜索的查询如下:
POST books/_search
{"_source": ["title"], "query": {"match": {"synopsis": "Xmas stories"}}
}
使用语义搜索进行搜索的查询是这样的:
POST books/_search
{"_source": ["title"],"query": {"nested": {"path": "synopsis_passages","query": {"text_expansion": {"synopsis_passages.vector.predicted_value": {"model_id": ".elser_model_2","model_text": "Xmas stories"}}}}}
}我不是英文的专家,也不是圣诞节书的爱好者。但是在搜索的有些词里,我们还是可以看到和圣诞或者 christian 有关的文字:

因为我们没有使用关键字 Christmas,所以在这种情况下语义搜索优于词汇搜索。
查看第一个查询的结果:“Story with Santa Claus”。 语义搜索看起来更相关。
我们可以做如下 keyword 查询:

我们做语义搜索:
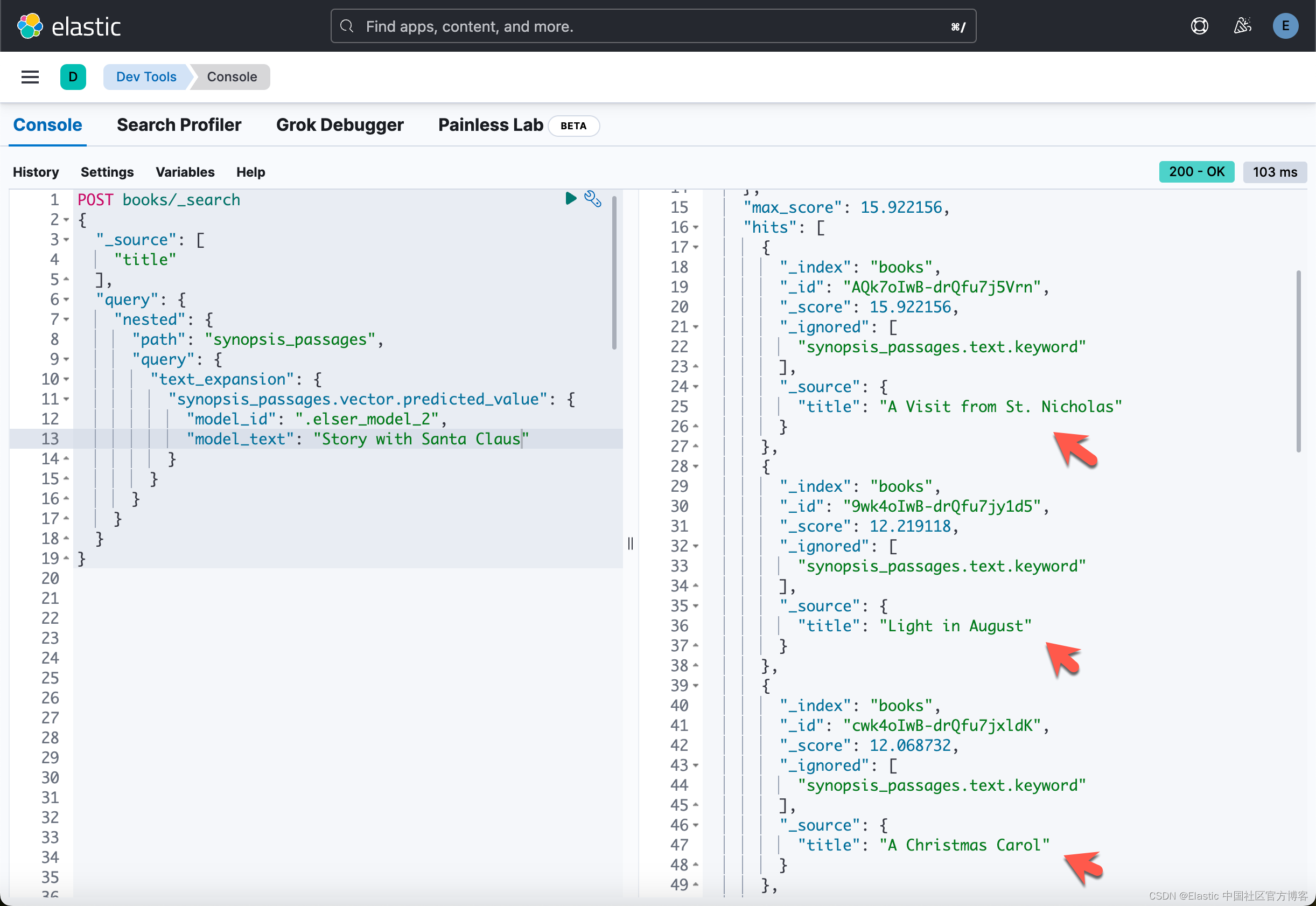
对于其他两个测试查询,我们得到以下结果:
-
“Xmas stories”
-
Lexical search:
- Naked Lunch
- Lost Girls
- Gilgamesh the King
-
Semantic search:
- A Visit from St. Nicholas
- Light in August
- A Christmas Carol
-
-
“Gift receiving and festive season”
-
Lexical search:
- Smith of Wootton Major
- A Canticle for Leibowitz
- A Gift Upon the Shore
-
Semantic search:
- Smith of Wootton Major
- A Visit from St. Nicholas
-
我让你看看哪些书与圣诞节庆祝活动最相关。
最后我们完整的代码在地址:https://github.com/liu-xiao-guo/semantic_search_es/blob/main/%20find_books_about_christmas_without_searching_for_christmas.ipynb











)
覆盖优化 - 附代码)

)
)



