
阿里妹导读:工作那么忙,怎么给女朋友买包?是翻看包包的详情页,再从商品评论中去找信息吗?为了帮助类似的同学节省时间,阿里工程师们提出快速回答生成模型RAGE。你问它答,这个“百事通”能从整体结构,评论的抽取和表示及融合四个方面综合解决生成模型响应速率及生成质量的问题,进而提高生成的回答的真实性及有效性。从此,如何给女友“买包”,不再是难题。
本篇内容参考论文《Review-Driven Answer Generation for Product-Related Qestions in E-Commerce》论文作者为:武汉大学李晨亮、陈诗倩,阿里巴巴计峰、周伟、陈海青。
引言
随着互联网技术的普及,电子商务产业得到了蓬勃的发展,用户的购买行为逐渐由线下转移到线上,然而线上购物带来便利的同时,弊端也逐渐显现。用户在做购买决定之前,通常希望获取更多的商品详情与使用感受等信息,然而,当网页浏览与点击代替了面对面的交易,用户无法获得直观的判断,仅能通过翻阅商品详情页及已购买用户的评论获取有效信息。用户需浏览及过滤大量的评论信息才能获得商品的综合评价,这无疑增加了线上购物的时间成本,降低了用户的购物体验。
为了解决线上环境信息获取渠道闭塞且耗时的问题,各大电商平台,例如,淘宝、亚马逊,相继提供社区问答(CQA)的服务。虽然社区问答在一定程度上缓解了部分用户浏览及过滤评论信息的时间成本,然而,等待已购买用户回答问题的过程同样是低效耗时且低召回的。因此,为了进一步节省用户购物时间,各大电商平台开始探索通过智能问答系统,自动、及时且真实的回答用户提出的商品相关性问题,帮助用户获取所需的信息。虽然现有的智能问答系统经过了几十年的发展,已经相对成熟,然而依然无法在电商领域广泛应用,其原因在于:
1.检索式问答系统过分依赖于问答库,而电商领域中问题形式千变万化,构造完整的问答库相对困难且耗时。
2.现有的生成式问答系统的工作均以循环神经网络及其变种形式为基础。循环神经网络因其时序特性而无法并行处理,导致效率较低。
3.目前生成式问答系统外部信息的引入主要依赖于结构化的知识库或者是关键词及主题模型,而在电商领域中,商品知识库的构造是一项消耗时间及人力成本的工作。
因此针对电商领域问答系统的需求现状及现有工作中存在的不足,我们创新性的提出了利用非结构评论信息引导回答生成的思想,同时提出了一种基于多层门控卷积神经网络的快速回答生成模型RAGE。该模型分别从整体结构,评论的抽取、表示及融合四个方面综合解决生成模型响应速率及生成质量的问题,进而提高生成的回答的真实性及有效性。
2 模型
模型整体结构如图1:
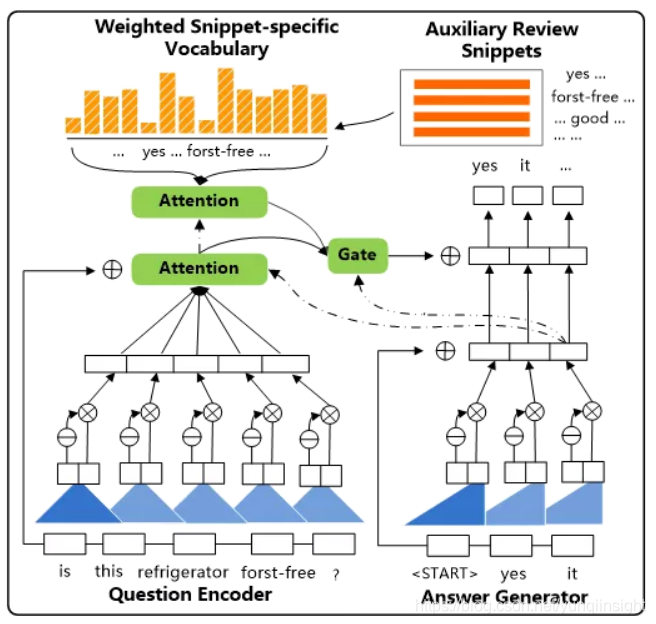
2.1基础结构
2.1.1问题编码器
考虑到循环神经网络存在的种种不足,我们选择采用门控卷积神经网络作为问题编码器对问题序列进行编码。然而,卷积神经网络因其权值共享的特性,导致其对位置信息不敏感。为解决门控卷积神经网络位置信息丢失的问题,我们在输入矩阵中引入位置向量,以保证卷积过程中模型对于位置信息的敏感性。同时,我们将词性信息(POS tag)引入输入矩阵,词性信息中所包含的句法和词法信息能够更好的帮助门控卷积神经网络理解词间关系和文本语义。
给定分词后的问题序列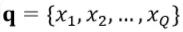
,依照公式2-1所示,结合同维词向量w,位置向量t,词性向量p,得到每个词的表示向量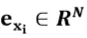 ,其中Q为问题长度,N为向量维度。
,其中Q为问题长度,N为向量维度。
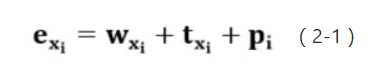
而后我们通过堆叠多层的门控卷积神经网络来扩大其感受野,高层次的门控卷积神经网络可以通过低层次的门控卷积神经网络提取的特征建模距离中心词较远的上下文。同时,为了避免因为网络层数加深而产生梯度消失问题,本文利用残差学习网络(ResidualConnection),将l层输入与l层的输出结合作为l+1层的输入,以保证在反向传播的过程中梯度能稳定的在层级间传播。基于多层门控卷积神经网络的问题编码过程如公式2-2所示:
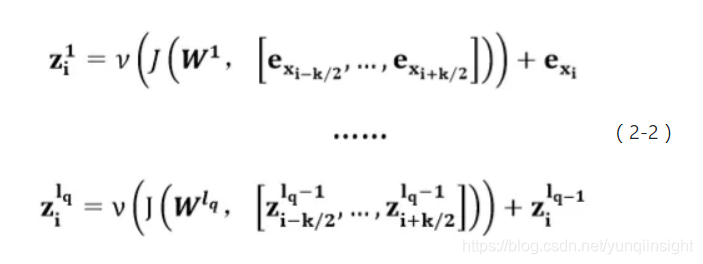
式中为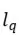 问题编码器的层数,
问题编码器的层数,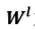 为l层的卷积核,
为l层的卷积核,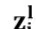 为中心词i及其上下文经过第l层门控卷积神经网络编码输出的状态。
为中心词i及其上下文经过第l层门控卷积神经网络编码输出的状态。
经过层层编码后,最高层次的编码状态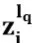 中包含了丰富的信息,而最原始的中心词i本身的信息也相对被弱化了,因而我们借鉴残差网络的思想,按照公式2-3所示,将中心词i原始的表示向量
中包含了丰富的信息,而最原始的中心词i本身的信息也相对被弱化了,因而我们借鉴残差网络的思想,按照公式2-3所示,将中心词i原始的表示向量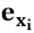 与其对应的最高层次的编码状态相结合,得到中心词i的编码向量
与其对应的最高层次的编码状态相结合,得到中心词i的编码向量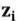 。
。
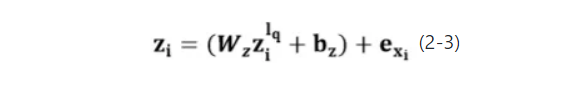
将问题中的每个词作为中心词进行多层卷积操作,最终得到问题编码向量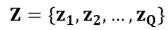
2.1.2 基础解码器
给定已生成的回答序列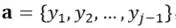 ,解码器的作用是对已生成的回答序列?进行编码,得到j时刻的状态向量,结合问题编码向量解码出第j个词。与问题编码器一样,我们将解码器的基本模块也替换为多层门控卷积神经网络。解码器的输入部分仅为待生成词的前向序列,例如,当前待生成的词为第j个词,即此时编码器处于第 j 时刻,当前时刻的输入为j-1时刻生成的词
,解码器的作用是对已生成的回答序列?进行编码,得到j时刻的状态向量,结合问题编码向量解码出第j个词。与问题编码器一样,我们将解码器的基本模块也替换为多层门控卷积神经网络。解码器的输入部分仅为待生成词的前向序列,例如,当前待生成的词为第j个词,即此时编码器处于第 j 时刻,当前时刻的输入为j-1时刻生成的词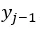 ,输入序列为
,输入序列为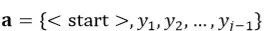 ,其中为解码开始符。输入序列中的每个词用词向量,词性向量,位置向量进行表示,即可得到j时刻的输入序列表示
,其中为解码开始符。输入序列中的每个词用词向量,词性向量,位置向量进行表示,即可得到j时刻的输入序列表示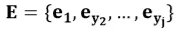 。
。
编码的过程与问题编码过程类似,不同的地方在于,卷积核的感受野被限制为上文而非上下文,因为回答生成的过程中,j时刻的生成词由第j时刻的状态向量决定,而就生成过程而言,下一时刻的状态对于当前时刻是未知的,所以j时刻的状态向量中不应该带有下文的信息,如公式2-4,2-5所示:
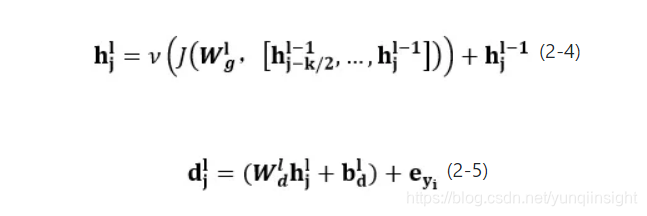
式中当前时刻为j时刻,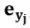 为当前时刻的输入,即j-1时刻的生成词,为l层的卷积核,
为当前时刻的输入,即j-1时刻的生成词,为l层的卷积核,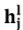 为中心词j及其上下文经过第l层门控卷积神经网络编码后输出的状态,
为中心词j及其上下文经过第l层门控卷积神经网络编码后输出的状态,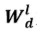 为第l层的映射矩阵,
为第l层的映射矩阵,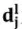 为l层于j时刻的状态向量。
为l层于j时刻的状态向量。
而后,通过注意力机制将问题中所包含的与当前生成词相关的信息引入生成状态,使得最终生成的回答贴合问题核心语义。考虑到多层门控卷积神经网络的层次结构,在这里采用层次型注意力机制,即回答生成器中每一层l得到的状态向量均与问题编码向量Z计算注意力权重分布,最终得到与当前l层j时刻生成状态相关的加权问题编码向量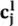 ,其中与当前生成状态相关的信息将被赋予较大的权重,具体过程如公式2-6,2-7所示:
,其中与当前生成状态相关的信息将被赋予较大的权重,具体过程如公式2-6,2-7所示:
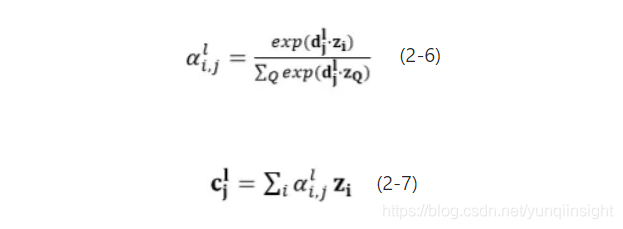
式中表示点乘,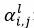 表示第l层中,j时刻的生成状态与问题中第i个词的编码向量计算的注意力权重,越大表示j时刻的生成状态与问题第i个词表达的信息越相关。
表示第l层中,j时刻的生成状态与问题中第i个词的编码向量计算的注意力权重,越大表示j时刻的生成状态与问题第i个词表达的信息越相关。
而后,将l层j时刻的生成状态依照公式2-8进行更新,作为l+1层的输入。

最后,回答生成器根据最高层j时刻的生成状态来确定词表生成概率的分布,如公式2-9所示,其中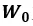 为词表映射矩阵,
为词表映射矩阵,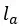 为回答生成器的层数。
为回答生成器的层数。
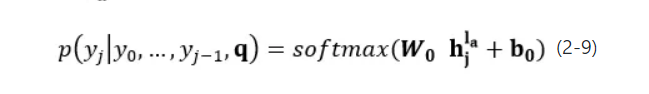
2.2 评论的抽取、表示及融合
2.2.1 评论的抽取
我们采用Word Mover’s Distance(WMD来衡量文本间的语义关系进行评论片段的抽取。对于给定问答对,首先拼接问答对中的问题与答案,而后对该问答对以及问题对应商品的所有评论片段集合R中的一个评论片段r进行分词并去除停用词,将两者分别表示为词袋,再分别计算每个词的词频。
WMD利用词向量间的欧式距离来表示词间的转移开销,问答对中的第i个词到评论片段中第j个词的转移开销表示为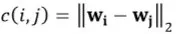 。得到词间转移开销即可得到文本间的转移开销。假设,问答对p中的每个词i允许转移到评论片段r中的任意词j,WMD中用每个词的词频来表示词在文本中的占比,用矩阵
。得到词间转移开销即可得到文本间的转移开销。假设,问答对p中的每个词i允许转移到评论片段r中的任意词j,WMD中用每个词的词频来表示词在文本中的占比,用矩阵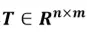 表示词间转移比率,
表示词间转移比率,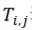 表示p中的第i词中有“多少”转移到r中的第j个词,每个词的转移总和及接收总和不能超过其在文本中的占比,即,
表示p中的第i词中有“多少”转移到r中的第j个词,每个词的转移总和及接收总和不能超过其在文本中的占比,即, 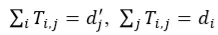
最终用问答对和评论片段间的最小转移开销表示两者间的距离,如公式2-10所示:
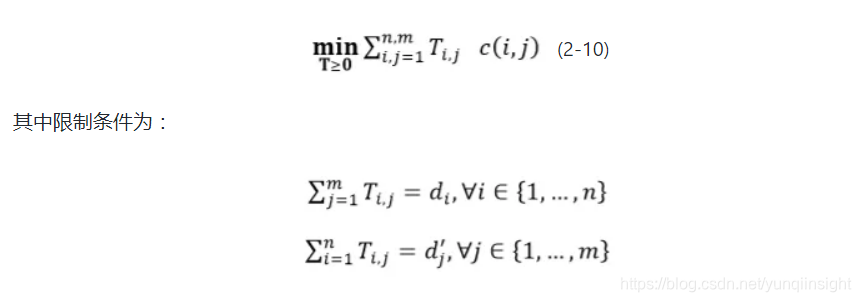
后续我们利用阈值对计算WMD后的评论片段集合进行过滤得到与问答对p对应的问题相关评论片段集合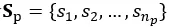 。为整个训练集中的所有问题对应的前10条评论片段集合的Word Mover’s Distance的均值。
。为整个训练集中的所有问题对应的前10条评论片段集合的Word Mover’s Distance的均值。
2.2.2评论片段的表示
给定相关评论片段集合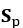 ,首先将其去除停用词表示为词袋,利用公式2-11分别计算词袋中每个词的权重
,首先将其去除停用词表示为词袋,利用公式2-11分别计算词袋中每个词的权重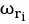 。
。
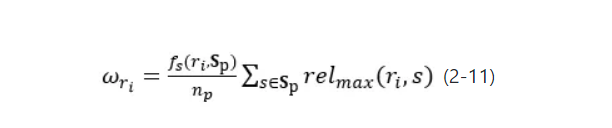
式中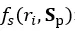 表示计算中有多少条评论中包含单词,
表示计算中有多少条评论中包含单词,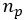 为中包含评论片段的数量,表示单词
为中包含评论片段的数量,表示单词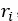 和评论片段 s 中所有单词在词向量基础上计算的余弦相似度,返回余弦相似度的最大值。一个单词若具有较高的片段频率并且和其余片段中的词密切相关。而后对权重进行最大归一化,结合词向量得到带权词典,如公式2-12,2-13所示,式中为逐维相乘操作。
和评论片段 s 中所有单词在词向量基础上计算的余弦相似度,返回余弦相似度的最大值。一个单词若具有较高的片段频率并且和其余片段中的词密切相关。而后对权重进行最大归一化,结合词向量得到带权词典,如公式2-12,2-13所示,式中为逐维相乘操作。
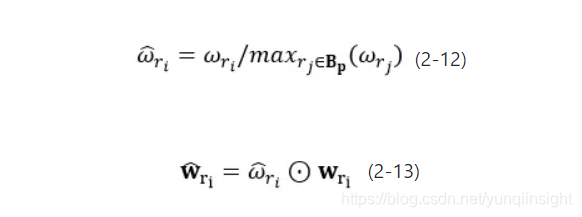
结合词向量得到带权词典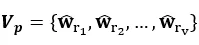 ,如公式2-12,2-13所示,式中为逐维相乘操作。
,如公式2-12,2-13所示,式中为逐维相乘操作。
2.2.3 评论的融合
为了使每一层的生成状态均对外部信息保持敏感,在回答生成器中我们同样采用了层次注意力机制。另外,我们认为问答任务中外部信息的选择过程不仅仅由当前的生成状态决定,还应与问题的语义密切相关。因此,在RAGE中我们利用与当前生成状态相关的加权问题编码向量与带权词典计算注意力权重,其原因在于加权问题编码向量中不仅仅含有当前生成状态的信息,同时包含了问题的语义信息,能够准确的对外部信息进行选择。其具体过程如公式2-14,2-15所示,最终得到与l层j时刻生成状态相关的评论信息编码向量。
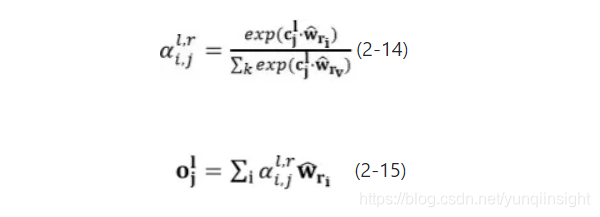
式中表示第l层中,j时刻的问题编码向量与带权词典中中第i个词的表示向量计算的注意力权重。
为了避免信息的冗余,在每一层中本文通过门控机制选择性的利用问题编码信息和评论信息对生成状态进行更新,得到最终的生成状态。因而,将公式2-8改为公式2-16。

式中为门控权值向量,由l层的j时刻生成词生成状态,当前生成状态相关的加权问题编码向量,当前生成状态相关的评论信息编码经过函数()映射而得,具体程如公式2-17所示。
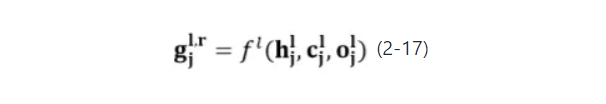
式中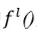 为两层矩阵映射及Sigmoid非线性变换。
为两层矩阵映射及Sigmoid非线性变换。
3 实验
3.1对比模型
1)Seq2seqwith Attention(Bahdanau 2016)
2)TA-Seq2seq(Xing2017)
3)ConvSeq2seq(Gehring2017)
4)ConvSeq2seq-RV:在ConvSeq2seq的基础上,每次生成时动态的限制生成的词必须出现在其对应的相关评论片段中
5)RAGE/POS:RAGE去除POS信息
3.2数据集
我们使用了两个淘宝平台中真实的“问大家”数据集对模型的生成效率及质量进行测评,两个数据集分别为“手机”相关数据集及“大家电”相关数据集。其中“手机”数据集相对较小,仅涉及4457个商品,而“大家电”数据集相对较大且离散,包含冰箱、洗衣机等多个子类目下的47979个商品。
为了测试RAGE模型的泛化能力,本文从手机数据集中随机挑选出6个品牌的商品相关性问题及其对应商品的评论作为测试集,其余商品的问答对和评论作为训练集。同样的,随机挑选出“大家电”数据集下的两个子类目,取其问题及评论作为测试集,其余商品问答对和评论构成训练集。
最终得到的数据集统计信息如表4-1所示。表中表示问答对的数量,表示问题的词平均长度,表示标准回答的词平均长度,表示抽取的平均评论片段数目。
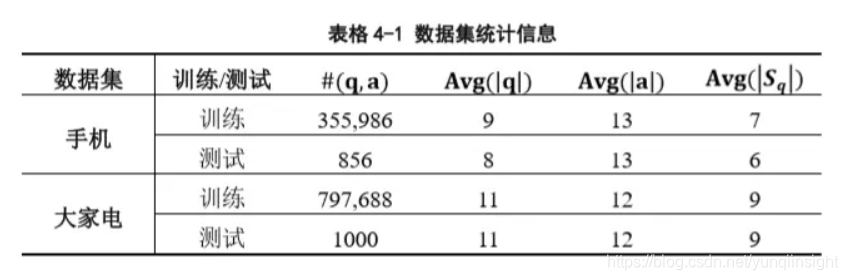
对于测试集,我们仅保留其问题部分,该问题对应的标准回答仅用于衡量模型的生成效果不应参与训练及生成过程。抽取评论片段的过程中,我们首先利用Word Mover’s Distance在训练集中寻找其最相似的问题,取该问题的答案与测试集中的问题构成问答对。
3.3 评价指标
客观评价指标我们采用词平均相似度(Embedding BaseSimilarity;ES)及句中离散度(Distinct)来衡量。主观评价方面,我们规定了如下的打分标准:+3:如果生成的回答既通顺又与问题密切相关,同时包含有效信息且该有效信息与标准回答及用户评论相符,则该回答为3分。+2:如果生成的回答包含与标准回答及用户评论相符的有效信息,但是含有部分的语法错误,比如重复生成、句式紊乱等,则该回答为2分。+1:如果生成回答仅能够用于回答问题,但是不包含有效的信息,比如“我是给别人买的,我不知道”,“可以,可以”等无意义的回答,则该回答为1分。0:如果生成的回答毫无意义或者包含太多的语法错误以至于难以理解,则该回答为0分。而后邀请两位评价者对模型的生成回答进行评价,并利用kappa值衡量评价者间的评价一致性。
3.4 实验结果及分析
我们对各模型进行了客观指标的评价,,并得到了如表4-2的结果。通过对两个指标的观察我们发现,“大家电”数据集的词平均相似度整体低于“手机”数据集,其原因可能是由于“大家电”数据集类目复杂,句式较为离散,模型不易学习其问答间的转换关系。另外“大家电”数据集中RAGE/POS的句中离散度高于RAGE模型,通过结合主观评价指标的综合分析,我们认为其可能的原因是RAGE/POS生成了部分不相关的词,导致其句中离散度较高。同时我们观察到,TA-Seq2seq和ConvSeq2seq-RV以及RAGE/POS、RAGE的句中离散度和词平均相关性在两个数据集上均高于Seq2seqA和ConvSeq2seq,佐证了本文“引入外部信息有利于生成包含有效信息以及贴合问题语义的回答”的观点。
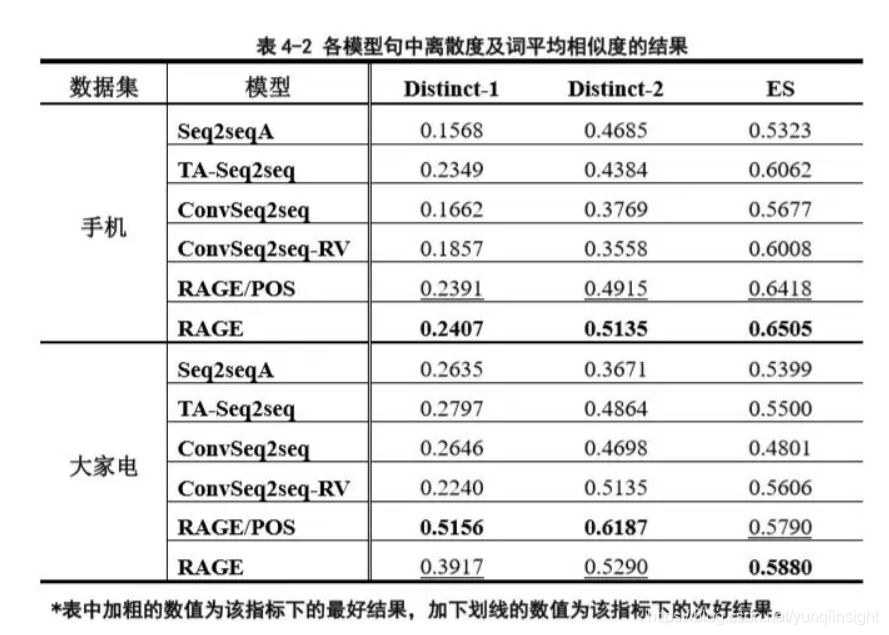
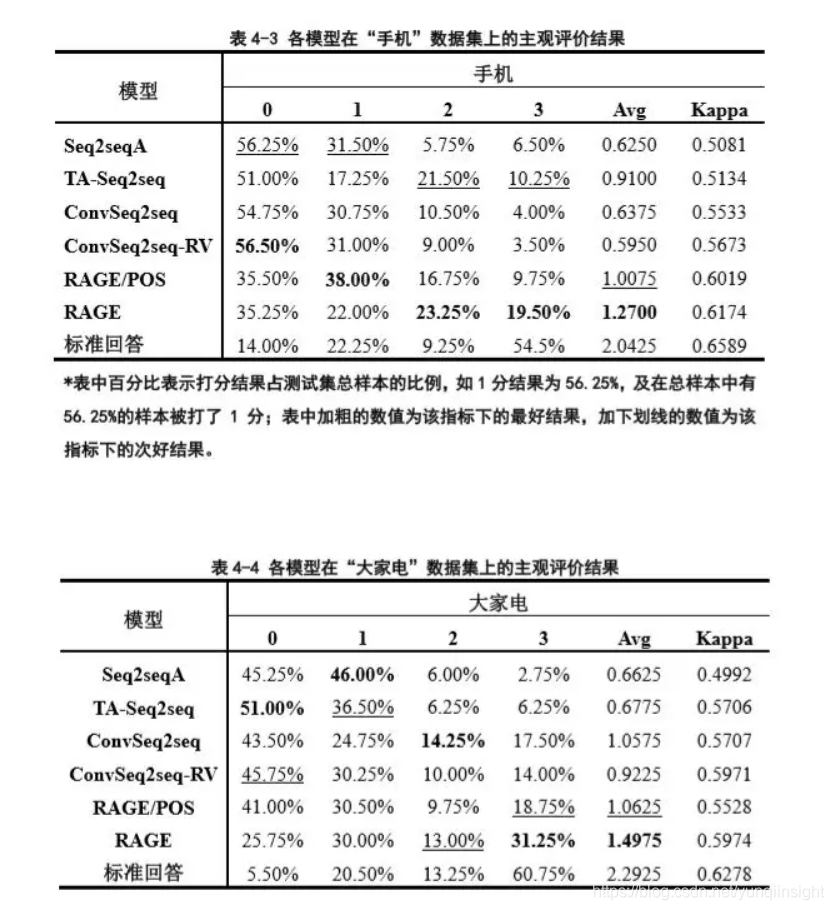
主观评价的部分,我们通过对表4-3,4-4中的结果进行分析,得到如下结论。第一,虽然RAGE生成的回答与标准回答在各方面都存在一定差距,但是相比于现有的回答生成工作,RAGE在通顺性以及包含有效信息程度等方面都有显著的提升。第二,我们可以观察到,RAGE/POS和RAGE在2分的结果上有明显差距,说明词性信息的引入确实有助于提高回答生成的通顺性。
考虑到电商领域实时响应的需求,我们在基础模型的搭建过程中,将以往工作中常用的循环神经网络替换为多层门控卷积神经网络,为证明其效率,我们在单卡 Tesla K40 GPU环境下对比了各个模型的训练及测试效率,其结果如表4-5中所示,可以观察到,基于循环神经网络的Seq2seqA和TA-Seq2seq模型,训练及测试的耗时明显高于基于多层卷积神经网络的其他模型。
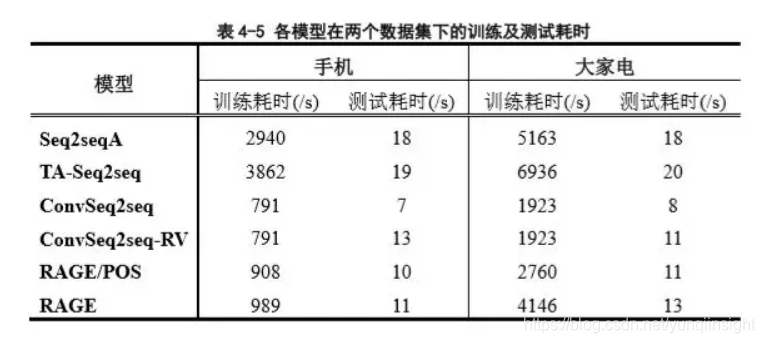
表4-6 Case Study:

最后我们做了Case Study。于表4-6中列出其标准回答,评论抽取过程中Word Mover’s Distance最小的评论片段MSR,以及各个模型的生成结果。通过表中案例可以观察到,对于问题1,2,4这类简单的问题,各个模型生成的回答都相对贴合问题语义。Seq2seqA以及ConvSeq2seq这两个模型由于没有引入外部信息,其生成的回答明显不具备任何有效信息,是所有问题都适用的安全性回答。RAGE得利于其对评论片段的抗噪表示以及融合方式,生成的回答相比于其他模型更加准确、通顺、符合语法且包含丰富的有效信息。
问题3,5,6与问题1,2,4相比较为复杂,其包含了两个子问题,“制冷效果怎么样?”“制热呢?”从表4-6中罗列的结果可知,大部分模型,包括标准回答均只回答了一个子问题,只有RAGE对两个子问题都做出了回答。
4 总结
通过对实验结果进行主观、客观及模型效率的分析,我们认为,RAGE在电商领域的问答任务中有较好的表现,相比于现有的其他工作,RAGE能够更加快速的生成具有通顺性,贴合问题语义且包含丰富信息的回答。
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















