作者 | 宋慧
出品 | CSDN 云计算
随着 AI 等技术兴起,对于数据的应用分析受到了越来越多的重视,数据赛道热度也持续火热。大数据时代为企业提供 Hadoop 服务的 Cloudera,也推出了新一代数据平台 CDP,并逐渐替代以往的大数据平台 CDH 和 HDP。
最近,CSDN 再次采访了 Cloudera 大中华区技术总监刘隶放,听听 Cloudera 对于云时代下,数据应用的新趋势的观察与经验。
数据愈加分散,范式转向数据网格 Data Mesh、数据编织、湖仓一体
近几年数据的发展,我们能看到,和以往企业对数据集中式管理不同,数字化的深入,让企业内部和外部都在产生超过以往数倍的数据量。另外不断变化的商业环境挑战下,企业对数据的分析和应用也需要更加灵活、敏捷。
因此,刘隶放首先分享了,在这些趋势下,行业对于数据范式的最新定义和趋势,那就是将数据与产品思维融合,将数据产品化,(在企业里)数据由最了解数据的域拥有,随时可供企业内的任何其他域使用,同时,数据需要具有可探索、可寻址、自描述、可信赖、可互操作(开放标准)、安全这六大特性,即数据网格 Data Mesh。总结起来,也是数据网格 Data Mesh 所对应的四个原则:域主权、数据为产品、自助式数据平台和联合计算治理。
随着数据的类型、数量、应用需求的复杂,业界逐步产生了对数据的处理新理念,那就是“数据编织(Data Fabric)”。连续几年对数据领域着重分析的 Gartner 在 2021 年讨论了这一提法,CSDN 曾做过报道: Gartner最新分析:数据编织、数据治理、平衡采集与连接 。

数据编织概念架构示意图
对于今年讨论度很高的,集合了数仓和数据湖优势的新数据应用系统湖仓一体,刘隶放认为其实数据网格、数据编织和湖仓一体,是企业中不同角色对于数据,不同的应用方法论。例如
数据使用者和技术工程师,专注于湖仓一体等新型数据系统如何用于具体业务和项目,而 CTO 则站在数据如何保持一致性、如何构建统一的数据标准的角度,去研究数据编织相关工作,企业管理者 CEO/CIO/CDO 在数据网格层面关注数据的管理成本和扩展性。
Cloudera 的新定位:混合数据公司
经历了 Hadoop 辉煌的大数据时代,现在的 Cloudera 正在转型,并将公司最新定位为混合数据公司,针对企业业务对数据新的需求,去提供适用于数据编织、数据湖库、数据网格和未来数据生态系统架构要求的混合数据平台的混合数据平台,允许客户在多个公共和私有云以及本地访问和分析数据,使企业能够做出由数据驱动的明智决策,帮助企业建立由数据驱动的未来。
而 Cloudera 新推出的 CDP 平台(Cloudera Data Platform),就是实现了对数据的大规模管理、分析、可移植性和安全治理,具体来说:
1、开放数据编织、湖仓,可在任何地方提供大规模数据;
2、多云和本地数据管理一体和数据网格和分析;
3、“一次编写,随处运行”实现数据分析的可移植性;
4、使用开放的云原生存储格式去统一安全和治理。
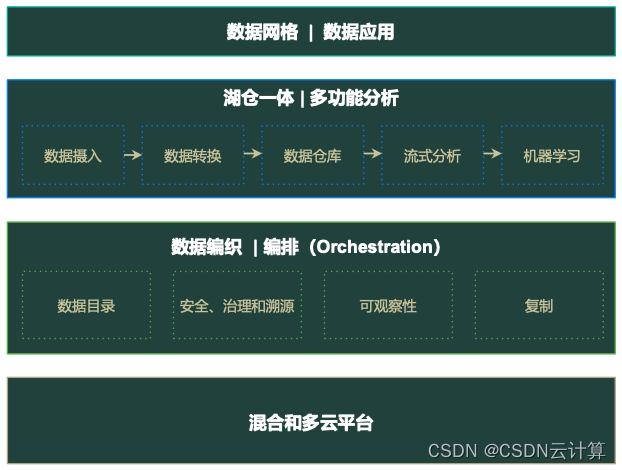
Cloudera CDP 可支持现代数据架构各层需求
刘隶放分享了 Cloudera 的 CDP 平台,对企业现代数据架构各层需求的支持。例如在数据网格层,CDP 面向域的分布式数据产品,由拥有嵌入式数据工程师和数据产品所有者的独立跨职能团队拥有,使用通用数据基础设施作为平台来托管、准备和服务其数据资产。CDP 也集成和统一数据仓库和数据湖的功能,旨在支持同一数据集上的 AI、BI、ML 和数据工程(“多功能分析”)。在数据编织和编排上,CDP 以自助服务的方式智能、安全地动态编排不同的数据源,利用数据平台提供集成的可信数据,以支持各种应用程序、分析和其他工作负载。另外,CDP 也支持混合云和多云,保持数据系统跨所有环境的一致性体验。
数据越来越重要,也越来越被关注。从专业数据厂商 Cloudera 的新定位,我们也能看到,数据分析应用,从数据中台正在形成更完整的系统平台,同时除了一线的数据工程师、CTO 之外,也需要企业的管理者去关注。

















)

