
来源:机器之心报道
编辑:小舟、蛋酱
AI写文章还是得模仿人类的创作方法。
在今天的人工智能领域,AI 写作神器层出不穷,技术和产品可谓日新月异。
如果说 OpenAI 两年前发布的 GPT-3 在文笔上还稍欠火候,那么前段时间的 ChatGPT 的生成结果可以算是「文笔华丽、情节饱满、逻辑自洽兼而有之」。
有人说,AI 要是动起笔来,那真是没人类什么事了。
但不管是人类还是 AI,一旦把「字数要求」提高,文章就会变得更难「驾驭」。
近日,华人 AI 研究科学家田渊栋和其他几位研究者最近一起发布了一个新的语言模型——Re^3,这项研究也入选了 EMNLP 2022。

论文链接:https://arxiv.org/pdf/2210.06774.pdf
田渊栋曾在知乎上介绍这个模型:
Re^3 的想法极为简单,通过设计 prompt 让它生成一致性强的故事,完全不需要微调大模型。我们跳出语言模型的逐词生成的线性逻辑,改用层次化生成方式:先在 Plan 阶段生成故事角色,角色的各种属性和大纲,然后在 Draft 阶段给定故事大纲和角色,反复生成具体的段落,这些具体段落由 Rewrite 阶段筛选,挑出与前一段落高度相关的生成段落,而丢弃关系不大的(这需要训练一个小模型),最后在 Edit 阶段修正一些明显的事实错误。
方法介绍
Re^3 的思路是通过递归 Reprompt 和调整生成更长的故事,这更符合人类作家的创作过程。Re^3 将人类写作过程分解为规划、草稿、改写和编辑 4 个模块。
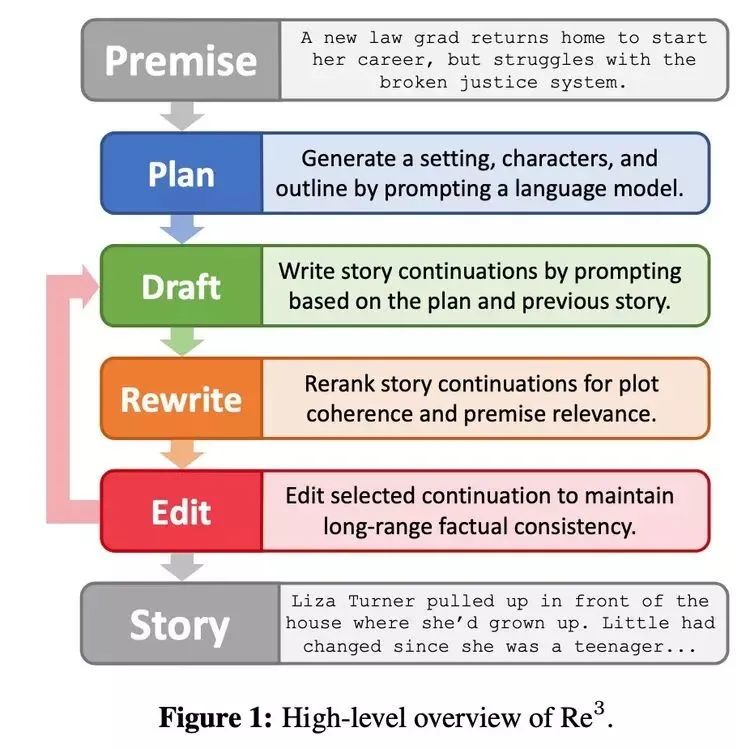
规划(Plan)模块
如下图 2 所示,规划模块会将故事前提(Premise)扩展为背景、人物角色和故事大纲。首先,背景是故事前提简单的一句话扩展,使用 GPT3-Instruct-175B (Ouyang et al.,2022) 获得;然后,GPT3-Instruct175B 再生成角色名称,并根据前提和背景生成角色描述;最后,该方法 prompt GPT3-Instruct175B,以编写故事大纲。规划模块中的组件是通过 prompt 自己生成的,将被反复使用。

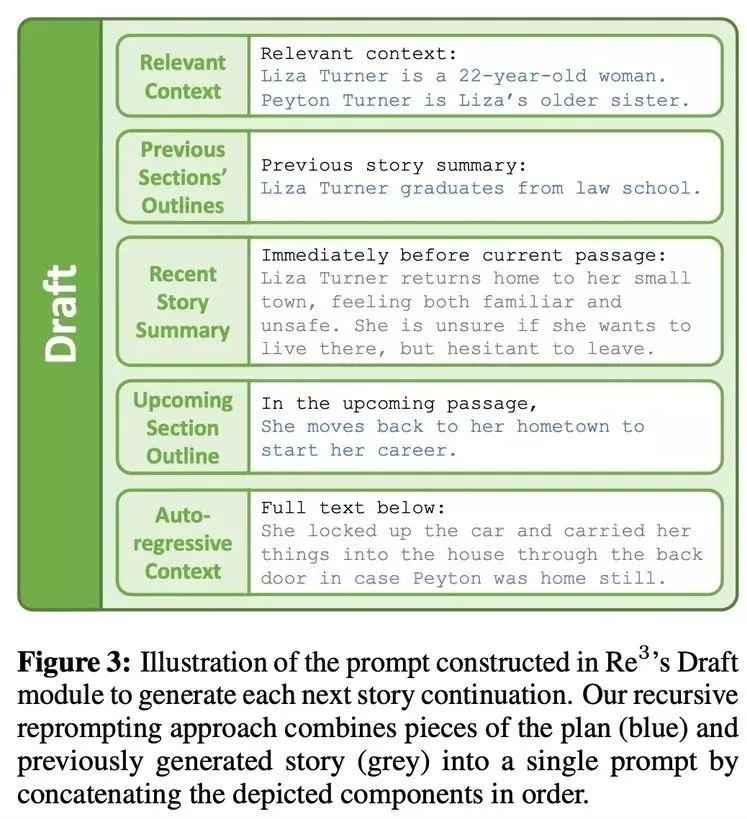
草稿(Draft)模块
针对规划模块得到的每一条大纲,草稿模块会继续生成几个故事段落。每个段落都是从结构化 prompt 生成的固定长度续写,结构化 prompt 由递归 reprompt 形成,草稿模块如下图 3 所示。
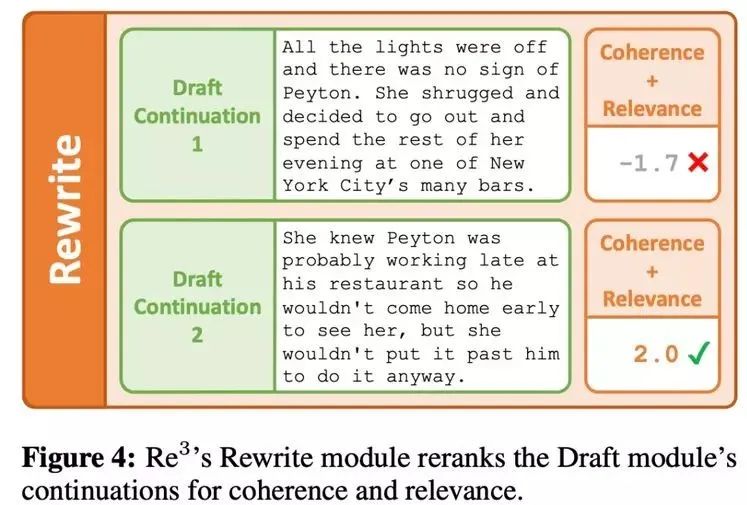
改写(Rewrite)模块
生成器的第一个输出通常是低质量的,就像人们完成的初稿,二稿可能需要在反馈的基础上改写一篇文章。
改写模块通过根据与先前段落的连贯性和与当前大纲点的相关性对草稿模块输出重新排序来模拟改写过程,如下图 4 所示。
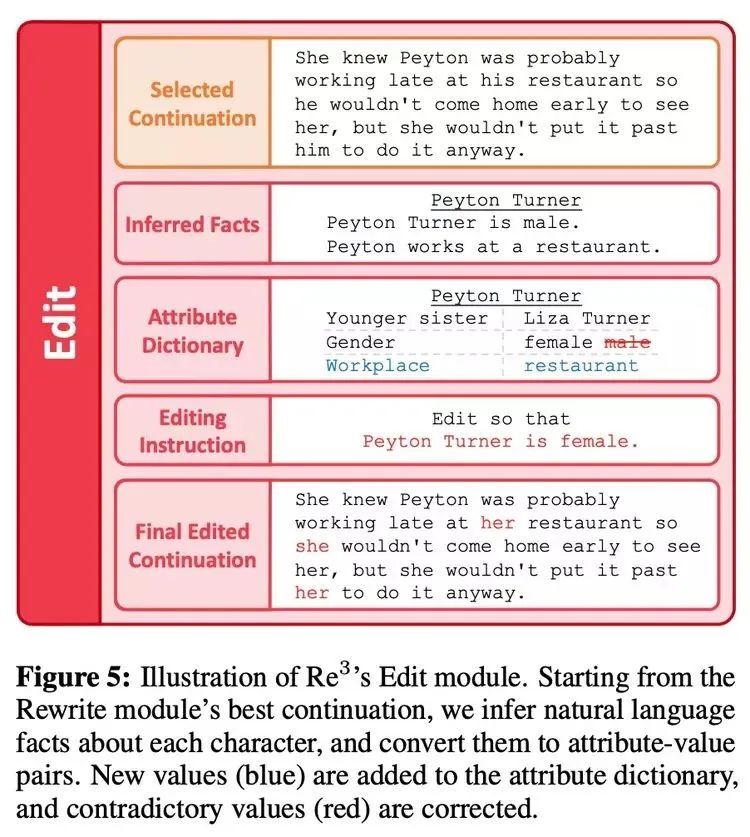
编辑(Edit)模块
与大幅改写不同的是,编辑模块是对通过规划、草稿和改写模块生成的段落的局部编辑,进一步完善生成内容。具体来说,目标是消除长序列的事实不一致。当人们在校对时发现一个小的事实不连续,可能只是简单地编辑一下有问题的细节,而不是对高层次的文章规划进行重大修改或进行实质性的改写。编辑模块通过两个步骤来模仿人类创作的这个过程:检测事实的不一致,并对其进行纠正,如下图 5 所示。
评估
在评估环节,研究者将任务设定为在一个简短的初始前情下生成一个故事。由于「故事」很难用基于规则的方式来定义,研究者没有对可接受的输出施加任何基于规则的约束,而是通过几个人为注释的指标来评估。为了生成初始前提,研究者用 GPT3-Instruct-175B 进行了 prompt,以获得 100 个不同的前情。
Baseline
由于先前的方法与 Re^3 相比更侧重于短故事,所以很难直接比较。于是研究者使用了以下两个基于 GPT3-175B 的基线:
1. ROLLING,通过 GPT3-175B 一次生成 256 个 token,使用前情和所有先前生成的故事文本作为 prompt,如果超过 768 个 token,则左截断 prompt。因此,「滚动窗口」最大上下文长度是 1024,与 RE^3 中使用的最大上下文长度相同。在生成了 3072 个 token 后,研究者使用了与 RE^3 相同的故事结束机制。
2. ROLLING-FT,与 ROLLING 相同,只是 GPT3-175B 首先会对 WritingPrompts 故事中的几百个段落进行微调,这些段落至少有 3000 个 token。
指标
研究者使用的几个评估指标包括:
1、有趣。对读者来说是有趣的。
2、连贯性。情节连贯。
3、相关性。忠实于最初的前情。
4、类人。被判断为是人类写的。
此外,研究者还追踪了生成的故事有多少次出现以下几方面的写作问题:
1、叙事。叙述或风格上的令人震惊的变化。
2、不一致。与事实不符或包含非常奇怪的细节。
3、混乱。令人困惑或难以理解。
4、重复性。高度的重复性。
5、不流畅。频繁的语法错误。
结果
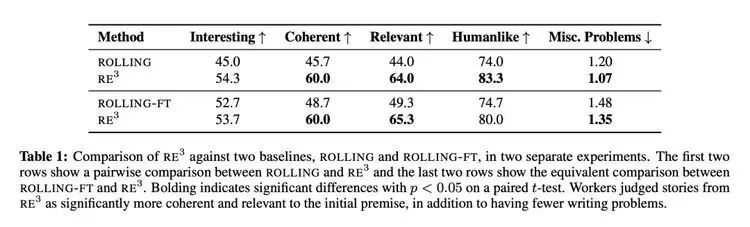
如表 1 所示,Re^3 在根据预期前情写一个较长的故事方面非常有效,同时能保持连贯的总体情节,验证了研究者受人类写作过程启发而做出的设计选择,以及递归 reprompting 生成方法。与 ROLLING 和 ROLLING-FT 相比,Re^3 在连贯性和相关性方面都有明显提高。注释者还将 Re^3 的故事标记为「具有明显较少的冗杂写作问题」。
Re^3 表现出了绝对意义上的强大性能:注释者认为在两次对比中,Re^3 的故事分别有 83.3% 和 80.0% 是由人类写的。表 2 显示了 Re^3 的一个经过大量删节的故事实例,可以看出很强的连贯性和前情相关性:

尽管如此,研究者仍从质量上观察到 Re^3 仍有很大的改进空间。
表 3 中显示了两个共同的问题。首先,尽管 Re^3 几乎总是在某种程度上遵循故事前情,但与基线故事不同,它们可能无法捕捉到前提的所有部分,也可能无法遵循规划模块生成的部分大纲(例如,表 3 中前情和大纲的第一部分)。其次,由于改写模块,特别是编辑模块的失败,仍然有一些混乱的段落或矛盾的语句:例如,在表 3 中,人物 Jaxon 在某些地方有一个矛盾的身份。

不过,与滚动窗口方法(rolling window)不同,Re^3 的规划方法能够「自我纠正」,回到最初的情节。表 3 中故事的后半部分说明了这种能力。
分析
消融实验
研究者探讨了 Re^3 的各个模块的相对贡献:规划、草稿、改写和编辑,并依次对每个模块进行消融实验。Draft 模块除外,因为尚不清楚没有它的话系统会如何运行。
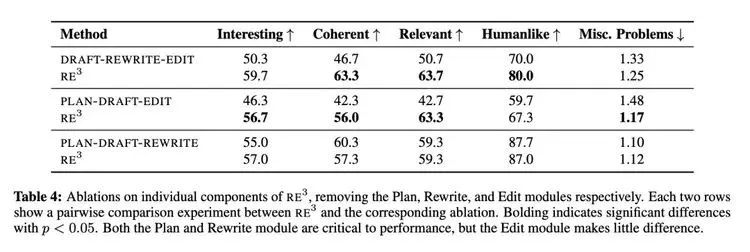
表 4 显示,模仿人类规划和改写过程的「规划」和「改写」模块对整体情节的连贯性和前提的相关性至关重要。然而,「编辑」模块对这些指标的贡献很小。研究者还从质量上观察到,在 Re^3 的最终故事中仍然存在许多连贯性问题,这些问题没有被编辑模块所解决,但这些问题可以由一个细心的人类编辑来解决。
「编辑」模块的进一步分析
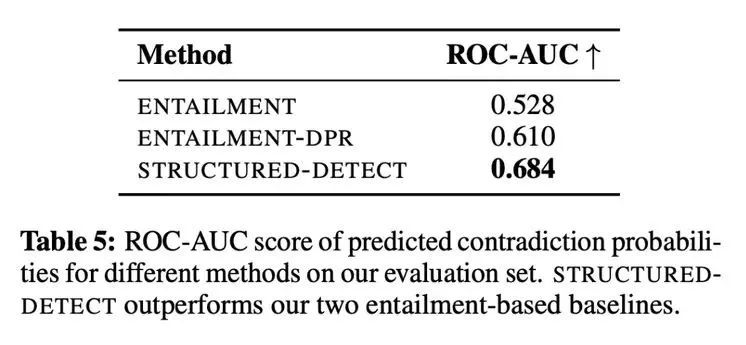
研究者使用了一个可控的环境,以研究「编辑」模块是否至少能检测到基于角色的事实不一致。检测子系统称为 STRUCTURED-DETECT,避免与整个编辑模块混为一谈。
如表 5 所示,当检测基于角色的不一致时,根据标准的 ROC-AUC 分类指标,STRUCTUREDDETECT 优于两个基线。ENTAILMENT 系统的 ROC-AUC 得分勉强优于偶然表现(0.5),突出了核心挑战,即检测系统必须是压倒性的精确。此外,STRUCTURED-DETECT 的设计是为了扩展到较长的段落。研究者假设,与基线相比,性能差距会在有较长输入的评估中扩大。
即使在这种简化的环境中,所有系统的绝对性能仍然很低。此外,许多生成的完整故事包含非角色的不一致,例如背景与当前场景的不一致。虽然研究者没有正式分析 GPT-3 编辑 API 在检测到不一致之处后的修正能力,但也观察到它可以修正孤立的细节,而在处理较大的变化时会很吃力。
综上所述,来自检测和修正子系统的复合错误使得本研究目前的编辑模块很难在数千字的范围内有效地改善事实的一致性,而不同时引入不必要的变化。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”



)










》)

)


算法真如用起来那么简单?)
