背景
阿里云InfluxDB®是阿里云基于开源版InfluxDB打造的一款时序数据库产品,提供更稳定的持续运行状态、更丰富强大的时序数据计算能力。在现有的单节点版本之外,阿里云InfluxDB®团队还将推出多节点的高可用版本。
我们知道现有的开源版InfluxDB只提供单节点的能力,早期开源的集群版本功能不完善、且社区不再提供更新与支持。经过对官网商业版InfluxDB现有文档的研究,我们猜测在商业版InfluxDB集群方案中,meta信息集群是基于一致性协议Raft做同步的,而数据是异步复制的。这种分离的方式虽然有优点,但也引起了一系列的一致性问题,在一些公开的文档中,官方也承认这种数据复制方案并不令人满意。
因此,团队在参考多项技术选型后,决定采用最为广泛使用并有较长历史积累的ETCD/Raft作为核心组件实现阿里云InfluxDB®的Raft内核,对用户所有的写入或一致性读请求直接进行Raft同步(不做meta信息同步与数据写入在一致性过程中的拆分),保证多节点高可用版本拥有满足强一致性要求的能力。
有幸笔者参与到多节点的高可用版本的开发中,期间遇到非常多的挑战与困难。其中一项挑战是ETCD的Raft框架移植过程中,在移除了ETCD自身较为复杂、对时序数据库没有太多作用的Raft日志模块后,所带来的一系列问题。本文就业界Raft日志的几种不同实现方案做讨论,并提出一种自研的Raft HybridStorage方案。
业内方案
ETCD
由于我们采用了ETCD/Raft的方案,绕不开讨论一下ETCD本家的Raft日志实现方式。
官网对Raft的基本处理流程总结参考下图所示,协议细节本文不做扩展:
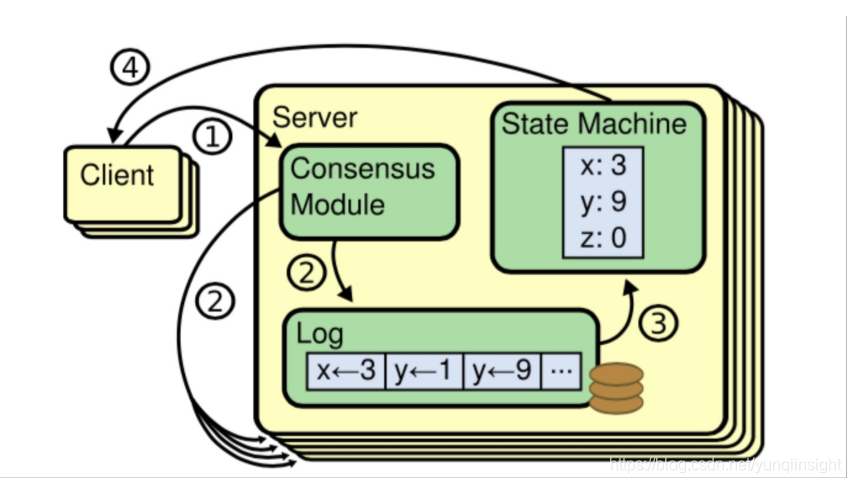
对于ETCD的Raft日志,主要包含两个主要部分:文件部分(WAL)、内存存储部分(MemoryStorage)。
文件部分(WAL),是ETCD Raft过程所用的日志文件。Raft过程中收到的日志条目,都会记录在WAL日志文件中。该文件只会追加,不会重写和覆盖。
内存存储部分(MemoryStorage),主要用于存储Raft过程用到的日志条目一段较新的日志,可能包含一部分已共识的日志和一些尚未共识的日志条目。由于是内存维护,可以灵活的重写替换。MemoryStorage有两种方式清理释放内存:第一种是compact操作,对appliedId之前的日志进行清理,释放内存;第二种是周期snapshot操作,该操作会创建snapshot那一时刻的ETCD全局数据状态并持久化,同时清理内存中的日志。
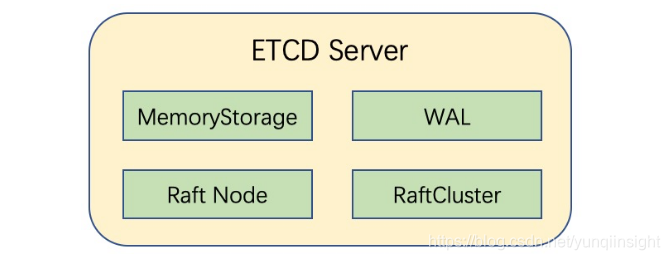
在最新的ETCD 3.3代码仓库中,ETCD已经将Raft日志文件部分(WAL)和Raft日志内存存储部分(MemoryStorage)都抽象提升到了与Raft节点(Node)、Raft节点id以及Raft集群其他节点信息(*membership.RaftCluster)平级的Server层级,这与老版本的ETCD代码架构有较大区别,在老版本中Raft WAL与MemoryStorage都仅仅只是Raft节点(Node)的成员变量。
一般情况下,一条Raft日志的文件部分与内存存储部分配合产生作用,写入时先写进WAL,保证持久化;随之马上追加到MemoryStorage中,保证热数据的高效读取。
无论是文件部分还是内存存储部分,其存储的主要数据结构一致,都是raftpb.Entry。一条log Entry主要包含以下几个信息:
| 参数 | 描述 |
|---|---|
| Term | leader的任期号 |
| Index | 当前日志索引 |
| Type | 日志类型 |
| Data | 日志内容 |
此外,ETCD Raft日志的文件部分(WAL)还会存储针对ETCD设计的一些额外信息,比如日志类型、checksum等等。
CockroachDB
CockroachDB是一款开源的分布式数据库,具有NoSQL对海量数据的存储管理能力,又保持了传统数据库支持的ACID和SQL等,还支持跨地域、去中 心、高并发、多副本强一致和高可用等特性。
CockroachDB的一致性机制也是基于Raft协议:单个Range的多个副本通过Raft协议进行数据同步。Raft协议将所有的请求以Raft Log的形式串行化并由Leader同步给Follower,当绝大多数副本写Raft Log成功后,该Raft Log会标记为Committed状态,并Apply到状态机。
我们来分析一下CockroachDB Raft机制的关键代码,可以很明显的观察到也是从鼻祖ETCD的Raft框架移植而来。但是CockroachDB删除了ETCD Raft日志的文件存储部分,将Raft日志全部写入RocksDB,同时自研一套热数据缓存(raftentry.Cache),利用raftentry.Cache与RocksDB自身的读写能力(包括RocksDB的读缓存)来保证对日志的读写性能。
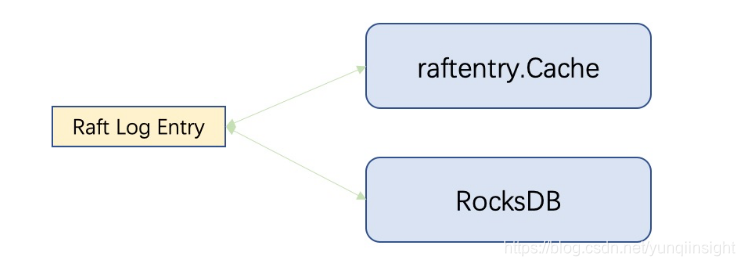
此外,Raft流程中的创建snapshot操作也是直接保存到RocksDB。这样实现的原因,个人推测是可能由于CockroachDB底层数据存储使用的就是RocksDB,直接使用RocksDB的能力读写WAL或者存取snapshot相对简单,不需要再额外开发适用于CockroachDB特性的Raft日志模块了。
自研HybridStorage
移除snapshot
在阿里云InfluxDB多节点高可用方案实现过程中,我们采用了ETCD/Raft作为核心组件,根据移植过程中的探索与InfluxDB实际需要,移除了原生的snapshot过程。同时放弃原生的日志文件部分WAL,而改用自研方案。
为什么移除snapshot呢?原来在Raft的流程中,为了防止Raft日志的无限增加,会每隔一段时间做snapshot,早于snapshot index的Raft日志请求,将直接用snapshot回应。然而我们的单Raft环架构如果要做snapshot,就是对整个InfluxDB做,将非常消耗资源和影响性能,而且过程中要锁死整个InfluxDB,这都是不能让人接受的。所以我们暂时不启用snapshot功能,而是存储固定数量的、较多的Raft日志文件备用。
自研的Raft日志文件模块会周期清理最早的日志防止磁盘开销过大,当某个节点下线的时间并不过长时,其他正常节点上存储的日志文件如果充足,则足够满足它追取落后的数据。但如果真的发生单节点宕机太长,正常节点的日志文件已出现被清理而不足故障节点追取数据时,我们将利用InfluxDB的backup和restore工具,将落后节点还原至被Raft日志涵盖的较新的状态,然后再做追取。
在我们的场景下,ETCD自身的WAL模块并不适用于InfluxDB。ETCD的WAL是纯追加模式的,当故障恢复时,正常节点要相应落后节点的日志请求时,就有必要分析并提取出相同index且不同term中那条最新的日志,同时InfluxDB的一条entry可能包含超过20M的时序数据,这对于非kv模式的时序数据库而言是非常大的磁盘开销。
HybridStorage设计
我们自研的Raft日志模块命名为HybridStorage,即意为内存与文件混合存取,内存保留最新热数据,文件保证全部日志落盘,内存、文件追加操作高度一致。
HybridStorage的设计思路是这样的:
(1)保留MemoryStorage:为了保持热数据的读取效率,内存中的MemoryStorage会保留作为热数据cache提升性能,但是周期清理其中最早的数据,防止内存消耗过大。
(2)重新设计WAL:WAL不再是像ETCD那样的纯追加模式、也不需要引入类似RocksDB这样重的读写引擎。新增的日志在MemoryStorage与WAL都会保存,WAL文件中最新内容始终与MemoryStorage保持完全一致。
一般情况下,HybridStorage新增不同index的日志条目时,需要在写内存日志时同时操作文件执行类似的增减。正常写入流程如下图所示: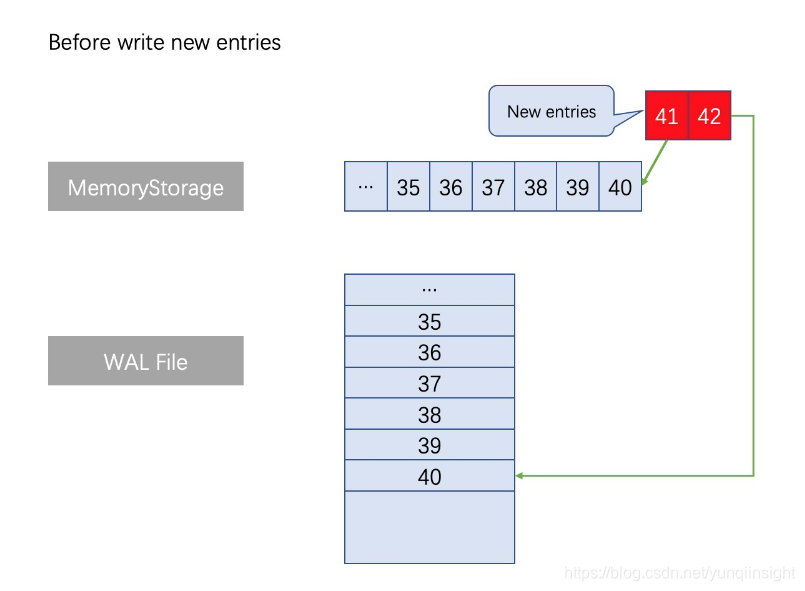
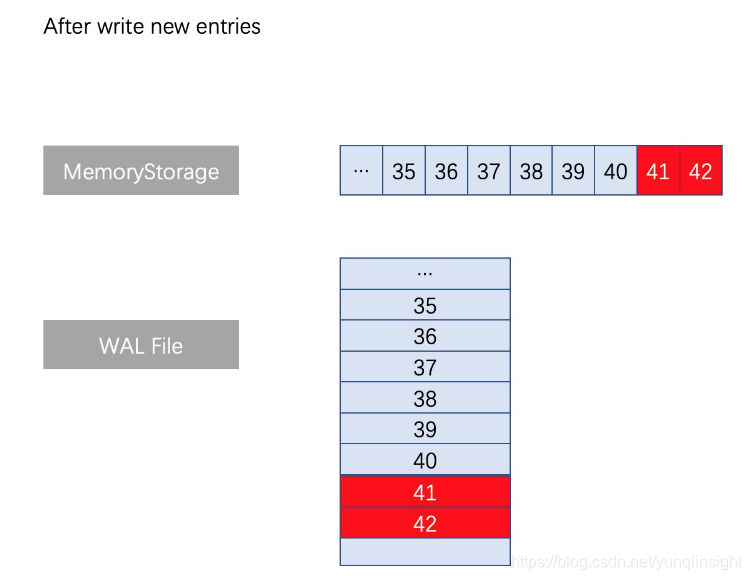
当出现了同index不同term的日志条目的情况,此时执行truncate操作,截断对应文件位置之后一直到文件尾部的全部日志,然后重新用append方式写入最新term编号的日志,操作逻辑上十分清晰,不存在Update文件中间的某个位置的操作。
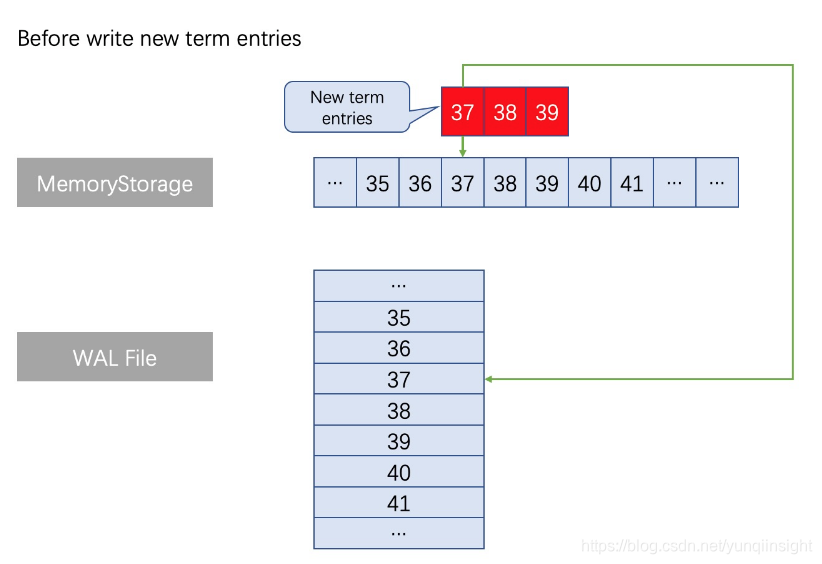
例如在一组Raft日志执行append操作时,出现了如下图所示的同index(37、38、39)不同term的日志条目的情况。在MemoryStorage的处理方式是:找到对应index位置的内存位置(内存位置37),并抛弃从位置A以后的全部旧日志占用的内存数据(因为在Raft机制中,这种情况下内存位置37以后的那些旧日志都是无效的,无需保留),然后拼接上本次append操作的全部新日志。在自研WAL也需要执行类似的操作,找到WAL文件中对应index的位置(文件位置37),删除从文件位置37之后的所有文件内容,并写入最新的日志。如下图分析:

方案对比
ETCD的方案,Raft日志有2个部分,文件与内存,文件部分因为只有追加模式,因此并不是每一条日志都是有效的,当出现同index不同term的日志条目时,只有最新的term之后的日志是生效的。配合snapshot机制,非常适合ETCD这样的kv存储系统。但对于InfluxDB高可用版本而言,snapshot将非常消耗资源和影响性能,而且过程中要锁死整个InfluxDB。同时,一次Raft流程的一条entry可能包含超过20M的时序数据。所以这种方案不适合。
CockroachDB的方案,看似偷懒使用了RocksDB的能力,但因其底层存储引擎也是RocksDB,所以无何厚非。但对于我们这样需要Raft一致性协议的时序数据库而言,引入RocksDB未免过重了。
自研的Raft HybridStorage是比较符合阿里云InfluxDB®的场景的,本身模块设计轻便简介,内存保留了热数据缓存,文件使用接近ETCD append only的方式,遇到同index不同term的日志条目时执行truncate操作,删除冗余与无效数据,降低了磁盘压力。
总结
本文对比了业内常见的两种Raft日志的实现方案,也展示了阿里云InfluxDB®团队自研的HybridStorage方案。在后续开发过程中,团队内还会对自研Raft HybridStorage进行多项优化,例如异步写、日志文件索引、读取逻辑优化等等。也欢迎读者提出自己的解决方案。相信阿里云InfluxDB®团队在技术积累与沉淀方面会越做越好,成为时序数据库技术领导者。
原文链接
本文为云栖社区原创内容,未经允许不得转载。



 never called!)



![mysql [ERR] 1273 - Unknown collation: ‘utf8mb4_0900_ai_ci‘](http://pic.xiahunao.cn/mysql [ERR] 1273 - Unknown collation: ‘utf8mb4_0900_ai_ci‘)











