1 摘要
在这项工作中,作者对基于深度学习的推荐系统的数据中毒攻击进行了首次系统研究。攻击者的目标是操纵推荐系统,以便向许多用户推荐攻击者选择的目标项目。为了实现这一目标,作者将精心设计的评分注入到推荐系统中的假用户。具体来说,作者将攻击表述为一个优化问题,这样注入的评分将最大化推荐目标项目的普通用户的数量。然而,解决优化问题具有挑战性,因为它是一个非凸整数规划问题。为了应对这一挑战,作者开发了多种技术来近似解决优化问题。作者在三个真实世界数据集(包括小型和大型数据集)上的实验结果表明,作者的攻击是有效的,并且优于现有的攻击。此外,作者试图通过对正常用户和假用户的评分模式进行统计分析来检测假用户。结果表明,即使部署了这样的检测器,作者的攻击仍然有效并且优于现有的攻击。
2 预备知识
2.1 Neural Collaborative Filtering (NCF)
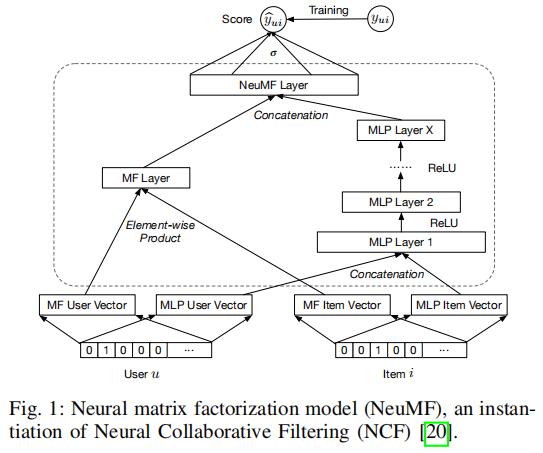
[20] X. He, L. Liao, H. Zhang, L. Nie, X. Hu, and T.-S. Chua, “Neural collaborative filtering,” in Proceedings of the 26th international conference on world wide web. International World Wide Web Conferences Steering Committee, 2017, pp. 173–182.
问:为什么要对用户和项目进行one-hot编码呢?
答:这个地方进行one-hot编码实际上是把用户uuu和项目iii的下标进行one-hot编码,用于利用MF和MLP方法对user-item对进行预测。
问:如何理解这个框架?
答:(1)MF首先随机初始化一个user vector来表示用户uuu,再随机初始化一个item vector来表示项目iii,两个向量进行element-wise product(两个向量的分量对应分别相乘);(2)下图是一个多层感知机MLP,将MLP User Vector和MLP Item Vector作为MLP的输入,输出为一个向量;(3)将MF和MLP的输出拼接起来,作为NeuMF层的输入,最后输出为预测评分y^ui\hat{y}_{ui}y^ui;(4)用真实评分yuiy_{ui}yui作为监督信息来反馈调整MF和MLP。

2.2 对推荐系统的已有攻击方法
数据中毒攻击: 数据中毒攻击将虚假用户注入推荐系统,从而修改推荐列表。
根据数据中毒攻击是否针对特定类型的推荐系统,我们可以将其分为两类:算法不可知(algorithm-agnostic)和算法特定(algorithm-specific)。
算法不可知:典型的就是先令攻击类型,如随机攻击和潮流攻击(bandwagon attacks)。例如,随机攻击只是从整个项目集中为假用户随机选择评分项目,而潮流攻击倾向于为假用户选择数据集中流行度高的某些项目。
算法特定:特定算法的数据中毒攻击针对特定类型的推荐系统进行了优化,并已针对基于图的推荐系统、基于关联规则的推荐系统、基于矩阵分解的推荐系统和基于邻域的推荐系统。随着这些攻击被优化,它们通常更有效。 然而,没有针对基于深度学习的推荐系统的特定算法数据中毒攻击的研究。 我们在本文中弥合了这一差距。
配置文件污染攻击: 配置文件污染攻击的关键思想是通过跨站点请求伪造(CSRF)污染用户的配置文件(例如,历史行为)。 例如,Xing等人对网络服务中的推荐系统提出了配置文件污染攻击,例如 YouTube、亚马逊和谷歌。 他们的研究表明,所有这些服务都容易受到攻击。 然而,配置文件污染攻击有两个关键限制:i) 配置文件污染攻击依赖于 CSRF,这使得难以大规模执行攻击,以及 ii) 配置文件污染攻击不能应用于 item-to-item 推荐系统 因为攻击者无法污染项目的配置文件。
3 问题描述(Problem Formulation)
3.1 威胁模型
攻击目标: 攻击者的目标是使其目标物品出现在尽可能多的普通用户的top-K推荐列表中。(An attacker’s goal is to make its target item appear in the top-K recommendation lists of as many normal users as possible.)
我们注意到,攻击者还可以将目标项目降级,使其出现在尽可能少的普通用户的 top-K 推荐列表中。We note that an attacker could also aim to demote a target item, making it appear in the top-K recommendation lists of as few normal users as possible.
例如,攻击者可能会降低其竞争对手的项目。 由于可以通过提升其他项目来实现降级目标项目,因此我们在这项工作中专注于提升。
攻击背景知识: 我们假设攻击者可以访问用户-项目交互矩阵 Y。在亚马逊和 Yelp 等许多推荐系统中,用户的评分是公开的。 因此,攻击者可以编写爬虫来收集用户的评分。 然而,在我们的实验中,我们还将表明,当攻击者可以访问部分用户-项目交互矩阵时,我们的攻击仍然有效。 攻击者可能会或可能不会访问基于目标深度学习的推荐系统的内部神经网络架构。 当攻击者无法访问目标推荐系统的神经网络架构时,攻击者通过假设一个神经网络架构进行攻击。 正如我们将在实验中展示的那样,我们的攻击可以在不同的神经网络之间转移,即我们基于一种基于神经网络架构的推荐系统构建的攻击对于使用不同神经网络架构的其他推荐系统也是有效的。
攻击者的能力: 我们假设攻击者的资源有限,因此攻击者只能注入有限数量的假用户。 我们用 mmm 表示假用户数量的上限。 除了目标物品外,每个假用户最多可以对 nnn 个其他物品进行评分,以逃避琐碎的检测。 我们称这些项目为填充项目。 具体来说,正常用户往往只对少量物品进行评分,因此对大量物品进行评分的虚假用户是可疑的,很容易被发现。 我们假设攻击者可以将虚假用户的评分注入目标推荐系统的训练数据集中,以操纵深度学习模型的训练过程。
3.2 将攻击制定为优化问题
我们将项目ttt的命中率定义为 HRt\operatorname{HR}_tHRt,表示在其 top-K 推荐列表中会收到项目ttt的普通用户的比例。 换句话说,ttt的命中率表示ttt被推荐给普通用户的概率。 攻击者的目标是最大化目标项目 ttt 的命中率。 让 y(v)\mathbf{y}_{(v)}y(v) 表示假用户 vvv 的评分向量,yviy_{vi}yvi 表示假用户 vvv 给项目 iii 的评分。
我们的目标是为虚假用户制作评分,以使目标项目的命中率最大化。 正式地,根据之前的工作 [13],我们制定了伪造用户的评分来解决以下优化问题:
maxHRtsubject to ∥y(v)∥0≤n+1,∀v∈{v1,v2,…,vm}yvi∈{0,1,…,rmax}(1)\begin{aligned} \max & \operatorname{HR}_{t} \\ \text { subject to } &\left\|\mathbf{y}_{(v)}\right\|_{0} \leq n+1, \forall v \in\left\{v_{1}, v_{2}, \ldots, v_{m}\right\} \\ & y_{v i} \in\left\{0,1, \ldots, r_{\max }\right\} \end{aligned} \tag1 max subject to HRt∥∥y(v)∥∥0≤n+1,∀v∈{v1,v2,…,vm}yvi∈{0,1,…,rmax}(1)
符号说明:
∥y(v)∥0\left\|\mathbf{y}_{(v)}\right\|_{0}∥∥y(v)∥∥0:假用户评分向量y(v)\mathbf{y}_{(v)}y(v)中非0评分的个数;
nnn:填充项目的最大数量;
mmm:假用户的最大数量;
{v1,v2,…,vm}\left\{v_{1}, v_{2}, \ldots, v_{m}\right\}{v1,v2,…,vm}:假用户构成的集合;
rmaxr_{\max}rmax:评分最大等级,如5。
问:如何来理解这个优化公式?
答:该公式就是利用多个假用户的虚假评分使得目标项目ttt的命中率最大化。
4 攻击构建:解决优化问题
4.1 攻击概述
由于公式(1)的优化问题是一个非凸问题,作者开发了多种启发式方法来近似解决优化问题。
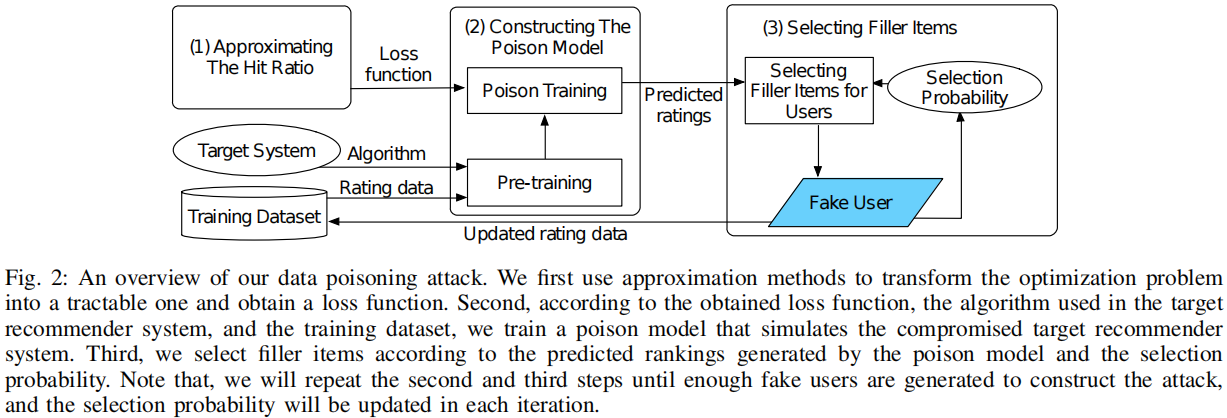
图2描述了数据中毒攻击的过程。
(1) 使用损失函数来近似命中率,其中较小的损失大致对应于较高的命中率。 给定损失函数,将优化问题转化为一个易于处理的问题。
(2)基于设计的损失函数,构建了一个中毒模型来模拟基于深度学习的推荐系统。 特别地,首先预训练中毒模型以确保它可以通过使用验证数据集正确预测用户的偏好,然后使用损失函数更新中毒模型,该损失函数是通过提取损失中与攻击相关的部分导出的在第一步中获得的函数,以接近受损目标推荐系统的预期状态。
(3)根据中毒模型预测的评分向量和选择概率向量为假用户选择填充项,其中项目的选择概率向量会定期更新,以便为下一个假用户选择填充项。 重复第二步和第三步,直到为中毒攻击生成了mmm个假用户。
4.2 详细过程
4.2.1 构建损失函数
又要开始啃公式了。。。。
lu=max{mini∈Lulog[y^ui]−log[y^ut],−κ}(2)l_{u}=\max \left\{\min _{i \in L_{u}} \log \left[\widehat{y}_{u i}\right]-\log \left[\widehat{y}_{u t}\right],-\kappa\right\} \tag2lu=max{i∈Luminlog[yui]−log[yut],−κ}(2)
符号说明:
lul_ulu:用户uuu的损失;
LuL_uLu:推荐给用户uuu的推荐列表;
y^ui\widehat{y}_{ui}yui:用户uuu对项目iii的预测评分;
y^ut\widehat{y}_{ut}yut:用户uuu对项目ttt的预测评分;
κ≥0\kappa \geq 0κ≥0:可调参数,用于增强攻击的鲁棒性和可转移性。
对数运算符的使用减轻了优势效应,同时由于单调性而保留了置信度分数的顺序。
通过最小化损失函数lul_ulu,我们可以有更高的概率将目标项目 ttt 包含在用户 uuu 的推荐列表中。
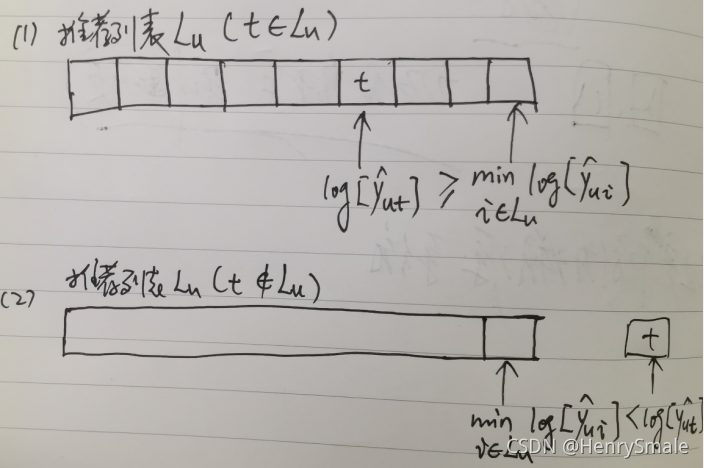
问:怎么来理解这个公式?
答:见下图描述,分为两种情况来讨论:
(1)项目t∈Lut \in L_ut∈Lu,则有mini∈Lulog[y^ui]≤log[y^ut]\min _{i \in L_{u}} \log \left[\widehat{y}_{u i}\right] \leq \log \left[\widehat{y}_{u t}\right]mini∈Lulog[yui]≤log[yut],即mini∈Lulog[y^ui]−log[y^ut]≤0\min _{i \in L_{u}} \log \left[\widehat{y}_{u i}\right] - \log \left[\widehat{y}_{u t}\right] \leq 0mini∈Lulog[yui]−log[yut]≤0,如果κ=0\kappa = 0κ=0,则lu=0l_u = 0lu=0。
(2)项目t∉Lut \notin L_ut∈/Lu,则有mini∈Lulog[y^ui]>log[y^ut]\min _{i \in L_{u}} \log \left[\widehat{y}_{u i}\right] > \log \left[\widehat{y}_{u t}\right]mini∈Lulog[yui]>log[yut],即mini∈Lulog[y^ui]−log[y^ut]>0\min _{i \in L_{u}} \log \left[\widehat{y}_{u i}\right] - \log \left[\widehat{y}_{u t}\right] > 0mini∈Lulog[yui]−log[yut]>0,如果κ=0\kappa = 0κ=0,则lu=mini∈Lulog[y^ui]−log[y^ut]l_u = \min _{i \in L_{u}} \log \left[\widehat{y}_{u i}\right] - \log \left[\widehat{y}_{u t}\right]lu=mini∈Lulog[yui]−log[yut]。
从上面分析来看,κ\kappaκ参数只在情况(1)的时候有用。
由于我们的攻击目标是将目标物品推广给尽可能多的用户,因此我们根据以下公式设计了所有用户的损失函数:
l′=∑u∈Slu(3)l^{\prime}=\sum_{u \in S} l_{u}\tag3l′=u∈S∑lu(3)
符号说明:
SSS: 所有尚未对目标项目ttt 进行评分的普通用户的集合。
在将离散变量松弛为连续变量并逼近命中率后,我们可以将优化问题逼近如下:
minG[y(v)]=∥y(v)∥22+η⋅l′subject to yvi∈[0,rmax](4)\begin{array}{c} \min G\left[\mathbf{y}_{(v)}\right]=\left\|\mathbf{y}_{(v)}\right\|_{2}^{2}+\eta \cdot l^{\prime} \\ \text { subject to } \quad y_{v i} \in\left[0, r_{\max }\right] \end{array}\tag4 minG[y(v)]=∥∥y(v)∥∥22+η⋅l′ subject to yvi∈[0,rmax](4)
符号说明:
η>0\eta > 0η>0: 一个系数,以实现以有限数量的虚假用户评分来提升目标项目ttt的目标;
y(v)\mathbf{y}_{(v)}y(v):虚假用户vvv的评分向量;
G[y(v)]G\left[\mathbf{y}_{(v)}\right]G[y(v)]:虚假用户vvv的评分带来的损失。
在这里,使用 2 范数代替公式 (1)中的 0 范数。为了便于梯度的计算和全局最优值的逐步逼近,因为0范数只能比较有限数量的填充项组合,不能连续变化,而1正则化生成稀疏评分向量,这将 减少虚假用户所选填充项目的多样性。 至于对填充项目数量的限制,可以通过基于最终评分向量 y(v)\mathbf{y}_{(v)}y(v) 为假用户 vvv 选择有限数量的项目来实现。 因此,我们可以通过解决上面的优化问题来生成假用户。
问:又如何理解公式(4)呢?
答:要使得G[y(v)]G\left[\mathbf{y}_{(v)}\right]G[y(v)]最小,即要使得∥y(v)∥22\left\|\mathbf{y}_{(v)}\right\|_{2}^{2}∥∥y(v)∥∥22和∑u∈Slu\sum_{u \in S} l_{u}∑u∈Slu都要小才行。也就是说(1)虚假用户的评分要少;(2)虚假用户的评分使得攻击目标项目ttt以最大概率接近推荐列表。
由于基于深度学习推荐系统中的用户和项目完全具有离散标签,当它们反向传播到输入层时梯度会消失。 因此,直接采用已经应用于攻击图像分类器的反向梯度优化方法是不可行的。 一个自然的想法是将假用户 vvv 的评分向量 y(v)\mathbf{y}_{(v)}y(v)作为自变量,并制定如下中毒攻击:
miny(v)G[y(v),w∗]subject to w∗=argminwL[w,Y∪y(v)](5)\begin{aligned} \min _{\mathbf{y}_{(v)}} & G\left[\mathbf{y}_{(v)}, \mathbf{w}^{*}\right] \\ \text { subject to } & \mathbf{w}^{*}=\underset{\mathbf{w}}{\arg \min } \mathcal{L}\left[\mathbf{w}, \mathbf{Y} \cup \mathbf{y}_{(v)}\right] \end{aligned}\tag5 y(v)min subject to G[y(v),w∗]w∗=wargminL[w,Y∪y(v)](5)
符号系统说明:
w∗\mathbf{w}^{*}w∗:模型参数;
L\mathcal{L}L:训练目标推荐系统的原始损失函数。
问:又如何理解公式(5)呢?
答:我觉得这个公式还是很好理解的,直接翻译公式的话就是:在模型参数w∗\mathbf{w}^{*}w∗下使得损失最小。实际上表达的就是两层意思:(1)虚假用户的评分要少;(2)在增加了虚假用户评分的新数据集Y∪y(v)\mathbf{Y} \cup \mathbf{y}_{(v)}Y∪y(v)上重新训练的损失要小。
作者很快对这个问题的解决来了一瓢冷水:这是一个双层优化问题,因为 w∗\mathbf{w}^{*}w∗ 的下层约束也取决于 y(v)\mathbf{y}_{(v)}y(v)。解决深度学习模型的这个优化问题非常具有挑战性,因为一旦y(v)\mathbf{y}_{(v)}y(v) 发生变化,需要通过重新训练模型来更新模型参数 w∗\mathbf{w}^{*}w∗。这个过程会很耗时,因为如果我们直接计算关于y(v)\mathbf{y}_{(v)}y(v)的高阶梯度,并在我们逐渐更新评分向量y(v)\mathbf{y}_{(v)}y(v)时在每次迭代中对整个数据集重复训练过程,它需要生成足够的假用户。特别是,我们需要大量的迭代,甚至数千次迭代,才能在随机初始化的评分向量上为每个假用户积累足够的变化,这对于现实世界中的大型推荐系统来说是不切实际的。此外,推荐系统使用的评分矩阵通常是稀疏的,在其上训练的神经网络可能会生成在一定范围内变化的预测评分,这将误导基于梯度的优化算法,因为它们的学习量很小,并且很容易干扰模型训练的随机性。
那我们就拭目以待,看看作者想出了什么妙招来解决上述问题吧。
4.2.2 构建中毒模型
具体在这一步中,我们构建了中毒模型,根据获得的损失函数指导每个假用户的填充项选择,以便我们可以有效地构建攻击。在这里,我们从新的角度研究和利用推荐系统本身的特性。对于基于深度学习的推荐系统,作为一种特殊类型的神经网络,它在训练过程中试图减少用户的预测得分向量和真实评分向量之间的熵。直观上,在用户 uuu 的预测评分向量中得分较高的项目比其他项目更有可能在现实中被用户 uuu 以高分评分。如果我们能够成功构建中毒模型来模拟中毒攻击成功后原始推荐系统的预期状态,我们就可以推断出训练数据集中什么样的假用户对当前推荐系统的贡献最大。中毒模型源自初始目标推荐系统,在攻击期间定期更新以逐渐接近我们的攻击目标。然后我们可以使用中毒模型对假用户的偏好进行预测,并选择预测评分最高的项目作为假用户的填充项目。
注意,中毒模型的内部结构和超参数设置与目标推荐系统一致。 而且,它的训练数据集最初应该与目标系统的原始训练数据集相同,并且可以一一插入假用户来模拟攻击结果。 为了使中毒模型朝着我们想要的目标变化,我们需要定义一个有效的损失函数来迭代更新模型。 根据公式(5)中优化问题,我们针对攻击中的中毒模型提出如下损失函数:
l=L+λ⋅G[y^(v)](6)l=\mathcal{L}+\lambda \cdot G\left[\widehat{\mathbf{y}}_{(v)}\right]\tag6l=L+λ⋅G[y(v)](6)
符号系统说明:
L\mathcal{L}L:在训练原始推荐系统过程中选择的损失函数,例如整个训练数据集的二元交叉熵;
G[y^(v)]G\left[\widehat{\mathbf{y}}_{(v)}\right]G[y(v)]:与我们的攻击目标密切相关;
λ>0\lambda > 0λ>0:一个在模型有效性和攻击目标之间权衡的系数,它允许我们生成接近正常情况下训练的推荐系统的中毒模型,同时实现我们的攻击目标。
在这里,有效性与L\mathcal{L}L 相关并衡量模型准确预测用户对验证数据集偏好的程度。我们使用假用户 vvv 的预测评分向量 y^(v)\widehat{\mathbf{y}}_{(v)}y(v)来替换 vvv 的真实评分向量 y(v)\mathbf{y}_{(v)}y(v),这样我们就可以避免非常耗时的高阶梯度计算。请注意,如果中毒模型的有效性远低于使用相同数据集和原始损失函数(即L\mathcal{L}L)正常训练的模型的有效性,则中毒模型不太可能接近受感染的最终状态目标推荐系统,因为目标推荐系统将始终使用验证数据集来保证其在正常模型训练过程中的最佳性能。因此,有必要在攻击过程中保证中毒模型的有效性。为了使中毒模型更好地模拟中毒攻击的结果,我们设计了两个训练阶段:即预训练和中毒训练。
预训练: 中毒模型将首先随机初始化,并在其训练数据集上使用与目标推荐系统相同的损失函数(即 L\mathcal{L}L)进行训练。 经过足够的迭代,中毒模型会和正常训练得到的推荐系统相似,保证了模型的有效性。 我们可以利用这个模型随后开始中毒训练。
中毒训练: 此阶段的中毒模型将使用公式(6)作为损失函数,并使用反向传播方法对其内部的所有模型参数进行重复训练。 我们选择初始 λ\lambdaλ,使得验证数据集上中毒模型的损失和对攻击有效性建模的损失大致处于同一数量级。 在训练过程中,中毒模型会越来越接近我们的攻击目标,最终成为目标推荐系统的理想状态。 然后我们可以使用中毒模型来帮助虚假用户的项目选择过程。
4.2.3 选择填充项目
现在我们可以根据上次中毒训练过程中获得的最终中毒模型生成的预测评分为每个假用户选择填充项。 请注意,推荐系统给出的用户预测评分向量中得分较高的项目往往与用户具有更大的相关性,因为系统在训练过程中减少了用户预测评分向量和真实评分向量之间的熵。 因此,只要我们得到一个合理的中毒模型,我们就可以根据模型得到假用户 vvv 的预测评分向量 y^(v)\widehat{\mathbf{y}}_{(v)}y(v),并且将选择目标项 ttt 以外的 top-n 项作为假用户vvv的填充项。
然而,由于推荐系统中使用的数据集通常非常稀疏,并且从数据中训练出来的模型具有很高的随机性,基于深度学习的推荐系统针对特定用户和物品的推荐结果往往不稳定,这意味着从数据中获得的假用户 中毒模型可能不是很好的选择。 因此,如果我们总是直接使用中毒模型的预测来为假用户选择填充项,我们更有可能逐渐偏离正确的方向。 为了避免这种情况,我们开发了一个选择概率的概念,即一个项目被选为填充项目的概率。 我们将选择概率向量定义为 p={p1,p2,…,pN}\mathbf{p}=\left\{p_{1}, p_{2}, \ldots, p_{N}\right\}p={p1,p2,…,pN},其中的每个元素代表对应项目的选择概率。 如果选择第iii 项作为填充项,则 pip_ipi 将发生如下变化:
pi=pi⋅δ(7)p_{i}=p_{i} \cdot \delta \tag7pi=pi⋅δ(7)
符号系统说明:
0≤δ≤10 \leq \delta \leq 10≤δ≤1:降低所选项目的选择概率的衰减系数。
一个项目被选择作为填充项目的次数越多,它的选择概率就越低。 请注意,p\mathbf{p}p 首先被初始化为一个所有元素值为 1.0 的向量。 如果中毒攻击后 p\mathbf{p}p 中的所有元素都低于 1.0,则 p\mathbf{p}p 将再次初始化。
在中毒模型为假用户 vvv 给出预测评分向量 y^(v)\widehat{\mathbf{y}}_{(v)}y(v)后,我们将其与 p\mathbf{p}p 结合以指导填充项选择,如下所示:
rv=y^(v)pT(8)\mathbf{r}_{v}=\widehat{\mathbf{y}}_{(v)} \mathbf{p}^{\mathrm{T}} \tag8 rv=y(v)pT(8)
根据公式(8),我们选择在 rv\mathbf{r}_{v}rv 中得分最高的项目作为假用户 vvv 的填充项目,并使用公式(7)更新相应的选择概率。选择概率的使用避免了特定项目的重复选择,并为更多候选项目提供了更大的被选中机会,这允许目标项目与更多其他项目建立潜在的相关性,使我们的攻击更有可能在全局范围内有效。 对于数据集较稀疏的推荐系统,推荐结果的不确定性较大,我们建议选择较小的δ\deltaδ来加强系统内部的连通性,即目标项目可以关联更多的其他项目,避免局部最优结果,提高 攻击性能。 结合以上见解,我们可以有效地解决优化问题。
解决优化问题的启发式方法如算法 1 所示。请注意,由于我们的攻击不针对特定的深度学习推荐系统,可以推广到任何基于深度学习的推荐系统。

我们的项目选择遵循三个步骤。
首先,我们使用中毒模型来预测假用户 vvv 的评分向量 y^(v)\widehat{\mathbf{y}}_{(v)}y(v)。
其次,我们计算 y^(v)\widehat{\mathbf{y}}_{(v)}y(v) 和选择概率向量 p\mathbf{p}p 的元素乘积作为调整后的评分向量 rv\mathbf{r}_{v}rv 。
第三,我们选择具有最大调整评级分数的 nnn 个非目标项目作为 vvv 的填充项目。
对于 vvv 的每个填充项目 iii,我们通过乘以常数(例如,0.9)来降低其选择概率 pip_ipi,使得它不太可能被其他假用户选为填充项。我们使用选择概率向量来增加假用户填充项目的多样性,以便目标项目可以潜在地与更多项目相关联。请注意,我们假设每个假用户使用相同的 nnn。但是,攻击者也可以为不同的假用户使用不同数量的填充项。特别是,攻击者可以使用我们的攻击为假用户一个一个地添加填充项,一旦目标项的命中率开始下降就停止添加填充项。最后,我们根据之前拟合的正态分布为每个填充项生成评分,以确保它们的评分与其他正态评分非常相似,这也可用于有效规避检测。我们将在第六节详细说明检测性能。请注意,为了加快生成所有假用户的过程,我们也可以选择每次生成 s(s>1)s (s > 1)s(s>1) 个假用户,代价是降低对攻击有效性的细粒度控制。
问:如何来理解算法1?
答:实际上通过算法1我们可以大致了解作者具体攻击的过程。我们以矩阵分解来这个攻击过程:
对每一个虚假用户做如下操作:
(1)初始化攻击模型MpM_pMp,假设YM×N≈UM×kVN×kT\mathbf{Y}_{M \times N} \approx U_{M \times k} V_{N \times k}^TYM×N≈UM×kVN×kT,增加了mmm个虚假用户后,[Y∪y(v)](M+m)×N≈U(M+m)×kVN×kT[\mathbf{\mathbf{Y} \cup \mathbf{y}_{(v)}}]_{(M+m) \times N} \approx U_{(M+m) \times k} V_{N \times k}^T[Y∪y(v)](M+m)×N≈U(M+m)×kVN×kT;
(2)增加(v,t,rmax)\left(v, t, r_{\max }\right)(v,t,rmax)到Y\mathbf{Y}Y,即每个虚假用户都将目标项目ttt的评分设置为rmaxr_{\max }rmax(我觉得这一步很关键);
(3)使用 L\mathcal{L}L 在 Y\mathbf{Y}Y 上预训练 MpM_pMp;
(4)重新训练[Y∪y(v)](M+m)×N≈U(M+m)×kVN×kT[\mathbf{\mathbf{Y} \cup \mathbf{y}_{(v)}}]_{(M+m) \times N} \approx U_{(M+m) \times k} V_{N \times k}^T[Y∪y(v)](M+m)×N≈U(M+m)×kVN×kT得到最终的MpM_pMp;
问:第(3)步和第(4)步的区别是什么?
答:这两步最大的区别就是使用的损失函数不同,第(3)步使用矩阵分解的常规loss;而第(4)步采用的公式(6)对应的loss
(5)用MpM_pMp预测用户对所有项目的评分,得到评分向量y^(v)\widehat{\mathbf{y}}_{(v)}y(v);
(6)利用公式(8)来计算rvr_vrv;
(7)选择 rv\mathbf{r}_vrv 中 nnn个分数最高的 ttt 以外的这些项作为填充项;
(8)利用公式(7)更新 p\mathbf{p}p ;(说实话,这一步我也不知道怎么更新的)
(9)为选定的填充项生成评分,构成用户 vvv 的评分向量 y(v)\mathbf{y}_{(v)}y(v);
(10)Y←Y∪y(v)\mathbf{Y} \leftarrow \mathbf{Y} \cup \mathbf{y}_{(v)}Y←Y∪y(v)。
接下来就是代码实现这个论文的idea。Fighting ~~
)










原理)
)


元组和列表的区别)


)
