推荐系统–矩阵分解(1)
推荐系统–矩阵分解(2)
推荐系统–矩阵分解(3)
推荐系统–矩阵分解(4)
推荐系统–矩阵分解(5)
推荐系统–矩阵分解(6)
3 BiasSVD:考虑偏置
有一些用户会给出偏高的评分,有一些物品也会收到偏高的评分,比如电影观众为铁粉,一些受某时期某事件影响的电影。所以需要考虑偏置对评分的影响,其公式如下:
L(θ)=argmin⏟pu,qi∑u,i(rui−μ−bu−bi−puTqi)2+λ(∥pu∥22+∥qi∥22+∥bu∥22+∥bi∥22)(4)\begin{aligned} L(\theta)=\underbrace{\arg \min }_{p_{u}, q_{i}} \sum_{u, i}\left(r_{u i}-\mu-b_{u}-b_{i}-p_{u}^{T} q_{i} \right)^{2} \\ +\lambda\left(\left\|p_{u}\right\|_{2}^{2}+\left\|q_{i}\right\|_{2}^{2}+\left\|b_{u}\right\|_{2}^{2}+\left\|b_{i}\right\|_{2}^{2}\right) \end{aligned} \tag4L(θ)=pu,qiargminu,i∑(rui−μ−bu−bi−puTqi)2+λ(∥pu∥22+∥qi∥22+∥bu∥22+∥bi∥22)(4)
符号说明:
用户的预测评分为:rui^=puTqi+μ+bu+bi\hat{r_{ui}} = p_{u}^T q_{i} + \mu + b_{u} + b_{i}rui^=puTqi+μ+bu+bi;
偏差为:eui=rui−rui^e_{ui}=r_{ui}-\hat{r_{ui}}eui=rui−rui^;
μ\muμ:训练集中所有评分记录的全局平均数,表示了训练数据的总体评分情况,对于固定的数据集,它是一个常数;
bub_ubu:用户uuu的偏置,独立于物品特征的因素,表示某一特定用户的打分习惯。例如,对于批判性用户对于自己的评分比较苛刻,倾向于打低分;而乐观型用户则打分比较保守,总体打分要偏高;
bib_ibi:物品iii的偏置,特立于用户兴趣的因素,表示某一特定物品得到的打分情况。以电影为例,好片获得的总体评分偏高,而烂片获得的评分普遍偏低,物品偏置捕获的就是这样的特征。
对公式(4)求偏导,理后可以得到迭代公式为:
pu,k=pu,k+η(euiqk,i−λpu,k)qk,i=qk,i+η(euipu,k−λqi,k)bu=bu+η(eui−λbu)bi=bi+η(eui−λbi)(5)\begin{aligned} p_{u, k} &=p_{u, k}+\eta\left(e_{u i} q_{k, i}-\lambda p_{u, k}\right) \\ q_{k, i} &=q_{k, i}+\eta\left(e_{u i} p_{u, k}-\lambda q_{i, k}\right) \\ b_{u} &=b_{u}+\eta\left(e_{ui} -\lambda b_{u}\right) \\ b_{i} &=b_{i}+\eta\left(e_{ui} -\lambda b_{i}\right) \end{aligned} \tag5 pu,kqk,ibubi=pu,k+η(euiqk,i−λpu,k)=qk,i+η(euipu,k−λqi,k)=bu+η(eui−λbu)=bi+η(eui−λbi)(5)
4 SVD++:增加历史行为
通过观看B站上的视频,终于把SVD++核心思想搞清楚了:
- 它是来探索物品与物品之间关联关系的,比如对逃学威龙1评分高的人,可能也会给逃学威龙2高评分;
- 由于需要探索物品与物品之间的关联关系,可以使用显式反馈,也可以使用显式反馈+隐式反馈;
- 利用隐式反馈来探索物品与物品之间的关联关系,信息更加丰富:少数用户会主动点评电影或者美食,大多数用户只会浏览或者观看,也就是说显式反馈比隐式反馈少。
SVD++模型的步骤如下:
- 对于某一个用户uuu,它提供了反馈的物品集合定义为N(u)N(u)N(u);
- 假设j∈N(u)j \in N(u)j∈N(u),该物品jjj和预测物品iii之间的关系为wijw_{ij}wij;
- 将这个关系作为预测评分的一个部分,则有如下公式:
rui^=μ+bu+bi+puTqi+1∣N(u)∣∑j∈N(u)wij(6)\begin{aligned} \hat{r_{ui}}=\mu+b_{u}+b_{i}+p_{u}^T q_{i} + \frac{1}{\sqrt{|N(u)|}} \sum_{j \in N(u)}w_{ij} \tag6 \end{aligned} rui^=μ+bu+bi+puTqi+∣N(u)∣1j∈N(u)∑wij(6)
引入1∣N(u)∣\frac{1}{\sqrt{|N(u)|}}∣N(u)∣1是为了消除不同∣N(u)∣|N(u)|∣N(u)∣个数引起的差异。
WWW矩阵如下表所示:
| t1t_1t1 | t2t_2t2 | t3t_3t3 | t4t_4t4 | |
|---|---|---|---|---|
| t1t_1t1 | w11w_{11}w11 | w12w_{12}w12 | w13w_{13}w13 | w14w_{14}w14 |
| t2t_2t2 | w21w_{21}w21 | w22w_{22}w22 | w23w_{23}w23 | w24w_{24}w24 |
| t3t_3t3 | w31w_{31}w31 | w32w_{32}w32 | w33w_{33}w33 | w34w_{34}w34 |
| t4t_4t4 | w41w_{41}w41 | w42w_{42}w42 | w43w_{43}w43 | w44w_{44}w44 |
- WWW矩阵维度为n×nn \times nn×n,维度很大,我们对WWW进行矩阵分解后得到如下公式:
rui^=μ+bu+bi+puTqi+1∣N(u)∣xuT∑j∈N(u)yj(7)\begin{aligned} \hat{r_{ui}}=\mu+b_{u}+b_{i}+p_{u}^{T} q_{i} + \frac{1}{\sqrt{|N(u)|}} x_u^T \sum_{j \in N(u)}y_{j} \tag7 \end{aligned} rui^=μ+bu+bi+puTqi+∣N(u)∣1xuTj∈N(u)∑yj(7)

- xux_uxu表示用户的隐向量,可以用pup_upu替换,这样就减少了对WWW矩阵的分解,则上式可以表示为:
rui^=μ+bu+bi+puTqi+1∣N(u)∣puT∑j∈N(u)yj=μ+bu+bi+puT(qi+1∣N(u)∣∑j∈N(u)yj)(10)\begin{aligned} \hat{r_{ui}}=\mu+b_{u}+b_{i}+p_{u}^{T} q_{i} + \frac{1}{\sqrt{|N(u)|}} p_u^T \sum_{j \in N(u)}y_{j} \\ = \mu+b_{u}+b_{i}+p_{u}^{T} \left(q_{i} + \frac{1}{\sqrt{|N(u)|}} \sum_{j \in N(u)}y_{j}\right)\tag{10} \end{aligned} rui^=μ+bu+bi+puTqi+∣N(u)∣1puTj∈N(u)∑yj=μ+bu+bi+puT⎝⎛qi+∣N(u)∣1j∈N(u)∑yj⎠⎞(10)
其优化目标函数:
L(θ)=argmin⏟pu,qi∑u,i(rui−μ−bu−bi−puTqi−puT1∣N(u)∣∑j∈N(u)yj)2+λ(∥pu∥22+∥qi∥22+∥bu∥22+∥bi∥22+∑j∈N(u)∥yj∥22)(11)\begin{aligned} L(\theta) = \underbrace{\arg \min }_{p_{u}, q_{i}} \sum_{u, i}\left(r_{ui}-\mu-b_{u}-b_{i}-p_{u}^{T} q_{i} -p_{u}^{T} \frac{1}{\sqrt{|N(u)|}} \sum_{j \in N(u)} y_{j}\right)^{2} \\ +\lambda\left(\left\|p_{u}\right\|_{2}^{2}+\left\|q_{i}\right\|_{2}^{2}+\left\|b_{u}\right\|_{2}^{2}+\left\|b_{i}\right\|_{2}^{2}+\sum_{j \in N(u)}\left\|y_{j}\right\|_{2}^{2}\right) \end{aligned} \tag{11} L(θ)=pu,qiargminu,i∑⎝⎛rui−μ−bu−bi−puTqi−puT∣N(u)∣1j∈N(u)∑yj⎠⎞2+λ⎝⎛∥pu∥22+∥qi∥22+∥bu∥22+∥bi∥22+j∈N(u)∑∥yj∥22⎠⎞(11)
对公式(11)求偏导,令eui=rui−rui^e_{ui}=r_{ui}- \hat{r_{ui}}eui=rui−rui^,整理后可以得到迭代公式:
bu=bu+η⋅(eui−λ⋅bu)bi=bi+η⋅(eui−λ⋅bi)pu=pu+η⋅(eui⋅qi−λ⋅pu)qi=qi+η⋅(eui(pu+1∣N(u)∣∑j∈N(u)yj)−λ⋅qi)yj=yj+η⋅(eui⋅1∣N(u)∣qi−λ⋅qi)(12)\begin{aligned} b_u = b_u + \eta \cdot (e_{ui} - \lambda \cdot b_u) \\ b_i = b_i + \eta \cdot (e_{ui} - \lambda \cdot b_i) \\ p_u = p_u + \eta \cdot (e_{ui} \cdot q_i - \lambda \cdot p_u) \\ q_i = q_i + \eta \cdot (e_{ui}(p_u + \frac{1}{\sqrt{|N(u)|}}\sum_{j \in N(u)} y_j) - \lambda \cdot q_i) \\ y_j = y_j + \eta \cdot (e_{ui} \cdot \frac{1}{\sqrt{|N(u)|}} q_i - \lambda \cdot q_i) \\ \end{aligned} \tag{12} bu=bu+η⋅(eui−λ⋅bu)bi=bi+η⋅(eui−λ⋅bi)pu=pu+η⋅(eui⋅qi−λ⋅pu)qi=qi+η⋅(eui(pu+∣N(u)∣1j∈N(u)∑yj)−λ⋅qi)yj=yj+η⋅(eui⋅∣N(u)∣1qi−λ⋅qi)(12)
参考的迭代公式如下:
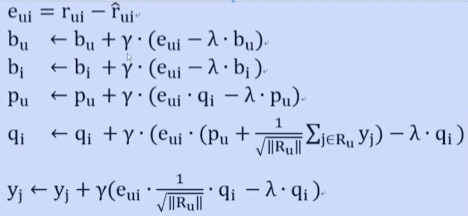


)

)

)

)





)
)

)

)