引言:
复杂背景内容提取指的是从复杂的背景中提取出特定的内容,例如在图片中提取特定的文字,在图片中提取特定的叠加图层等等。
这是一个业界难题,基于传统的图像处理的方法存在准确率和召回率的问题,没法解决语义的问题。而主流的机器学习的方法,例如目标检测无法获取像素级别的位置信息,而语义分割的方法则只能提取像素而无法获取半透明叠加前的像素信息。
本文考虑到这些痛点,从UI2CODE业务的业务场景出发,采用了目标检测网络来实现内容召回,GAN网络实现复杂背景中特定前景内容的提取和复原。
处理流程:
复杂背景的处理流程分为如下几个步骤:
内容召回:通过目标检测网络召回元素,即元素是否需要做背景提取操作。
区域判断:根据梯度等视觉方法判断所处区域是否是复杂区域。
简单区域:基于梯度的方式找到背景区块。
复杂区域:采用SRGAN网络进行内容提取。内容召回:
内容召回我们采用目标检测网络来实现,例如Faster-rcnn或者Mask-rcnn等,如下图所示:

区域判断:
根据拉普拉斯算子计算周边梯度,判断所处区域是否是复杂区域。
简单背景:
由于目标检测模型本身的局限性,会导致没法达到像素级别的精确性,因此需要对位置做修正。如果是简单背景就可以基于梯度的思想做位置修正,具体计算方式如下:

复杂背景:
背景是复杂背景时,左图是原图,右图是提取的文字区块:

此时提取出的框不是完全正确,那么此时根据梯度等机器视觉算法已经不能对位置做正确的修正了。本文提出了基于GAN网络的方式来解决复杂背景内容提取问题,网络的主要结构如下图所示:
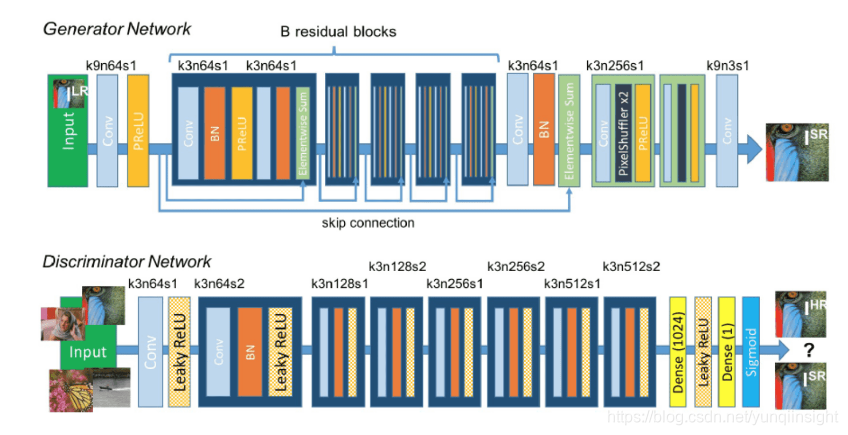
为什么选择GAN网络?
1)基于srGAN网络,该网络加入了特征图的损失函数,这样可以很好保留高频信息,能更好的保留边缘。特征图的损失函数如下图所示:
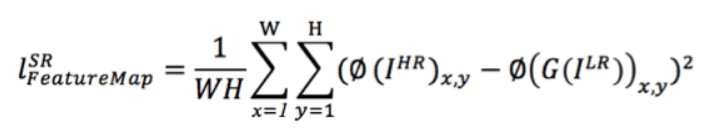
2)由于有对抗损失的存在,可以很好的降低误检率。
3)最重要的一点是在有透明度的场景下,语义分割网络只能“提取”元素,无法“还原”元素。而GAN网络不仅可以在提取元素的同时还原出未叠加时的像素情况。
网络训练流程图
针对业务场景对GAN网络做的改进
1.由于我们不是超分辨率场景,因此不用pixelShuffler模块做上采样
2.由于场景比较复杂,可以引入denseNet和加深网络来提高准确率。
3.内容损失函数对于压制误判的噪点效果不理想,因此加大了误判的惩罚,具体如下图所示:

预测获取的结果图I:

预测获取的结果图II:

结束语
本篇我们通过复杂背景内容提取的介绍,提出了一种机器学习为主,图像处理为辅去精确获取特定前景内容的方法,得到了高精确率、高召回率和高定位精度的识别结果。
下图分别是传统算法grabcut,语义分割方法deeplab和本文方法的各个指标的情况。

经过数据论证,我们发现了一个值得进一步优化的点——需要大量样本适配不同的特征尺度,这里的投入会相对较大。如何进一步提高打标效率呢,我们将会在后续系列文章中和大家分享。
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















 never called!)