
点击关注,我们共同每天进步一点点!
前言
本意,昨晚想发一文,在梳理思路找笔记一小半时,一朋友跟伴侣吵架了,突然从技术写文转变到情感“砖家”,微信聊了一个多小时,脑力都用光了,早上开会上传了一下调整后的代码,中午补一下文,完成既定目标。
一、起因
去年在测试公司的人工智能产品中的一功能【成语接龙】,人工语音测试总玩不过【琥珀】小姐姐,叹自身知识匮乏、小琥珀之刁钻;
于是乎,网络找了几个成语数据库,找了几个现成的API,弄成自动化跑的时,自信满满时,【琥珀】却找出大量的非四字成语;
脏数据太多,很有挫败感,于是另谋出路,百度成语相对靠谱,就你了,本文为很简单的测试,主要看测试思路。
二、百度成语HTML解析
2.1、浏览器打开百度成语
https://hanyu.baidu.com/s?wd=成语
2.2、分析HTML与规律
步骤:1、正常请求--》2、抓包分析--》3、模拟请求--》不成功---》4、抓包对比分析
所有基本就是循环以上步骤直至成功为止(反爬另说,主要是变换请求信息,伪装不同的用户请求)。
2.2.1)、正常请求:略
2.2.2)、抓包分析
实操如下,很容易就找到规律,图1图2一对比,就可以找到变化的内容
请求地址:https://hanyu.baidu.com/hanyu/ajax/search_list?wd=%E6%88%90%E8%AF%AD&from=poem&pn=页数&_=点击时间戳说明:忽略cookie,实测不需要,也没有反爬机制,但本文还是会保存cookie请求
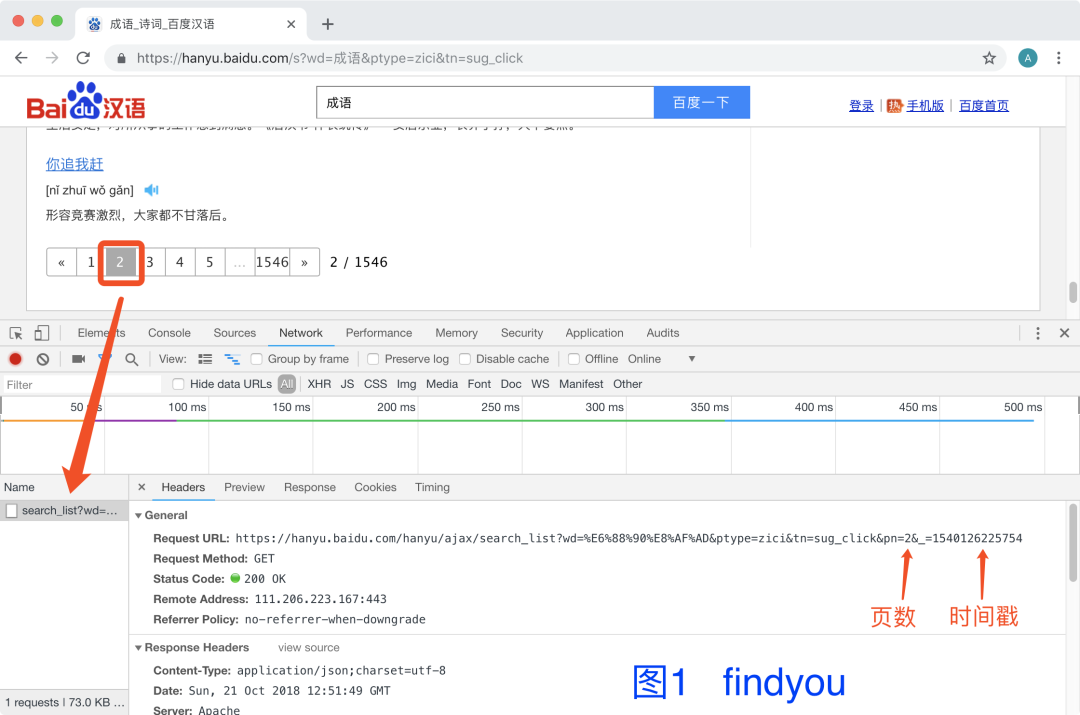
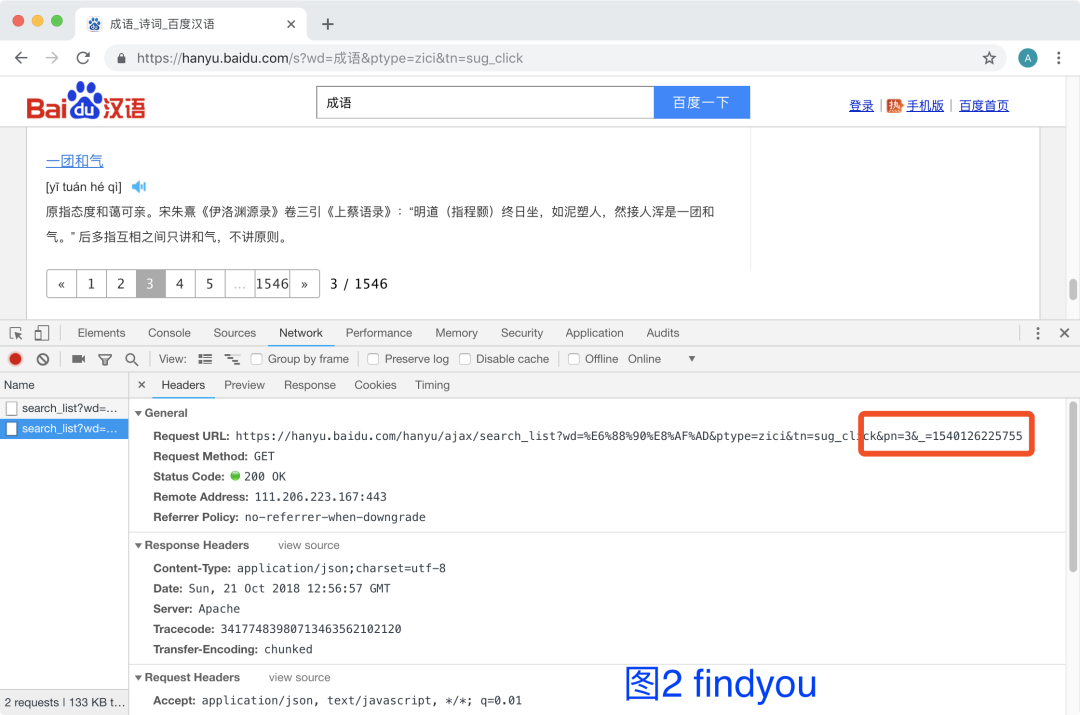
数据标签分析
将抓包的数据,拷贝,在线Json格式化,可以得到比较好看的结构:
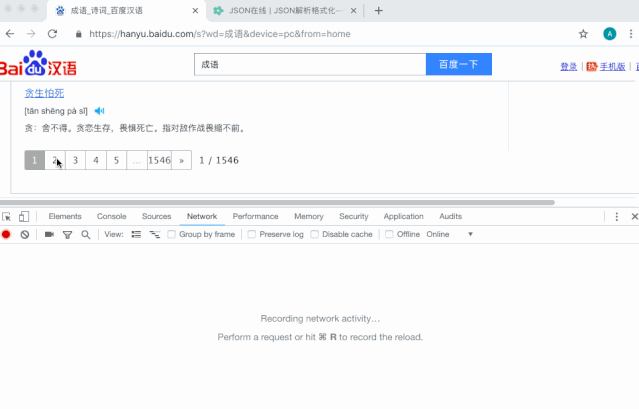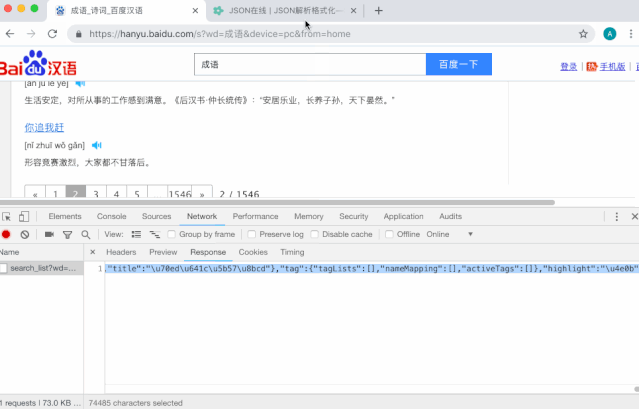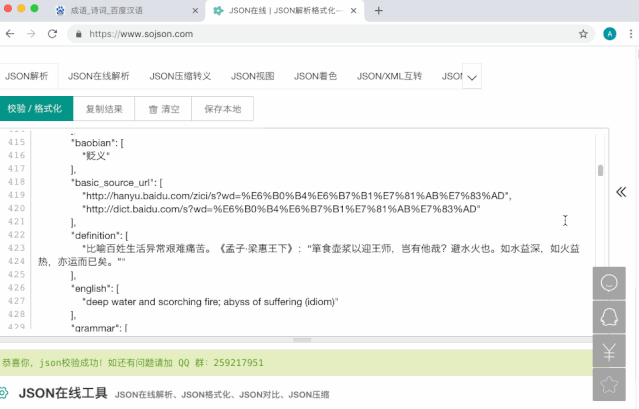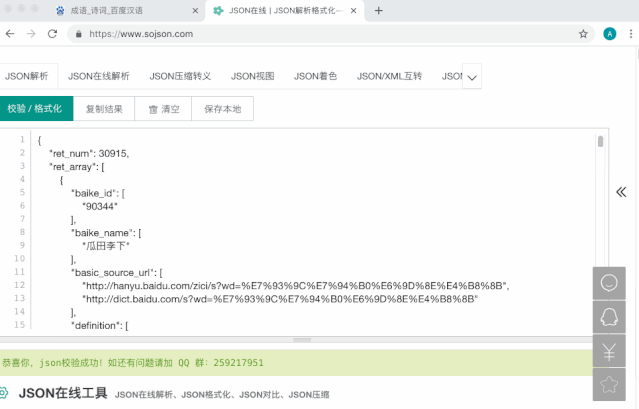
json数据解析,得知一页20个成语,自己所需要信息结构如下:
成语:ret_array[x].name
拼音:ret_array[x].pinyin
总页数:extra.total-page
2.2.3)、模拟请求
- [工具请求]-初步成功,可以编写脚本了
3、编写脚本(模拟请求)
1 # -*- coding: utf-8 -*-
2 """
3 @author: findyou
4 @contact: albert.peng@foxmail.com
5 @version: 1.0
6 @license: Apache Licence
7 @file: get_idiom_from_baidu.py
8 @time: 2018/10/21 20:35
9 """
10
11 __author__ = 'albert'
12 __version__ = '1.0'
13
14 import json
15 import sqlite3
16
17 import os
18 import requests
19 import socket
20 import time
21 import sys
22
23 # 总页数,直接手动,不去获取了
24 page_count = 1546
25
26 # 组装请求头
27 header = {
28 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
29 'Accept-Encoding': 'gzip, deflate, sdch',
30 'Accept-Language': 'zh-CN,zh;q=0.9',
31 'Connection': 'keep-alive',
32 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36'
33 }
34 # 默认数据库
35 db_filename = 'idiom.sqlite3'
36
37
38 def get_idiom_data(start_pagenum=1, end_pagenum=10, all=False):
39 '''
40 爬取百度成语数据,解析并保存到数据到数据库
41 :param start_pagenum: 默认从第1页开始
42 :param end_pagenum: 默认第10页结束
43 '''
44 global page_count, header
45
46 # 统计成语条数
47 idiom_count = 0
48 # 进度条
49 page_num = 0
50 get_url = 'https://hanyu.baidu.com/hanyu/ajax/search_list?wd=%E6%88%90%E8%AF%AD&from=poem&pn={}&_={}'.format(1, int(round(time.time() * 1000)))
51
52 # 获取全部成语
53 if all:
54 end_pagenum = page_count
55
56 for i in range(start_pagenum, end_pagenum + 1):
57 # 连接数据库
58 conn = sqlite3.connect(db_filename)
59 cursor = conn.cursor()
60
61 # 当前时间戳
62 # t = int(round(time.time() * 1000))
63 # 模拟请求获取json数据
64 try:
65 # 自动保存cookie
66 s = requests.session()
67 header['Referrer'] = get_url
68
69 # 百度 ajax 成语请求API
70 get_url = 'https://hanyu.baidu.com/hanyu/ajax/search_list?wd=%E6%88%90%E8%AF%AD&from=poem&pn={}&_={}'.format(i, int(round(time.time() * 1000)))
71
72 # 模拟请求
73 result = s.get(get_url, headers=header)
74 # 判断请求是否成功
75 if result.status_code == 200:
76 res = json.loads(result.text)
77 page_count = res['extra']['total-page']
78 # 得到返回的成语
79 for a in range(len(res['ret_array'])):
80 txt = res['ret_array'][a]
81 # 条数递增
82 idiom_count += 1
83
84 # 目前只需:成语、拼音
85 name = (get_vaule(txt, 'name'))[0].strip()
86 pinyin = (get_vaule(txt, 'pinyin'))[0].strip()
87 pinyin_list = pinyin.split(" ")
88
89 # 例句
90 # liju = get_vaule(txt, 'liju')[0]
91 # 出处
92 # tmp = get_vaule(txt, 'source')[0]
93 # if len(tmp) > 0:
94 # source = tmp.replace('"', '').replace("'", "").replace('\n', '')
95 # else:
96 # source = ''
97 # 同义词
98 # get_vaule(txt, 'synonym')
99 # tmp = get_vaule(txt, 'term_synonym')
100 # if len(tmp) > 0:
101 # synonym = tmp
102 # else:
103
104 # ID,成语,拼音,成语首字,尾字,首拼,尾拼
105 cursor.execute(
106 'insert into IDIOM (ID,NAME,PINYIN,NAMEF,NAMEL,PINYINF,PINYINL) values (NULL,"%s","%s","%s","%s","%s","%s")' %
107 (name, pinyin, name[0], name[len(name) - 1], pinyin_list[0], pinyin_list[len(pinyin_list) - 1]))
108 else:
109 print("获取数据失败:第"+i+"页")
110 except requests.exceptions.ConnectTimeout as e:
111 print("http请求超时!" + str(e))
112 except socket.timeout as e:
113 print("请求超时! " + str(e))
114 except socket.error as e:
115 print("请求错误!" + str(e))
116 finally:
117 # 每获取一页,保存一次
118 cursor.close()
119 conn.commit()
120 conn.close()
121 # 进度条
122 page_num += 1
123 view_bar(page_num, end_pagenum)
124 print('\n本次爬取[百度成语] : 第 ' + str(start_pagenum) + ' 至 ' +
125 str(end_pagenum) + ' 页,共计 ' + str(idiom_count) + ' 条')
126
127 def view_bar(num, total):
128 '''进度条'''
129 rate = num / total
130 rate_num = int(rate * 100)
131 # r = '\r %d%%' %(rate_num)
132 r = '\r[%s>] %d%%' % ('=' * rate_num, rate_num)
133 sys.stdout.write(r)
134 sys.stdout.flush
135
136
137 def get_vaule(idiom_dict, key_vaule):
138 if key_vaule in idiom_dict.keys():
139 return idiom_dict[key_vaule]
140 else:
141 return [' ']
142
143
144 def init_db(filename=db_filename):
145 '''
146 如果数据库不存在,自动在当前目录创建idiom.sqlite3:
147 '''
148 if not os.path.exists(filename):
149 conn = sqlite3.connect(filename)
150 # 创建一个Cursor:
151 cursor = conn.cursor()
152 # 建表ID 自增长key
153 cursor.execute(
154 'CREATE TABLE IDIOM (ID INTEGER PRIMARY KEY AUTOINCREMENT, NAME VARCHAR(100),NAMEF VARCHAR(10),NAMEL VARCHAR(10),\
155 PINYIN VARCHAR(100),PINYINF VARCHAR(10),PINYINL VARCHAR(10))')
156 # 关闭Cursor:
157 cursor.close()
158 # 提交事务:
159 conn.commit()
160 # 关闭Connection:
161 conn.close()
162
163
164 if __name__ == '__main__':
165 # 初始化数据库
166 init_db()
167
168 # 获取1-10页的数据,数据库只会往里一直加数据,未做去重,所以以下三个方式,用最后一种。
169 # get_idiom_data()
170
171 # 获取x-x页的数据
172 # get_idiom_data(start_pagenum=10,end_pagenum=30)
173
174 # 获取所有数据
175 get_idiom_data(all=True)
执行> python get_idiom_from_baidu.py
[====================================================================================================>] 100%
本次爬取[百度成语] : 第 1 至 1546 页,共计 30875 条
4、存在的问题
1、本脚本没有应对反爬虫机制(但实测不需要)
简单方案:请求头收集一堆,list随机取值
完整一点:代理IP+请求头list
2、保存数据较少,需要完整的成语数据
解析你想要的数据:第88行 -- 102行间
数据库增加你想要的字段:第154行 -- 155行
增加要保存的数据:第106行 -- 107行
3、成语数据不全
再爬其他成语库补充
4、单线程,速度慢
自已解决一下
三、自动化测试(接口层)
1、成语接龙游戏
正接,即接的成语的前一个字和问的成语的最后一个字一致(同字或同音都可),目前【琥珀】只支持正接中的尾首同字
2、自动化简单方案
识别【琥珀】说的成语,判断是否成语
如是成语,取其【尾字】,在数据库中获取【首字】一样的成语列表,随机给出一个成语继续。
不是成语,记录
说明:所以第二部分爬取成语只需保存数据:成语,首字,尾字
3、测试结果
正常用例-自动测试结果:

4、问题
1、如何做语音自动化方案?
其实主要测试逻辑一样,只需要多解决自动化用例TTS播报,被测的ASR(或文本)获取。
2、这自动化只是一个简单的功能测试,无法达到智能测试的效果?
对的,此方案仅覆盖的是成语的正确性;
趣味性、情感化等回复的语料,可人工标注或者其他方案。

喜欢请关注,有用请转发~
升职、加薪、无漏测-点“在看”










)









