简介:分层架构很容易在各种书籍和文档中去理解,但是把建模方法和分层架构放在一起就会出现很多困惑了。接下来,我会从数据研发与建模的角度,演进一下分层架构的设计原因与层次的意义。
分层架构很容易在各种书籍和文档中去理解,但是把建模方法和分层架构放在一起就会出现很多困惑了。
一、分层的演进
之所以会有分层架构,最主要的原因还是要把复杂冗长的数据吹流程分拆成一些有明确目的意义的层次,这样复杂就被拆解为一些相对简单小的模块。那么分层架构中各层都是怎么产生的呢,我们可以简化看一下。
第一个数据加工任务
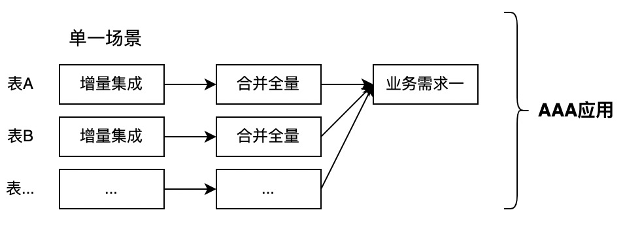
我要进行第一个数据加工任务,一切平台层次都没有,我只有一个MaxCompute。我该怎么做呢?
第一步,我需要自己做一下数据集成,把源系统的数据集成到MaxCompute。
第二步,我需要把增量合并全量生成ODS层,这样我就得到了与业务系统一样的表结构和全量的数据。
第三步,因为我对业务系统的数据表关联关系有了解,所以,我可以根据业务需求使用ODS的全量表做表关联,加工出我想要的数据结果。
第一个数据应用
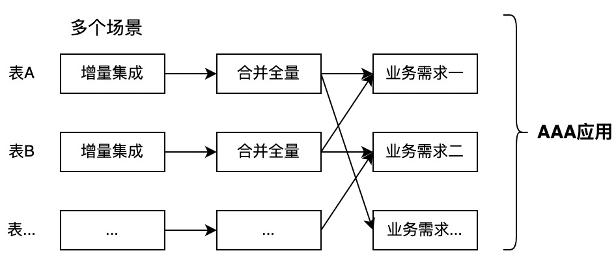
如果我不只是做一个业务需求,我是有很多业务需求,这样我就形成了我的第一个数据应用。所以,我会集成更多的数据,做更多的数据合并全量的工作,并且我的全量ODS的表可以在多个业务场景复用。
但是试想一下,如果不是一个人在开发,那么团队内部是不是要协调一下,对工作进行一下分工。做集成的和做合并的是不是可以分给一部分人,然后把后面业务需求开发再分给另外一部分人。这样就避免了重复工作,和便于工作的专业性。
于是就可以拆分出来上图中的第一个方块“集成”(STG)和第二个方块 “全量”(ODS),这部分是纯技术性的工作,还没有涉及到业务需求。对于实际业务需求计算部分,就是我们的应用层集市层(ADM)。
第二个数据应用
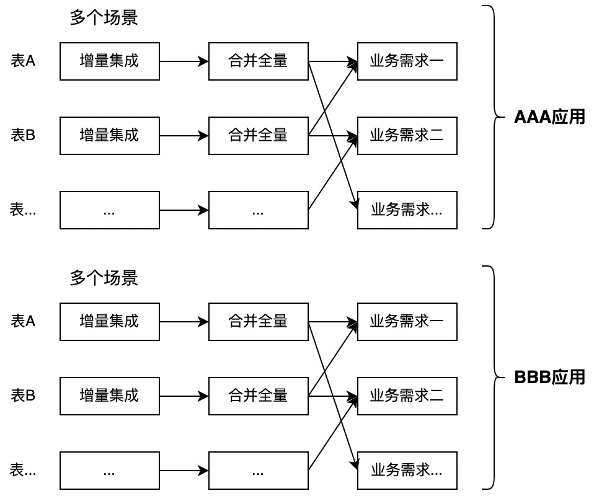
随着第二个数据应用的出现,各自做集成合并已经是非常不适合的做法了,于是就有个独立的STG和ODS层。
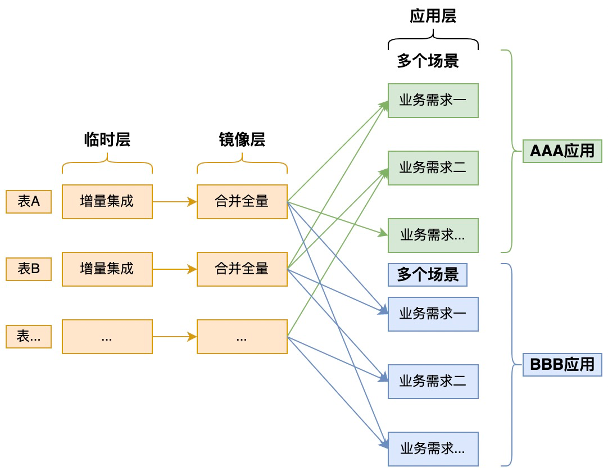
很多时候,做完ODS就可以做业务数据加工了。并且这种情况从数据处理技术发展之初,数据仓库概念提出之前就存在了,现在依然很普遍。集市各自依赖ODS会遇到的多源加工指标不一致的问题逐渐遭人诟病,而造成指标不一致的主要原因重复加工。不同的人对同一业务的理解都很难保障一致性,更何况不同的部门的应用。对于这个问题,可以在各个大型企业早期的数据场景都会遇到,所以,在阿里对外宣传大数据平台的时候也会提到这个早期各个业务部门数据口径不一致的问题。这个问题在ODS的层面无法解决,必须要独立出一个团队来做公共的这部分数据,让各个应用集市去做各自独立的部分,这也是公共层(CDM)的由来。
二、分层与建模
通过上面的内容,我们终于知道了数据加工过程为什么要分层。那么数据建模应该如何来做呢?因为在数据仓库领域,在数据建模一直有两种争锋相对的观点,就是范式建模还是维度建模。我们在目前大数据这个场景,一般就只提一种方法了,就是维度建模。
维度建模的经典方法与教程中没有中间层的概念,也没有主题域划分的概念。维度建模一般用在数据集市场景,也就是ODS+ADM场景,各个业务通过一致性维度实现企业级的数据一致性。在传统的被IOE统治的时代,Teradata、IBM、Oracle都有基于关系型数据库(包括MPP数据库),在某些重要的行业,例如金融这些企业都会构建大型的企业级的维度模型来给集市提供公共数据服务,这就是公共层。因为范式模型导致实体都比较窄,跟实际的分析型业务需求(维度模型)差异太大,所以需要做一层中间层(相对范式模型更宽的表,这也是宽表说法的由来)来做为应用集市层共性加工工作的层次,这就是现在我们在架构中提到的ODS+CDM+ADM的架构。
那么问题就在这里出来了,我们全部使用维度模型建模,如何使用范式模型的架构与概念。这也是我们在分层架构设计中目前最难以讲清楚的问题,也是我们实际在项目里面做的很别扭的原因:缺乏理论与实践支撑。
维度模型的构建是以实际业务需求为导向,模型是不断的需求累积出来的,适应快速的业务变化。而且维度模型不是一个建议一开始就进行企业级的思考设计的模型设计方法,是由局部业务逐渐扩张构建的。所以,我认为维度模型的架构不太适宜一开始做太重的太业务化公共层。反而应该强调在公共层构建共性加工的集合,去协调同步多个应用集市的计算,从而实现全局性的一致性维度和一致性事实。因为维度建模的建设也不是简单一蹴而就的,也是需要多次和多种数据处理以后才能最终变成符合业务需求的结果。多个不同的应用集市有大量的共性的加工需求,这些需求就是我们公共层的收集的建模需求。把这些共性需求在公共层使用维度建模的方法实现才是建设公共层的合理方法,而不是越俎代庖的去建设面向具体某个业务场景的指标标签(就是虽然实际是做了指标和标签的计算,但是我只是一个中间加工过程)。
接下来,我们继续利用上面讲解分层的方法来讲解公共层与集市层的关系。
第一个应用
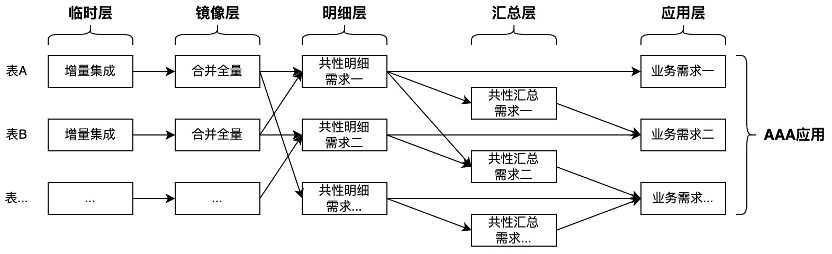
随着第一个应用出现,就可以基于部分的需求构建第一个公共层了。共性加工需求在一个中型的应用集市就很明显了。一、数据清洗。一个表的数据清洗后,会有多个数据加工任务都会使用这个清洗后的表,这就是最简单的共性加工的理解。二、多表关联。多张表的关联也是多个数据加工任务中可以提炼出来的,一次把需要关联使用的字段都关联合并到一张新表,后续的任务就可以直接用这个新表。三、共性汇总。对于数据从明细到汇总的group by,统一根据多个常用条件进行汇总,生成一张新表,后续的任务就可以直接用这个新表。一致性维度是维度建模中最关键的部分,直接影响到各个应用集市的数据标准与一致性问题,是公共层最重要的工作。
第二个应用
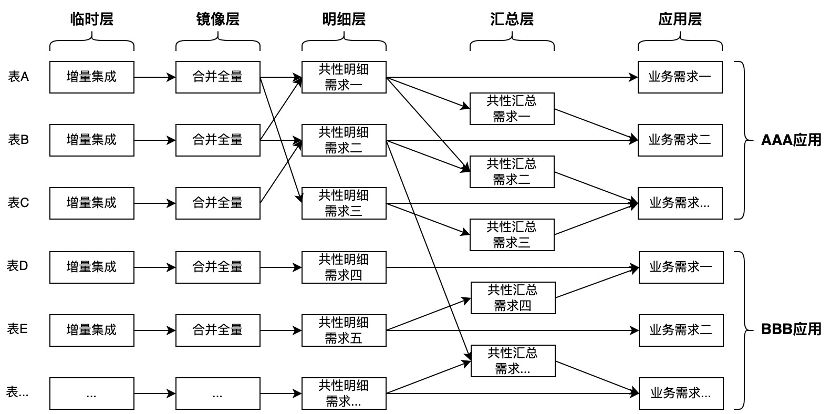
随着应用的增加,需求也在不断的扩充,临时层和镜像层集成的表更多了。在公共层的明细和汇总也出现了多个应用集市都在共用的数据需求,会扩展补充到公共层。并且随着时间的变化,公共层的逻辑的正确性和公共性也需要在多个应用进入后整体考虑。
公共层与应用关系
通过上面两步演进,我们已经看到了公共层与应用层的关系了,是一体的。并不是各做各的,而是一件事情从专业化分工上做了切分。公共层与应用层只有一个共同目标,就是为满足业务需求而做数据加工。不同侧重的是应用层只需要关注自己部门的最终业务目标,公共层则需要从企业级的全局一致性、资源经济性上全盘考虑。
公共层与应用层的关系就是后勤部队与前方作战部队的关系,一个负责基础的材料准备工作,一个负责利用这些输出投入到真实战场。公共层是高效的数据复用和综合更低的资源代价,应用层则就是实际的业务需求。所以,最终的业务模型在应用层才有完整的针对性业务场景,在公共层是模型是多种场景业务需求的一个复合,代表了平台最基础和最通用的模型。

从层次上来说,公共层向下是一块整体,负责跟上游多个交易型业务系统对接,对应用集市屏蔽了上游变化带来的影响,使得应用层能只关注于利用公共层的模型解决自己的业务需求。
原文链接
本文为阿里云原创内容,未经允许不得转载。














)




