Adam算法
Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均。Adam算法可以看做是RMSProp算法与动量法的结合。
算法内容
Adam算法使用了动量变量vt\boldsymbol{v}_tvt和RMSProp算法中小批量随机梯度按元素平方的指数加权移动平均变量st\boldsymbol{s}_tst,并在时间步0将它们中每个元素初始化为0。
- 给定超参数0≤β1<10 \leq \beta_1 < 10≤β1<1(算法作者建议设为0.9)
时间步ttt的动量变量vt\boldsymbol{v}_tvt即小批量随机梯度gt\boldsymbol{g}_tgt的指数加权移动平均:
vt←β1vt−1+(1−β1)gt.\boldsymbol{v}_t \leftarrow \beta_1 \boldsymbol{v}_{t-1} + (1 - \beta_1) \boldsymbol{g}_t. vt←β1vt−1+(1−β1)gt.
和RMSProp算法中一样,给定超参数0≤β2<10 \leq \beta_2 < 10≤β2<1(算法作者建议设为0.999), 将小批量随机梯度按元素平方后的项gt⊙gt\boldsymbol{g}_t \odot \boldsymbol{g}_tgt⊙gt做指数加权移动平均得到st\boldsymbol{s}_tst:
st←β2st−1+(1−β2)gt⊙gt.\boldsymbol{s}_t \leftarrow \beta_2 \boldsymbol{s}_{t-1} + (1 - \beta_2) \boldsymbol{g}_t \odot \boldsymbol{g}_t. st←β2st−1+(1−β2)gt⊙gt.
由于我们将v0\boldsymbol{v}_0v0和s0\boldsymbol{s}_0s0中的元素都初始化为0, 在时间步ttt我们得到
vt=(1−β1)∑i=1tβ1t−igi\boldsymbol{v}_t = (1-\beta_1) \sum_{i=1}^t \beta_1^{t-i} \boldsymbol{g}_ivt=(1−β1)i=1∑tβ1t−igi
将过去各时间步小批量随机梯度的权值相加,得到
(1−β1)∑i=1tβ1t−i=1−β1t(1-\beta_1) \sum_{i=1}^t \beta_1^{t-i} = 1 - \beta_1^t(1−β1)i=1∑tβ1t−i=1−β1t
需要注意的是,当ttt较小时,过去各时间步小批量随机梯度权值之和会较小。
例如,当β1=0.9\beta_1 = 0.9β1=0.9时,v1=0.1g1\boldsymbol{v}_1 = 0.1\boldsymbol{g}_1v1=0.1g1。为了消除这样的影响,对于任意时间步ttt,我们可以将vt\boldsymbol{v}_tvt再除以1−β1t1 - \beta_1^t1−β1t,从而使过去各时间步小批量随机梯度权值之和为1。这也叫作偏差修正。在Adam算法中,我们对变量vt\boldsymbol{v}_tvt和st\boldsymbol{s}_tst均作偏差修正:
v^t←vt1−β1t,\hat{\boldsymbol{v}}_t \leftarrow \frac{\boldsymbol{v}_t}{1 - \beta_1^t}, v^t←1−β1tvt,
s^t←st1−β2t.\hat{\boldsymbol{s}}_t \leftarrow \frac{\boldsymbol{s}_t}{1 - \beta_2^t}. s^t←1−β2tst.
接下来,Adam算法使用以上偏差修正后的变量v^t\hat{\boldsymbol{v}}_tv^t和s^t\hat{\boldsymbol{s}}_ts^t,将模型参数中每个元素的学习率通过按元素运算重新调整:
gt′←ηv^ts^t+ϵ,\boldsymbol{g}_t' \leftarrow \frac{\eta \hat{\boldsymbol{v}}_t}{\sqrt{\hat{\boldsymbol{s}}_t} + \epsilon},gt′←s^t+ϵηv^t,
其中η\etaη是学习率,ϵ\epsilonϵ是为了维持数值稳定性而添加的常数,如10−810^{-8}10−8。和AdaGrad算法、RMSProp算法以及AdaDelta算法一样,目标函数自变量中每个元素都分别拥有自己的学习率。最后,使用gt′\boldsymbol{g}_t'gt′迭代自变量:
xt←xt−1−gt′.\boldsymbol{x}_t \leftarrow \boldsymbol{x}_{t-1} - \boldsymbol{g}_t'. xt←xt−1−gt′.
实现Adam优化算法
def get_data_ch7(): data = np.genfromtxt('data/airfoil_self_noise.dat', delimiter='\t')data = (data - data.mean(axis=0)) / data.std(axis=0)return torch.tensor(data[:1500, :-1], dtype=torch.float32), \torch.tensor(data[:1500, -1], dtype=torch.float32) # 前1500个样本(每个样本5个特征)
%matplotlib inline
import torch
import sysfeatures, labels = get_data_ch7()def init_adam_states():v_w, v_b = torch.zeros((features.shape[1], 1), dtype=torch.float32), torch.zeros(1, dtype=torch.float32)s_w, s_b = torch.zeros((features.shape[1], 1), dtype=torch.float32), torch.zeros(1, dtype=torch.float32)return ((v_w, s_w), (v_b, s_b))def adam(params, states, hyperparams):beta1, beta2, eps = 0.9, 0.999, 1e-6for p, (v, s) in zip(params, states):v[:] = beta1 * v + (1 - beta1) * p.grad.datas[:] = beta2 * s + (1 - beta2) * p.grad.data**2v_bias_corr = v / (1 - beta1 ** hyperparams['t'])s_bias_corr = s / (1 - beta2 ** hyperparams['t'])p.data -= hyperparams['lr'] * v_bias_corr / (torch.sqrt(s_bias_corr) + eps)hyperparams['t'] += 1
使用学习率为0.01的Adam算法来训练模型。
def train_ch7(optimizer_fn, states, hyperparams, features, labels,batch_size=10, num_epochs=2):# 初始化模型net, loss = linreg, squared_lossw = torch.nn.Parameter(torch.tensor(np.random.normal(0, 0.01, size=(features.shape[1], 1)), dtype=torch.float32),requires_grad=True)b = torch.nn.Parameter(torch.zeros(1, dtype=torch.float32), requires_grad=True)def eval_loss():return loss(net(features, w, b), labels).mean().item()ls = [eval_loss()]data_iter = torch.utils.data.DataLoader(torch.utils.data.TensorDataset(features, labels), batch_size, shuffle=True)for _ in range(num_epochs):start = time.time()for batch_i, (X, y) in enumerate(data_iter):l = loss(net(X, w, b), y).mean() # 使用平均损失# 梯度清零if w.grad is not None:w.grad.data.zero_()b.grad.data.zero_()l.backward()optimizer_fn([w, b], states, hyperparams) # 迭代模型参数if (batch_i + 1) * batch_size % 100 == 0:ls.append(eval_loss()) # 每100个样本记录下当前训练误差# 打印结果和作图print('loss: %f, %f sec per epoch' % (ls[-1], time.time() - start))set_figsize()plt.plot(np.linspace(0, num_epochs, len(ls)), ls)plt.xlabel('epoch')plt.ylabel('loss')
train_ch7(adam, init_adam_states(), {'lr': 0.01, 't': 1}, features, labels)
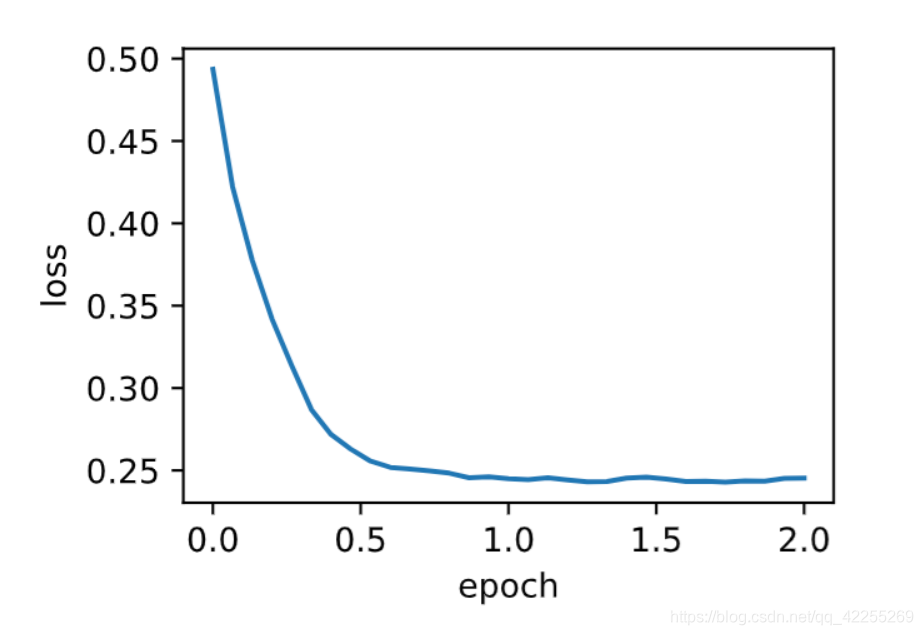
也可以使用pytorch内置的optim.Adam实现:
train_pytorch_ch7(torch.optim.Adam, {'lr': 0.01}, features, labels)




)








)




![python中的[-1]、[:-1]、[::-1]、[n::-1]](http://pic.xiahunao.cn/python中的[-1]、[:-1]、[::-1]、[n::-1])
