参考论文:Deep Leakage from Gradients(NeurIPS 2019)
源代码: https://github.com/mit-han-lab/dlg
核心思想:作者通过实验得到,从梯度可以反推用户的个人信息。并验证了其在计算机视觉和自然语言处理任务中的有效性。
攻击场景:攻击者可以获得全局模型的结构和参数,通过模型反演或梯度泄漏来恢复本地数据。
缺点:只能恢复一张图片,当batch大于1时,此方法效果无效。
1 问题定义
图1说明了通过训练可以很容易计算出梯度,然而梯度不能非常直观的表现样本的特征。也就是说,通过原始数据值,人是很难知道图片表示的是猫。

图2说明了两种不同的联邦学习。服务器忠实地聚合来自参与者的更新并将更新后的模型传回,但它可能对参与者信息感到好奇并试图从收到的更新中揭示它。在下面的讨论中,不失一般性地使用了基于梯度的聚合。 我们关心可以从梯度中推断出什么样的信息。 这种攻击发生在集中式联邦学习的参数服务器(图 2a)或分散式联邦学习中的任何邻居(图 2b)中。
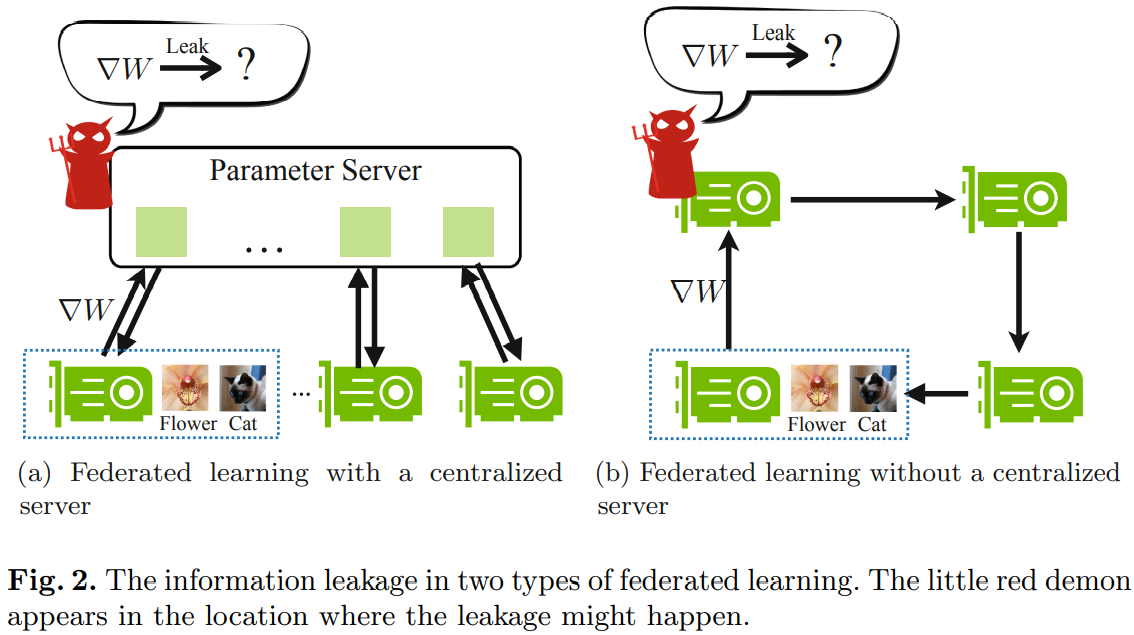
图3说明了联合设置中的成员推断。 它使用预测结果和真实标签来推断记录是在受害者训练数据集中还是在受害者训练数据集之外。在实践中,Melis 等人 [7] 表明恶意攻击者可以令人信服地(精度 0.99)判断是否使用特定位置配置文件来训练 FourSquare 位置数据集 [8] 上的性别分类器(图 3)。

图4说明了属性推断,推断受害者的训练集是否包含具有特定属性的数据点。

图5说明了联合设置中的模型反转。 它首先从模型更新和攻击者自己的训练数据训练 GAN 模型。 然后它使用 GAN 模型从受害者的更新中生成相似的图像。

图6说明了联合设置中的深度泄漏。 给定从受害者那里收到的模型更新/梯度,它旨在保留梯度并完全重建私有训练集。

2 攻击方法
攻击者将样本和标签看做是参数,将梯度看做是要拟合的值。
图7描述了DLG 算法概述。 要更新的变量用粗体边框标记。 当正常参与者使用其私人训练集计算 ∇W∇W∇W 以更新参数时,恶意攻击者更新其虚拟输入和标签以最小化梯度距离。 优化完成后,恶意用户可以从诚实的参与者那里窃取训练集。
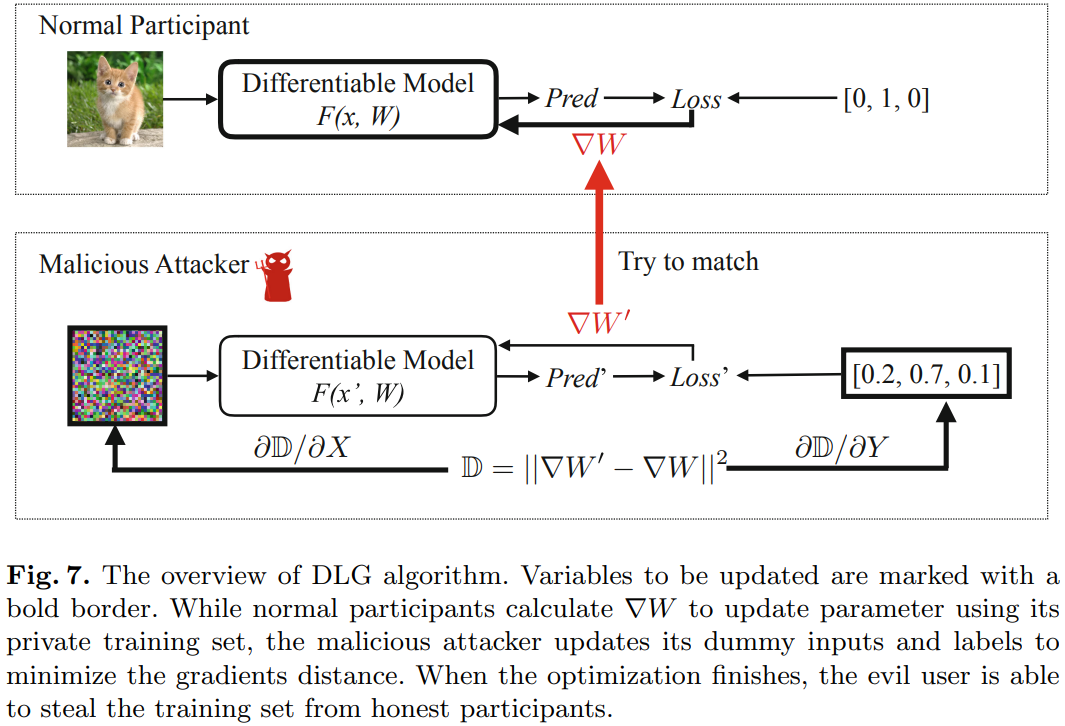
正常参与者的步骤:
- 输入样本;
- 样本通过网络,输出预测值;
- 根据样本的预测值和真实值,计算损失函数,并且通过反向传播来计算梯度;
- 更新参数.
攻击者的步骤:
- 随机生成一个同样维度大小的输入,同时随机生成一个标签值;
- 类似Normal Participant中的2和3,将样本输入网络,此时我们也能得到一个梯度;
- 使得通过随机样本计算得到的梯度,接近用户上传的梯度;
- 得到了一个目标函数:
x′∗,y′∗=argminx′,y′∥∇W′−∇W∥2=argminx′,y′∥∂ℓ(F(x′,W),y′)∂W−∇W∥2\begin{aligned} \mathbf{x}^{\prime *}, \mathbf{y}^{\prime *} &=\arg \min _{\mathbf{x}^{\prime}, \mathbf{y}^{\prime}}\left\|\nabla W^{\prime}-\nabla W\right\|^{2} \\ &=\arg \min _{\mathbf{x}^{\prime}, \mathbf{y}^{\prime}}\left\|\frac{\partial \ell\left(F\left(\mathbf{x}^{\prime}, W\right), \mathbf{y}^{\prime}\right)}{\partial W}-\nabla W\right\|^{2} \end{aligned} x′∗,y′∗=argx′,y′min∥∇W′−∇W∥2=argx′,y′min∥∥∥∥∂W∂ℓ(F(x′,W),y′)−∇W∥∥∥∥2

初始化虚拟输入和标签;
计算虚拟梯度;
更新数据匹配梯度;
更新标签匹配梯度。
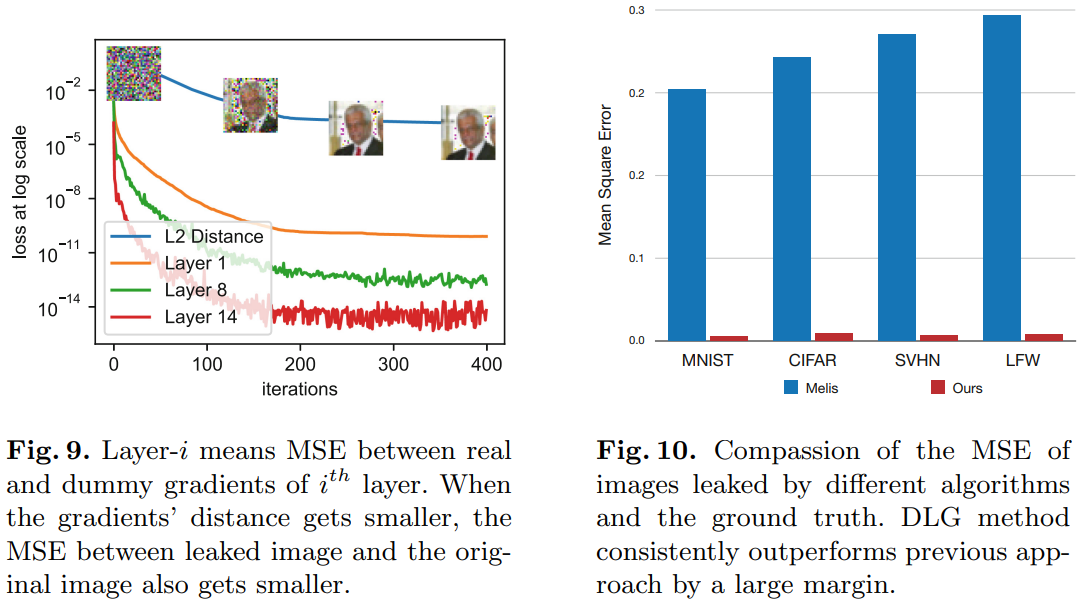
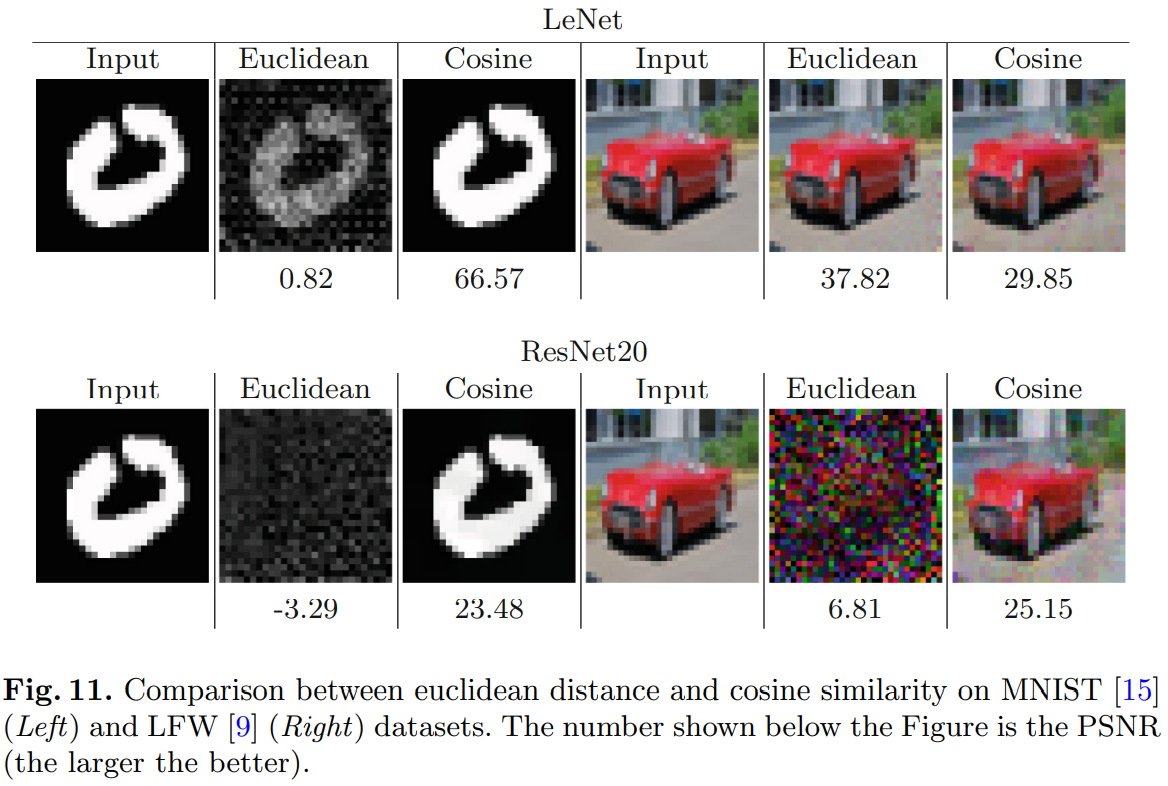
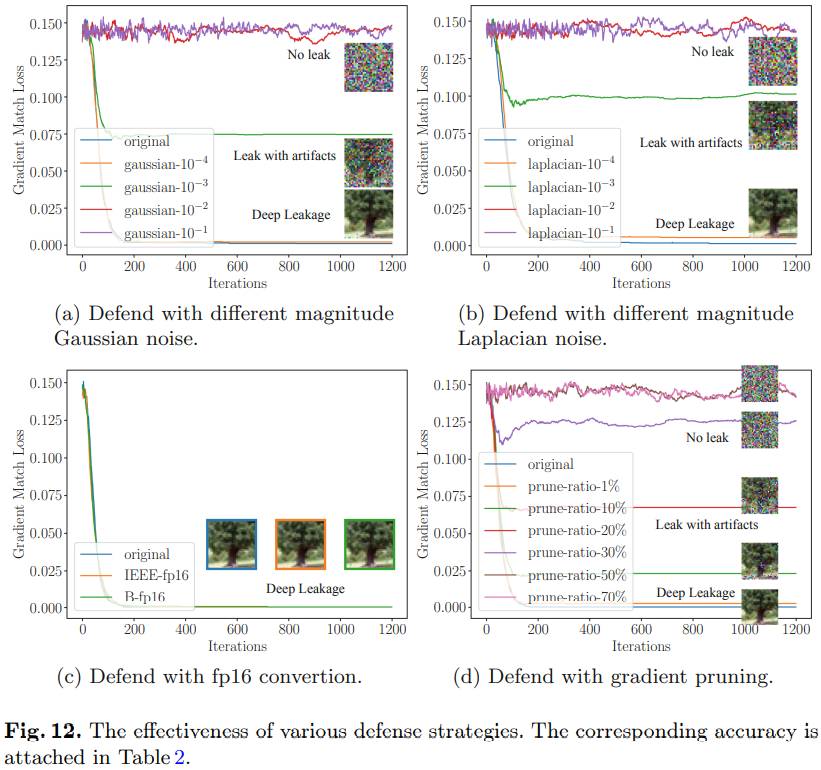
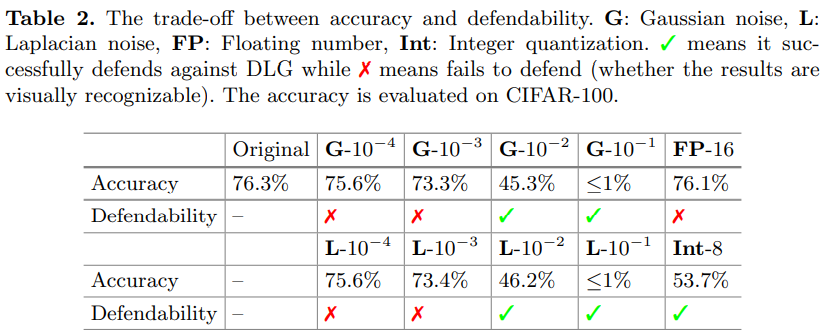
3 攻击效果



)

)

)

)

)




)
)


)
