
我们知道,当我们训练机器学习或深入学习模型时,我们必须保存训练过的模型,以便将来进行预测。现在的训练模型非常昂贵,所以如果我们能够保存它们并将其用于解决其他一些问题。例如,一个训练过的能够识别汽车的神经网络,可以用迁移学习方法对其进行微调后用于识别卡车。
在数据库中保存模型并使用python加载它们是很容易的。我们选择MongoDB是因为它是一个开源的文档数据库和领先的NoSQL数据库。现在让我们使用python逐步实现这个过程。
首先,使用pip安装pymongo,如下所示,
pip install pymongo
如果要使用MongoDB,请确保在系统中安装了MongoDB。
我们将首先在iris数据集上训练xgboost模型,然后将其转储到数据库中并将其加载回来并用于预测。导入Python库,如下所示:
#importing important librariesimport pymongoimport pandas as pdimport numpy as npfrom sklearn import datasetsimport pickleimport timeimport pymongo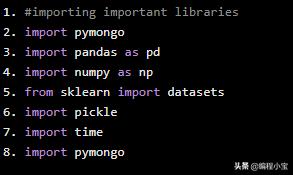
现在我们将在iris数据集上训练xgboost
iris = datasets.load_iris()X = iris.datay = iris.targetfrom sklearn.cross_validation import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)from xgboost import XGBClassifierxgb = XGBClassifier()xgb.fit(X_train, y_train)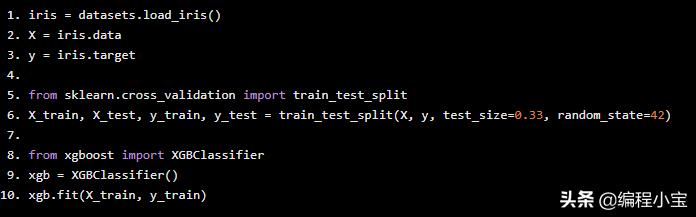
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,
max_depth=3, min_child_weight=1, missing=None, n_estimators=100,
n_jobs=1, nthread=None, objective='multi:softprob', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1)
训练结束后,我们将编写一个辅助函数来保存机器学习模型,该机器学习模型将首先对模型进行pickle。Pickling只是将任何对象转换为字节。我们必须pickle我们的模型,因为我们不能直接将对象保存到MongoDB中。此函数还创建连接、数据库和collection,然后使用名称保存模型。
def save_model_to_db(model, client, db, dbconnection, model_name): import pickle import time import pymongo #pickling the model pickled_model = pickle.dumps(model) #saving model to mongoDB # creating connection myclient = pymongo.MongoClient(client) #creating database in mongodb mydb = myclient[db] #creating collection mycon = mydb[dbconnection] info = mycon.insert_one({model_name: pickled_model, 'name': model_name, 'created_time':time.time()}) print(info.inserted_id, ' saved with this id successfully!') details = { 'inserted_id':info.inserted_id, 'model_name':model_name, 'created_time':time.time() } return details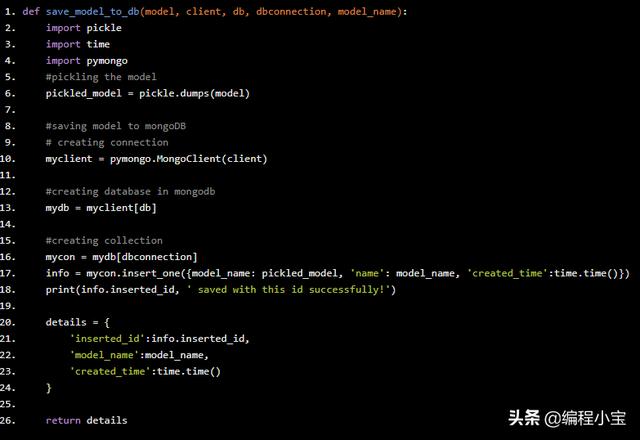
现在我们将编写另一个辅助函数来加载保存的机器学习模型。这个函数首unpickles保存的模型,然后返回模型。在这里,我们使用find()函数并传递它的模型名来从数据库中获取模型。
def load_saved_model_from_db(model_name, client, db, dbconnection): json_data = {} #saving model to mongoDB # creating connection myclient = pymongo.MongoClient(client) #creating database in mongodb mydb = myclient[db] #creating collection mycon = mydb[dbconnection] data = mycon.find({'name': model_name}) for i in data: json_data = i #fetching model from db pickled_model = json_data[model_name] return pickle.loads(pickled_model)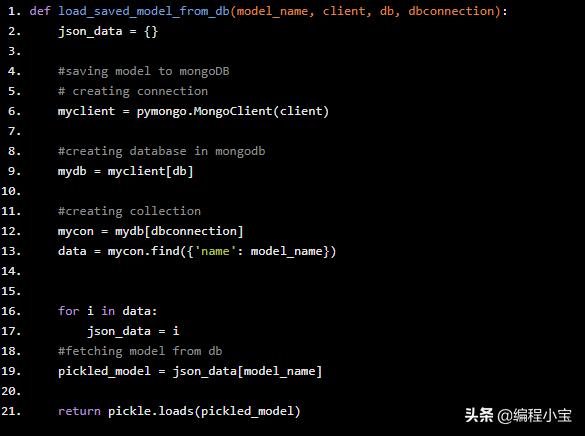
在编写用于保存和加载模型的辅助函数之后,我们只需要调用它们,如下所示
#saving model to mongodetails = save_model_to_db(model = xgb, client ='mongodb://localhost:27017/', db = 'mydatabase', dbconnection = 'customers', model_name = 'myxgb')#fetching model from mongoxgb = load_saved_model_from_db(model_name = details['model_name'], client = 'mongodb://localhost:27017/', db = 'mydatabase', dbconnection = 'customers')print(xgb.predict(X_test))
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1 0 0 0 2 1 1 0 0 1 1 2 1 2]
使用python可以轻松地在数据库中保存和加载模型。保存这些模型后,我们可以在将来随时使用它们。




)






![[学习记录] macOS下的Nginx安装 Nginx基本知识](http://pic.xiahunao.cn/[学习记录] macOS下的Nginx安装 Nginx基本知识)



)
、选择重传协议(SR))

)
